A Closer Look at the Self-Verification Abilities of Large Language Models in Logical Reasoning
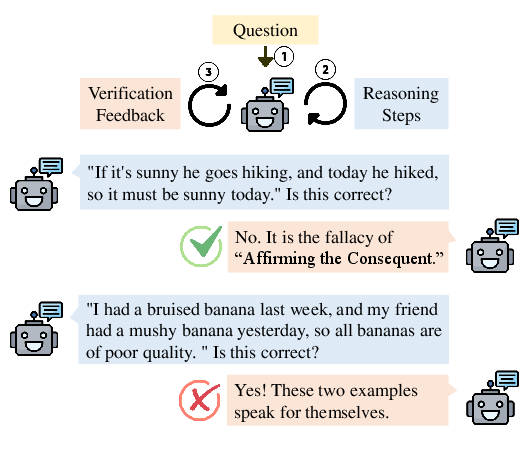
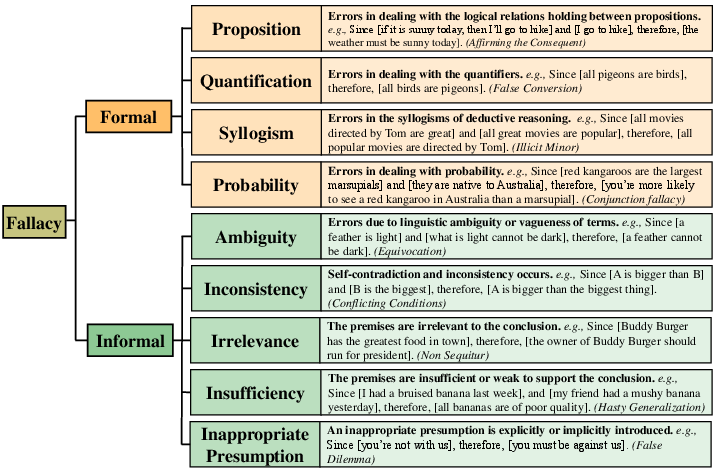
Abstract: Logical reasoning has been an ongoing pursuit in the field of AI. Despite significant advancements made by LLMs, they still struggle with complex logical reasoning problems. To enhance reasoning performance, one promising direction is scalable oversight, which requires LLMs to identify their own errors and then improve by themselves. Various self-verification methods have been proposed in pursuit of this goal. Nevertheless, whether existing models understand their own errors well is still under investigation. In this paper, we take a closer look at the self-verification abilities of LLMs in the context of logical reasoning, focusing on their ability to identify logical fallacies accurately. We introduce a dataset, FALLACIES, containing 232 types of reasoning fallacies categorized in a hierarchical taxonomy. By conducting exhaustive experiments on FALLACIES, we obtain comprehensive and detailed analyses of a series of models on their verification abilities. Our main findings suggest that existing LLMs could struggle to identify fallacious reasoning steps accurately and may fall short of guaranteeing the validity of self-verification methods. Drawing from these observations, we offer suggestions for future research and practical applications of self-verification methods.
- Falcon-40B: an open large language model with state-of-the-art performance.
- Konstantine Arkoudas. 2023. GPT-4 can’t reason. CoRR, abs/2308.03762.
- Qwen technical report. CoRR, abs/2309.16609.
- Constitutional AI: harmlessness from AI feedback. CoRR, abs/2212.08073.
- Bo Bennett. 2012. Logically fallacious: the ultimate collection of over 300 logical fallacies (Academic Edition). eBookIt. com.
- Measuring progress on scalable oversight for large language models. CoRR, abs/2211.03540.
- Improving code generation by training with natural language feedback. CoRR, abs/2303.16749.
- Iterative translation refinement with large language models. CoRR, abs/2306.03856.
- Factool: Factuality detection in generative AI - A tool augmented framework for multi-task and multi-domain scenarios. CoRR, abs/2307.13528.
- A survey of chain of thought reasoning: Advances, frontiers and future. arXiv preprint arXiv:2309.15402.
- Scaling instruction-finetuned language models. CoRR, abs/2210.11416.
- Transformers as soft reasoners over language. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI 2020, pages 3882–3890. ijcai.org.
- Selection-inference: Exploiting large language models for interpretable logical reasoning. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.
- Recognizing Textual Entailment: Models and Applications. Synthesis Lectures on Human Language Technologies. Morgan & Claypool Publishers.
- Explaining answers with entailment trees. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, pages 7358–7370. Association for Computational Linguistics.
- GLM: general language model pretraining with autoregressive blank infilling. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, pages 320–335. Association for Computational Linguistics.
- Bridging the gap: A survey on integrating (human) feedback for natural language generation. CoRR, abs/2305.00955.
- James Fieser and Bradley Dowden. 2011. Internet encyclopedia of philosophy: Fallacies.
- CRITIC: large language models can self-correct with tool-interactive critiquing. CoRR, abs/2305.11738.
- Before name-calling: Dynamics and triggers of ad hominem fallacies in web argumentation. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 386–396, New Orleans, Louisiana. Association for Computational Linguistics.
- Rethinking with retrieval: Faithful large language model inference. CoRR, abs/2301.00303.
- METGEN: A module-based entailment tree generation framework for answer explanation. In Findings of the Association for Computational Linguistics: NAACL 2022, Seattle, WA, United States, July 10-15, 2022, pages 1887–1905. Association for Computational Linguistics.
- Faithful question answering with monte-carlo planning. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 3944–3965. Association for Computational Linguistics.
- Large language models can self-improve. CoRR, abs/2210.11610.
- Large language models cannot self-correct reasoning yet. arXiv preprint arXiv:2310.01798.
- William Stanley Jevons. 1872. Elementary lessons in logic: Deductive and inductive: With copious questions and examples, and a vocabulary of logical terms. Macmillan.
- Merit: Meta-path guided contrastive learning for logical reasoning. In Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, May 22-27, 2022, pages 3496–3509. Association for Computational Linguistics.
- Logical fallacy detection. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 7180–7198, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Maieutic prompting: Logically consistent reasoning with recursive explanations. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, pages 1266–1279. Association for Computational Linguistics.
- Large language models are zero-shot reasoners. In NeurIPS.
- Measuring faithfulness in chain-of-thought reasoning. CoRR, abs/2307.13702.
- Joe YF Lau. 2011. An introduction to critical thinking and creativity: Think more, think better. John Wiley & Sons.
- Jan Leike and Ilya Sutskever. 2023. Introducing superalignment. OpenAI.
- Let’s verify step by step. CoRR, abs/2305.20050.
- Deductive verification of chain-of-thought reasoning. CoRR, abs/2306.03872.
- Evaluating the logical reasoning ability of chatgpt and GPT-4. CoRR, abs/2304.03439.
- Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv., 55(9):195:1–195:35.
- Self-refine: Iterative refinement with self-feedback. CoRR, abs/2303.17651.
- PD Magnus. 2005. forall x: An introduction to formal logic.
- John McCarthy. 1989. Artificial intelligence, logic and formalizing common sense. Philosophical Logic and Artificial Intelligence, pages 161–190.
- Selfcheck: Using llms to zero-shot check their own step-by-step reasoning. CoRR, abs/2308.00436.
- LEVER: learning to verify language-to-code generation with execution. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 of Proceedings of Machine Learning Research, pages 26106–26128. PMLR.
- OpenAI. 2023. GPT-4 technical report. CoRR, abs/2303.08774.
- Training language models to follow instructions with human feedback. In NeurIPS.
- Logic-lm: Empowering large language models with symbolic solvers for faithful logical reasoning. CoRR, abs/2305.12295.
- How susceptible are llms to logical fallacies? CoRR, abs/2308.09853.
- Gpt-3.5 turbo fine-tuning and api updates. https://openai.com/blog/gpt-3-5-turbo-fine-tuning-and-api-updates.
- Logigan: Learning logical reasoning via adversarial pre-training. In NeurIPS.
- Nicholas Rescher and Morton L. Schagrin. 2023. Fallacy. Encyclopedia Britannica.
- Training language models with language feedback at scale. CoRR, abs/2303.16755.
- Reflexion: Language agents with verbal reinforcement learning.
- Conceptnet 5.5: An open multilingual graph of general knowledge. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, February 4-9, 2017, San Francisco, California, USA, pages 4444–4451. AAAI Press.
- Christian Stab and Iryna Gurevych. 2017. Recognizing insufficiently supported arguments in argumentative essays. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, pages 980–990, Valencia, Spain. Association for Computational Linguistics.
- Proofwriter: Generating implications, proofs, and abductive statements over natural language. In Findings of the Association for Computational Linguistics: ACL/IJCNLP 2021, Online Event, August 1-6, 2021, volume ACL/IJCNLP 2021 of Findings of ACL, pages 3621–3634. Association for Computational Linguistics.
- InternLM Team. 2023. Internlm: A multilingual language model with progressively enhanced capabilities. https://github.com/InternLM/InternLM.
- Llama 2: Open foundation and fine-tuned chat models. CoRR, abs/2307.09288.
- Can large language models really improve by self-critiquing their own plans? CoRR, abs/2310.08118.
- Self-instruct: Aligning language models with self-generated instructions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 13484–13508. Association for Computational Linguistics.
- Emergent abilities of large language models. Trans. Mach. Learn. Res., 2022.
- Chain-of-thought prompting elicits reasoning in large language models. In NeurIPS.
- Large language models are reasoners with self-verification. CoRR, abs/2212.09561.
- Decomposition enhances reasoning via self-evaluation guided decoding. CoRR, abs/2305.00633.
- Wizardlm: Empowering large language models to follow complex instructions. CoRR, abs/2304.12244.
- Baichuan 2: Open large-scale language models. CoRR, abs/2309.10305.
- Generating natural language proofs with verifier-guided search. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, pages 89–105. Association for Computational Linguistics.
- Logical reasoning over natural language as knowledge representation: A survey. CoRR, abs/2303.12023.
- Tree of thoughts: Deliberate problem solving with large language models. CoRR, abs/2305.10601.
- Nature language reasoning, A survey. CoRR, abs/2303.14725.
- Star: Bootstrapping reasoning with reasoning. In NeurIPS.
- Judging llm-as-a-judge with mt-bench and chatbot arena. CoRR, abs/2306.05685.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.