- The paper introduces Multi-LogiEval, a comprehensive QA dataset assessing LLMs' multi-step logical reasoning across propositional, first-order, and non-monotonic logic.
- It employs a two-stage data generation process, combining rule composition and natural language instance creation to achieve reasoning depths from 1 to 5.
- Experimental results reveal that LLM accuracy drops with increased depth in monotonic logic while improving in non-monotonic contexts, highlighting error propagation challenges.
Multi-LogiEval: Evaluating Multi-Step Logical Reasoning in LLMs
The paper "Multi-LogiEval: Towards Evaluating Multi-Step Logical Reasoning Ability of LLMs" (2406.17169) introduces Multi-LogiEval, a QA dataset designed to evaluate the multi-step logical reasoning capabilities of LLMs across propositional logic (PL), first-order logic (FOL), and non-monotonic (NM) reasoning. It addresses limitations in existing benchmarks by incorporating a variety of inference rules, depths, and logic types, including non-monotonic reasoning, which aligns closely with human-like reasoning. The paper presents an analysis of LLMs' performance on the dataset, revealing a decline in accuracy as reasoning depth increases.
Dataset Construction and Logical Framework
The Multi-LogiEval dataset comprises ∼1.6k high-quality instances, covering 33 inference rules and reasoning patterns, and over 60 complex combinations with depths ranging from 1 to 5. The construction methodology involves two stages: rule combination generation and data instance generation.
For monotonic logic (PL and FOL), the authors selected 14 distinct inference rules, shown in (Table \ref{tab:classical_inference_rules}). These rules were chosen based on their relevance to human intuition and their ability to generate meaningful conclusions without leading to infinite reasoning chains. Combinations were systematically generated by iteratively assessing the alignment of rule conclusions with the premises of other rules. Natural language data instances were then created using Claude-2, prompted with a few-shot setting and a schema including rule definitions, formatting instructions, diversity guidelines, task definitions (context and question generation), and examples.
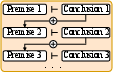
Figure 1: Process for combining multiple logical inference rules for PL and FOL, demonstrating the derivation of conclusions through sequential application of inference rules.
The process for combining multiple logical inference rules for PL and FOL is shown in (Figure 1). Premise 1 is the set of premises for the first inference rule, leading to Conclusion 1. Conclusion 1 and Premise 2 derive Conclusion 2, and so on.
Data generation for non-monotonic reasoning utilized eight reasoning patterns defined in prior work, integrating NM with classical logic to achieve depths of 1 to 5. The rule combinations avoid overly long contexts while requiring reasoning up to depth-5.
Experimental Evaluation and Results
The study evaluated several LLMs, including GPT-4, ChatGPT, Gemini-Pro, Yi-34B, Orca-2-13B, and Mistral-7B, using zero-shot chain-of-thought (CoT) prompting. The task was formulated as a binary classification problem, where the models had to determine whether a given context logically entailed a conclusion presented in a question.
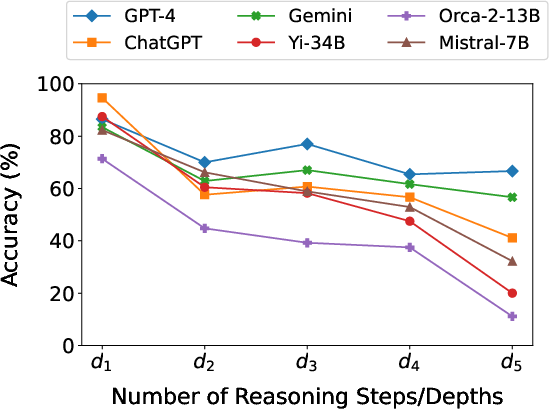
Figure 2: Performance (avg. accuracy across each depth for PL, FOL, and NM) of various LLMs on Multi-LogiEval, highlighting the trend of decreasing accuracy with increasing reasoning depth in PL and FOL.
The results, illustrated in (Figure 2), indicate a consistent performance decrease for PL and FOL as reasoning depth increases. For example, GPT-4, ChatGPT, and Gemini exhibit accuracy drops from ∼90% at depth 1 to ∼60% at depth 5 for PL. However, non-monotonic reasoning showed the opposite trend, with performance improving as depth increased. Larger open-source models demonstrated decreased performance.
A manual analysis of the reasoning chains revealed several key findings. The models often misinterpreted evidence, leading to incorrect conclusions. In PL and FOL, increasing context length improved accuracy in information mapping up to a certain point (depth 3), beyond which longer reasoning chains led to error propagation. ChatGPT tended to generate longer reasoning chains than GPT-4 and Gemini, but this did not necessarily correlate with better outcomes. In NM reasoning, the integration of basic classical rules with NM significantly enhanced model accuracy at higher depths. The generic rules in FOL contexts lead to deviations from the correct reasoning path.
Implications and Future Directions
The Multi-LogiEval benchmark highlights the challenges LLMs face in performing multi-step logical reasoning, even with relatively simple inference rules. The performance drop with increasing depth suggests that errors in early reasoning steps can propagate and compound, leading to incorrect conclusions.
The differing trends observed between monotonic and non-monotonic logic suggest that LLMs may benefit from the inclusion of non-monotonic reasoning patterns, which can provide supplementary evidence and improve contextual understanding. The finding that larger open-source models perform worse than smaller models indicates that model size alone is not a sufficient indicator of reasoning ability.
Future research directions include expanding Multi-LogiEval with more complex inference rules, logic types, and reasoning depths. Incorporating n-ary relations in FOL and exploring multilingual scenarios could further enhance the benchmark's comprehensiveness. Additionally, investigating methods to improve LLMs' ability to maintain accuracy over longer reasoning chains and to effectively utilize contextual information could lead to significant advances in logical reasoning capabilities.
Conclusion
The introduction of Multi-LogiEval provides a valuable tool for evaluating and improving the multi-step logical reasoning abilities of LLMs. The results demonstrate that while LLMs have made significant progress in natural language understanding, their ability to perform robust and accurate logical reasoning remains a challenge, particularly as the complexity of reasoning increases. The insights gained from this benchmark can guide future research towards developing more capable and reliable AI systems.

