- The paper presents a comprehensive evaluation of LLMs’ logical reasoning across deductive, inductive, abductive, and mixed-form tasks.
- It introduces a new content-neutral dataset, NeuLR, and employs fine-grained metrics including explanation correctness, completeness, and redundancy.
- Results highlight performance gaps, error sources in evidence selection, and differing reasoning behaviors among top LLMs.
Comprehensive Evaluation of Logical Reasoning in LLMs
The paper "Are LLMs Really Good Logical Reasoners? A Comprehensive Evaluation and Beyond" (2306.09841) presents a systematic evaluation of LLMs on logical reasoning tasks, covering deductive, inductive, abductive, and mixed-form reasoning settings. The authors conduct fine-grained analyses of LLM performance using both objective and subjective metrics, attributing errors to issues in evidence selection and reasoning processes. Additionally, the paper introduces a new content-neutral dataset (NeuLR) to mitigate knowledge bias in existing benchmarks, and proposes a comprehensive evaluation scheme based on six key properties: Correct, Rigorous, Self-aware, Active, Oriented, and No hallucination.
Experimental Setup
The study evaluates three representative LLMs: text-davinci-003, ChatGPT, and BARD, across fifteen datasets categorized into deductive, inductive, abductive, and mixed-form reasoning settings. The evaluation employs zero-shot, one-shot, and three-shot learning paradigms. Beyond accuracy, the authors introduce fine-grained metrics, including explanation correctness, completeness, and redundancy, to evaluate the reasoning process. Error analysis involves classifying failure cases based on evidence selection (wrong selection, hallucination) and reasoning process (no reasoning, perspective mistake, process mistake). The new dataset, NeuLR, comprises 3,000 content-neutral samples across deductive, inductive, and abductive reasoning types.
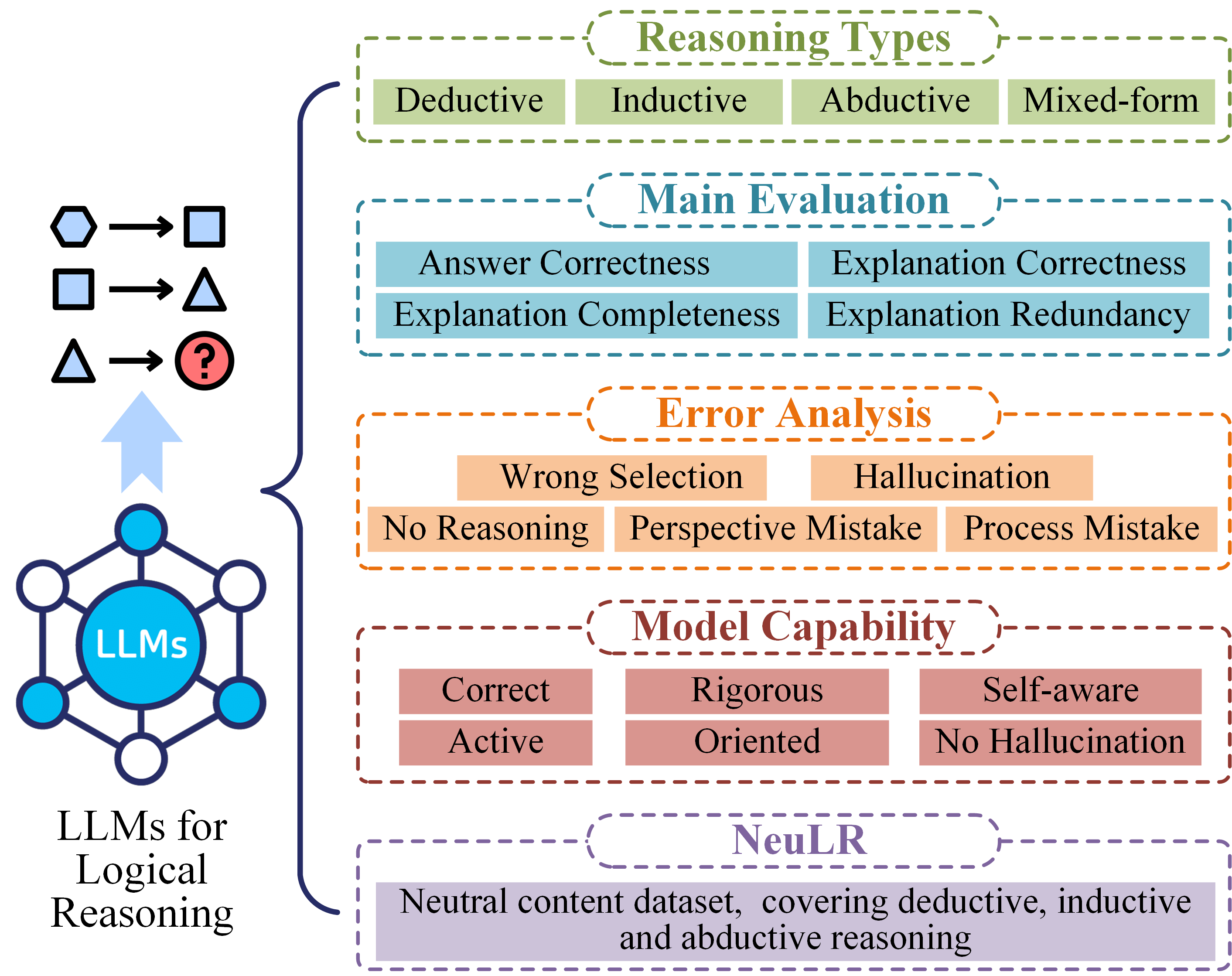
Figure 1: The overall architecture of the evaluation.
The paper's experiments reveal that LLMs generally underperform compared to state-of-the-art models specifically designed for logical reasoning. ChatGPT shows weaker performance in deductive and inductive settings compared to text-davinci-003 and BARD. BARD exhibits consistent superiority in deductive, inductive, and abductive settings, while ChatGPT performs better in mixed-form reasoning. LLMs perform best in deductive reasoning and struggle most with inductive reasoning. The paper suggests that this is because deductive and abductive reasoning align with typical NLP tasks, whereas inductive reasoning requires extracting high-level rules, which may be less common in training data.
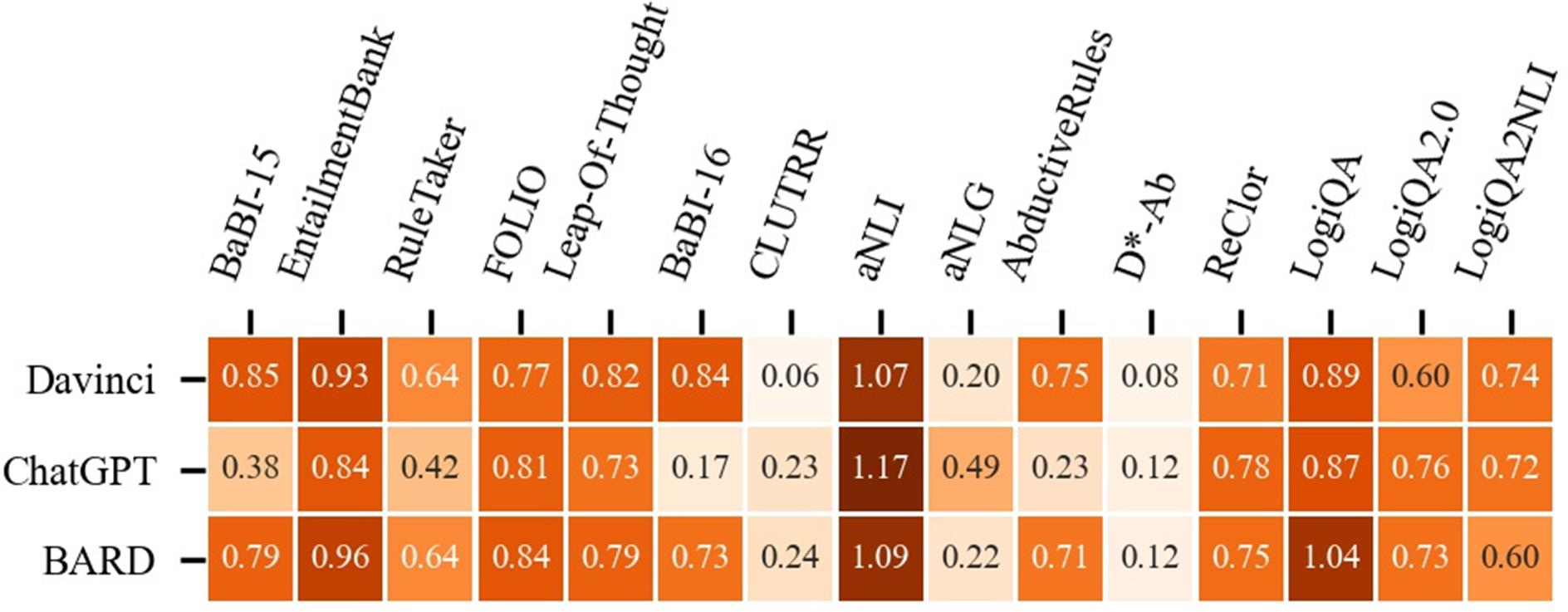
Figure 2: LLM performances on different datasets.
The study also finds that few-shot in-context learning (ICL) does not consistently improve performance on logical reasoning tasks, in contrast to its effectiveness on other NLP tasks. This suggests that the ability to leverage context for logical reasoning may be a unique challenge for LLMs.
Fine-Grained Evaluation
The authors performed fine-level evaluations to evaluate whether LLMs are rigorous and self-aware logical reasoners.
Rigor
The authors define rigorous reasoning as producing a correct answer along with a correct and complete explanation. The results show significant performance drops across all LLMs when requiring rigorous reasoning, with BARD showing the best capability in this regard. LLMs are strongest in rigorous abductive reasoning but weaker in deductive and inductive settings, suggesting that the backward reasoning mode of abductive reasoning encourages more complete explanations.
Self-Awareness
Self-awareness is measured by the redundancy of generated content, with less redundancy indicating greater self-awareness. Text-davinci-003 exhibits notable advantages in self-awareness, particularly in inductive, abductive, and mixed-form reasoning. LLMs tend to generate more redundant answers in generation tasks compared to classification tasks, and mixed-form reasoning exhibits fewer instances of redundancy.
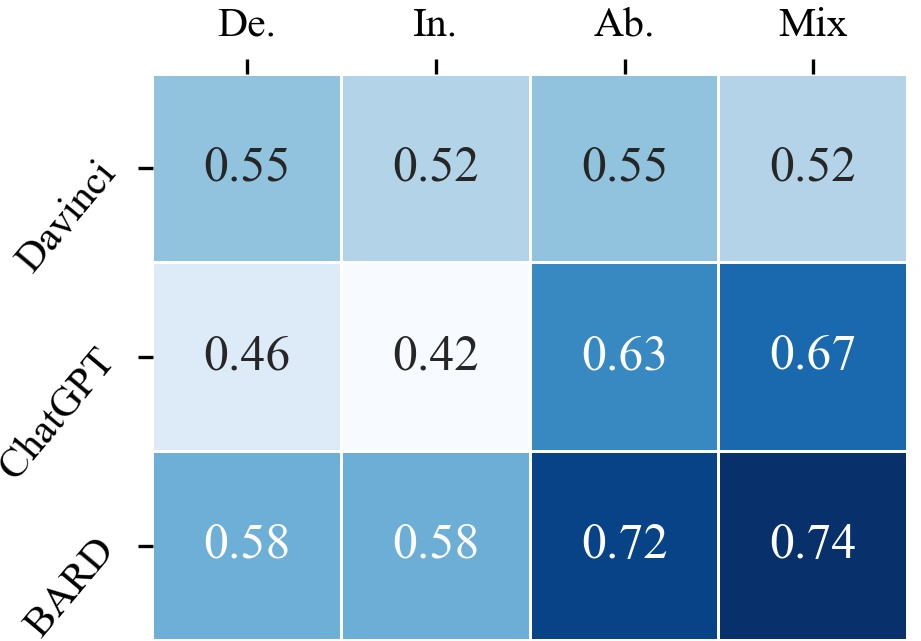
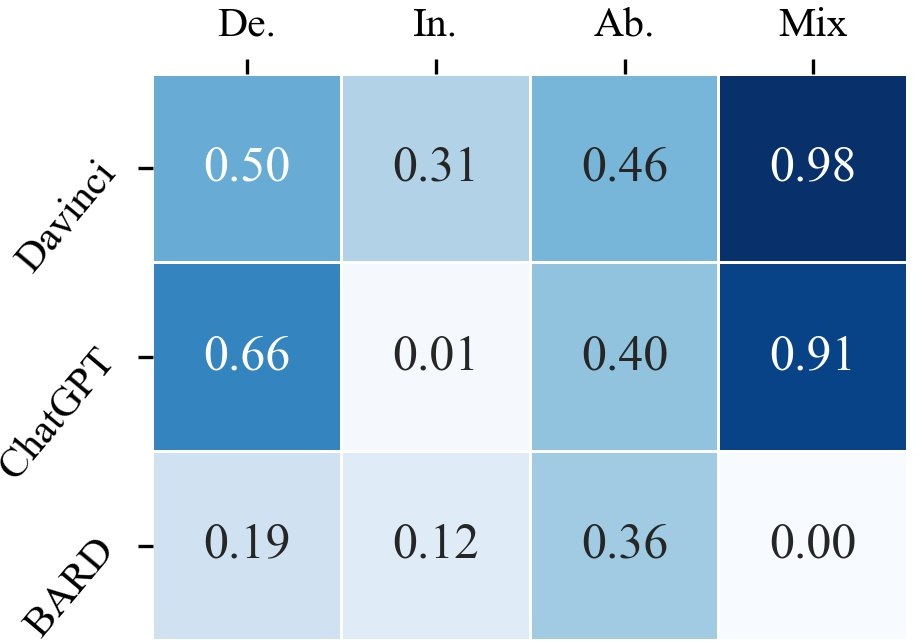
Figure 3: Heatmap visualization of rigor and self-awareness.
Error Analysis
Error analysis reveals that a significant portion of errors stem from incorrect evidence selection and perspective mistakes. Specifically, 33.26% of problematic cases involve failure to select the right answers for reasoning, and 27.46% suffer from hallucination. Perspective mistake accounts for 44.47% of reasoning errors, while process mistake covers 36.20%.
The authors also investigated whether LLMs are active logical reasoners, and whether LLMs are oriented logical reasoners. They defined active reasoning as fewer no reasoning errors, and oriented reasoning as the ability to identify the correct starting points and potential directions for reasoning.
Active Reasoning
BARD is found to be the most active logical reasoner, while ChatGPT is the laziest in deductive and inductive settings. LLMs exhibit more active reasoning in deductive tasks but tend to be lazier in abductive settings.
Oriented Reasoning
ChatGPT shows better-oriented capability in deductive and inductive tasks, while BARD performs well in abductive and mixed-form settings. This suggests that ChatGPT is more confident in its reasoning direction, while text-davinci-003 and BARD are more active but prone to starting from the wrong direction.
Hallucination
ChatGPT exhibits strong competitiveness in avoiding hallucinations, while BARD displays poor performance. On average, LLMs induce hallucination in 27.46% of failure cases, with deductive reasoning tasks being more prone to hallucinations.
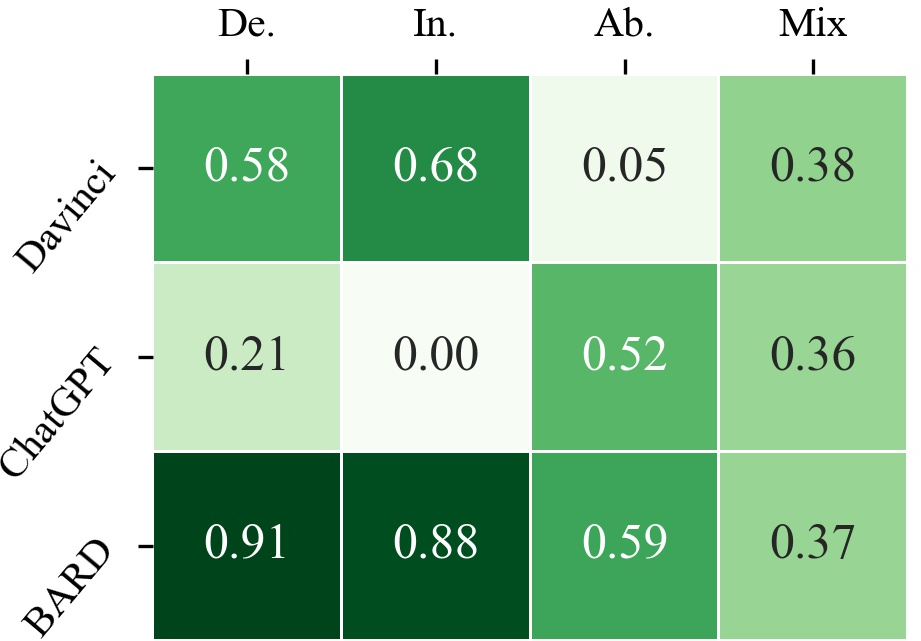
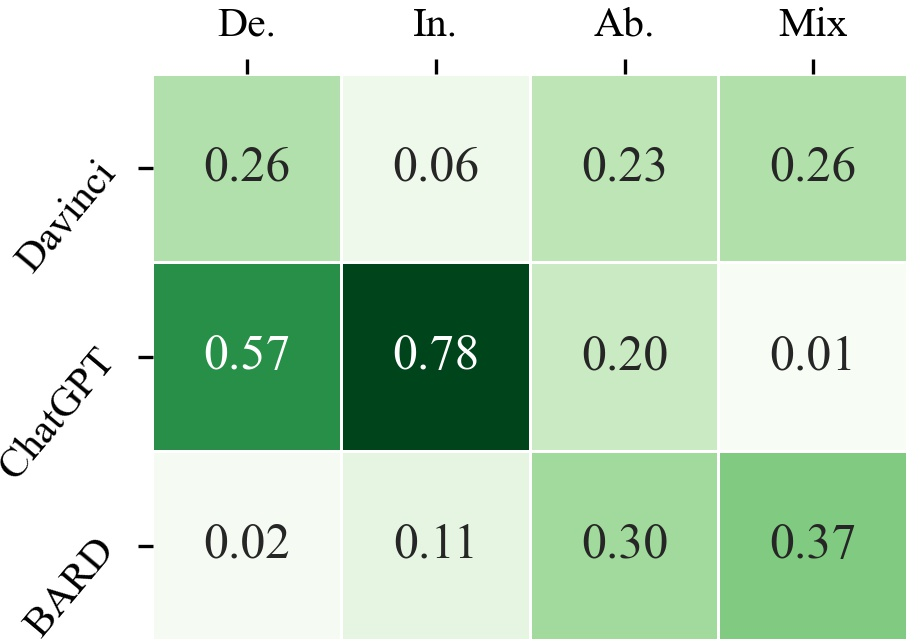
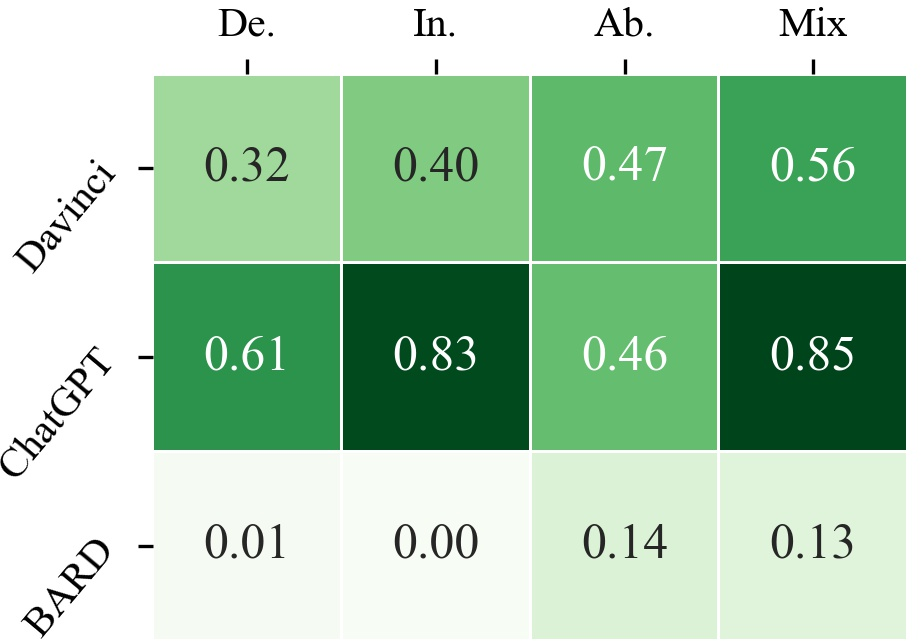
Figure 4: Heatmap results for the activity, orientation and no-hallucination of LLMs.
The paper explores the impact of the number of statements and reasoning hops on LLM performance. The results suggest that LLMs perform better with fewer input statements, and their performance tends to decline as the number of tokens increases. Additionally, performance decreases with an increasing number of reasoning hops, particularly affecting the rigor of LLM reasoning.
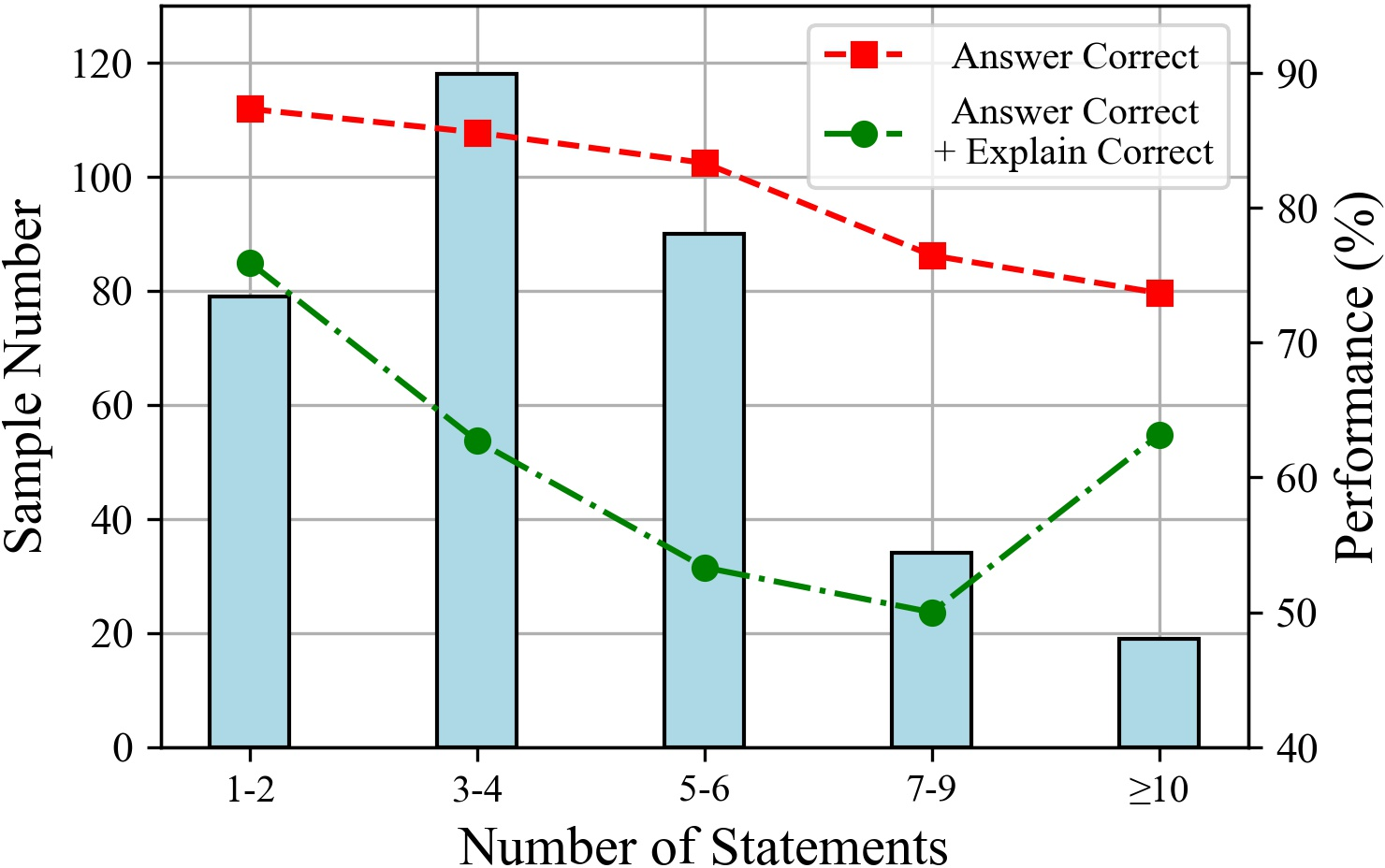

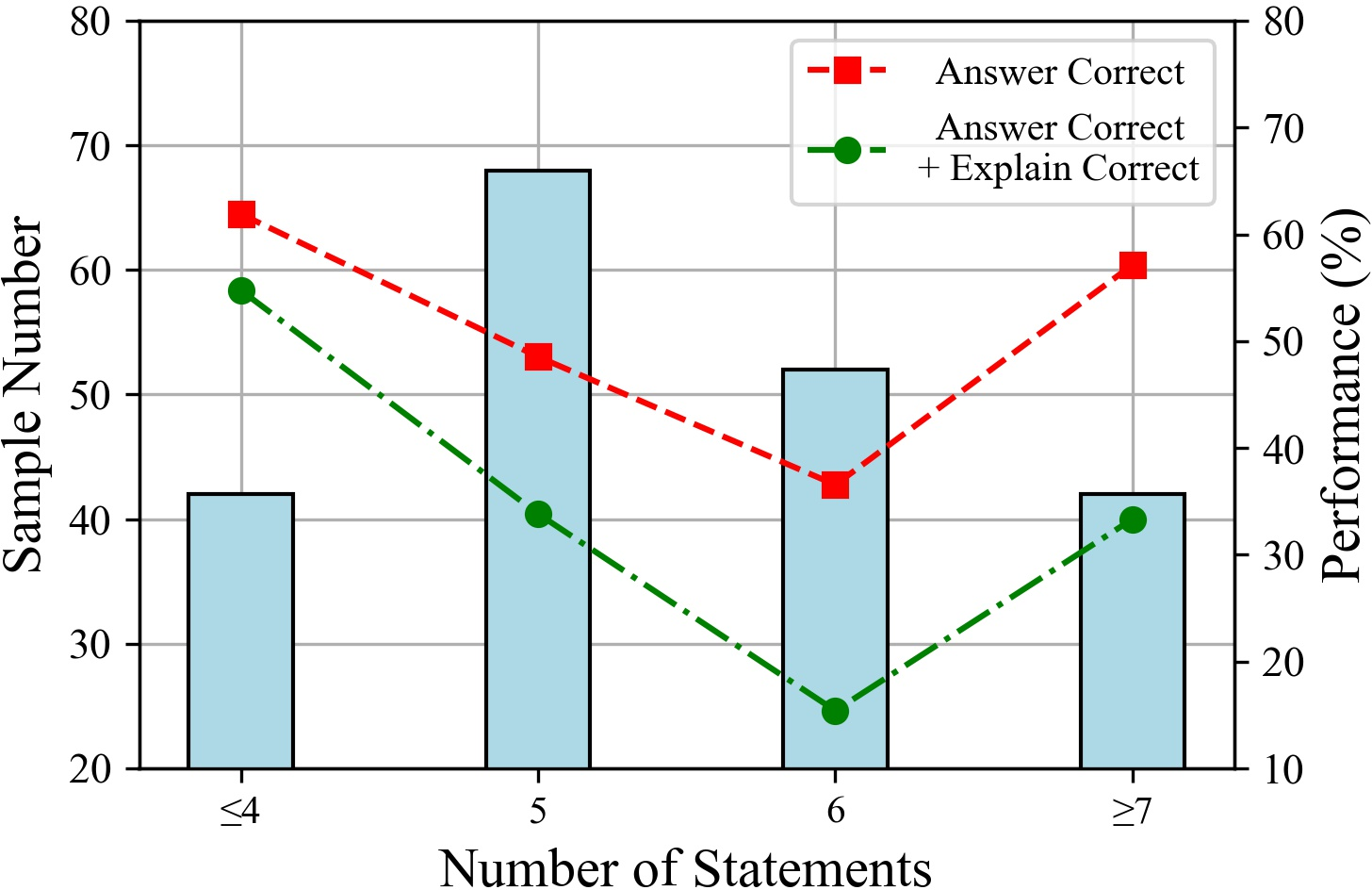
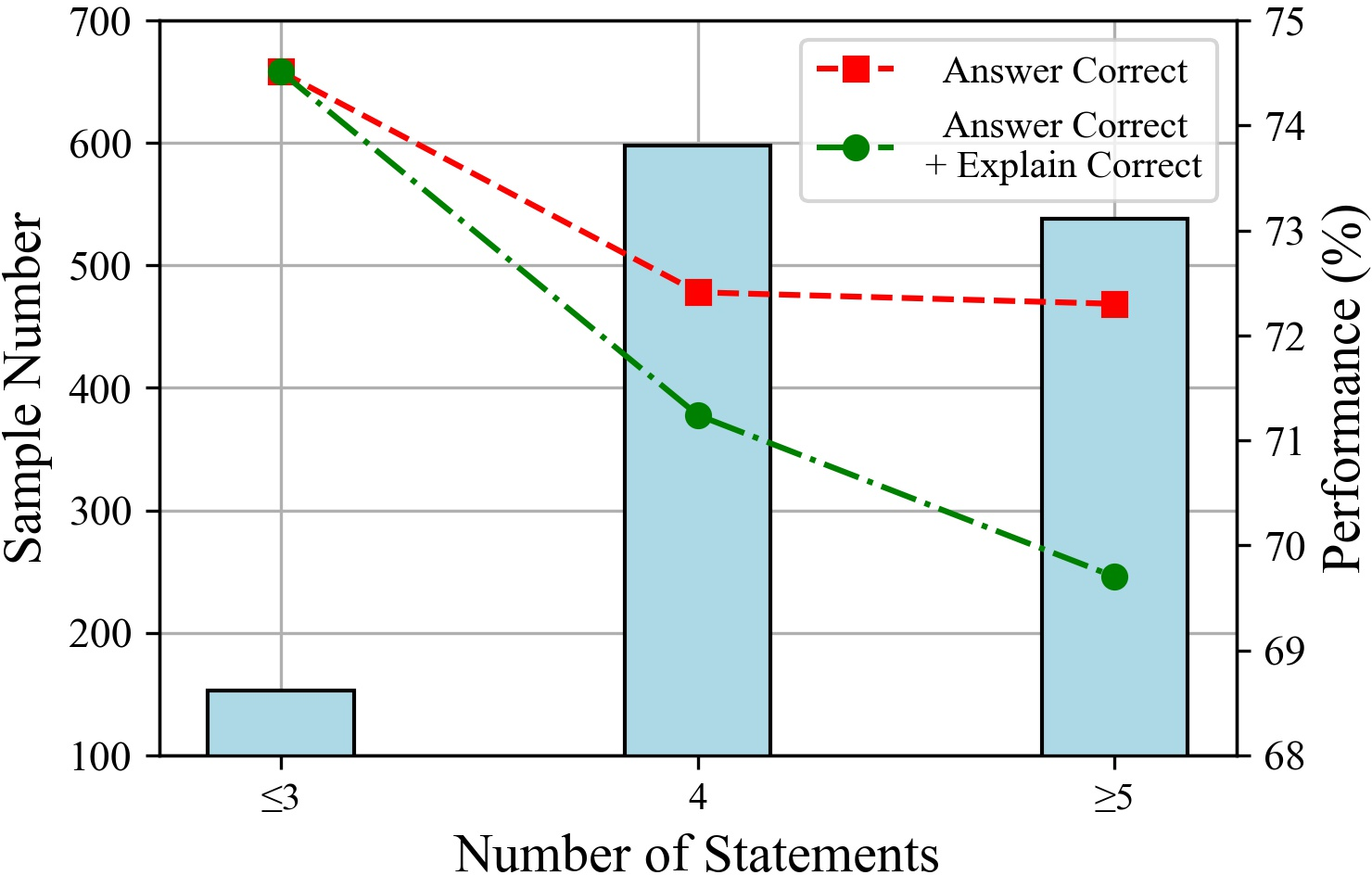

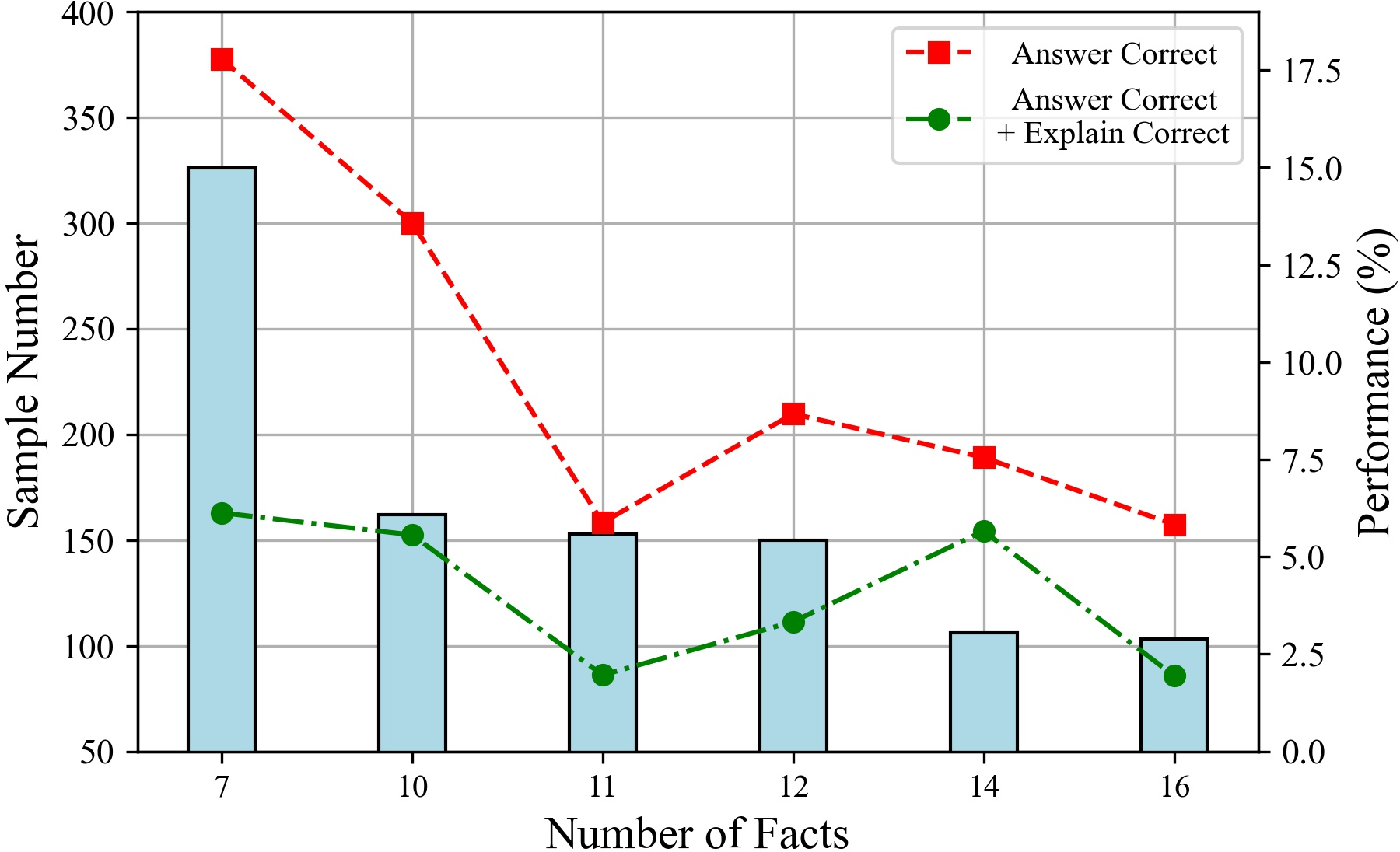
Figure 5: The LLM performances with different numbers of statements.
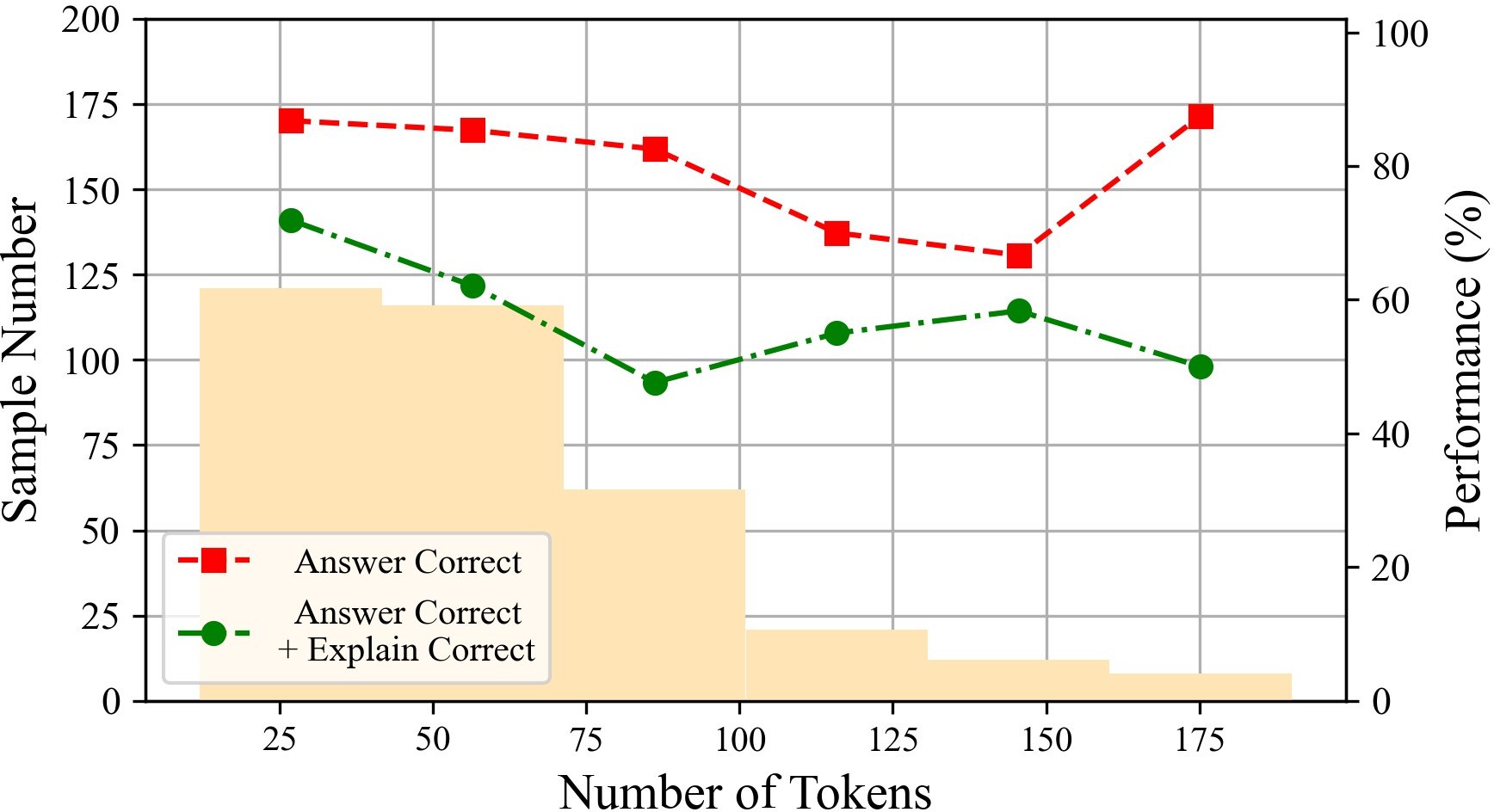
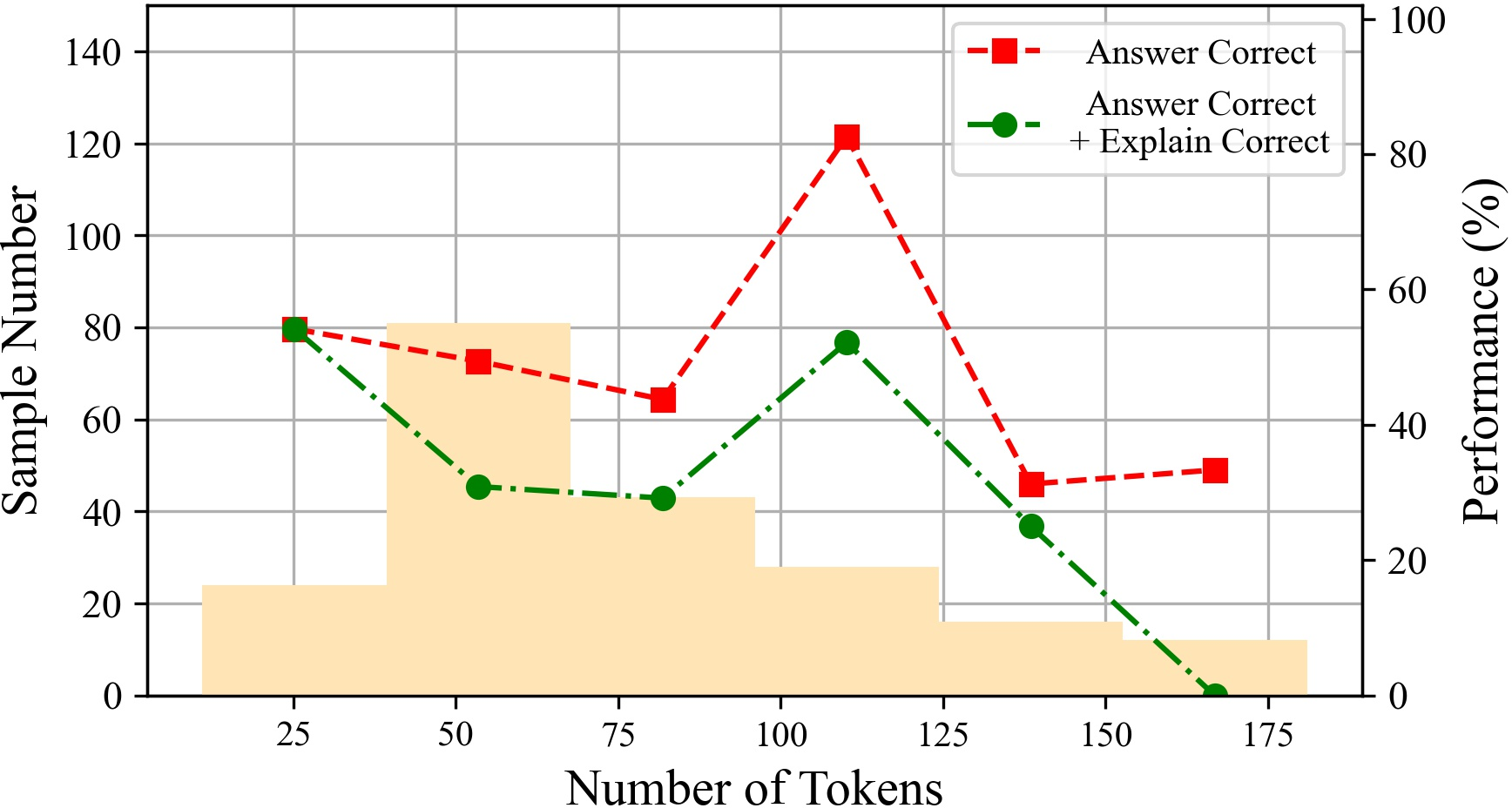
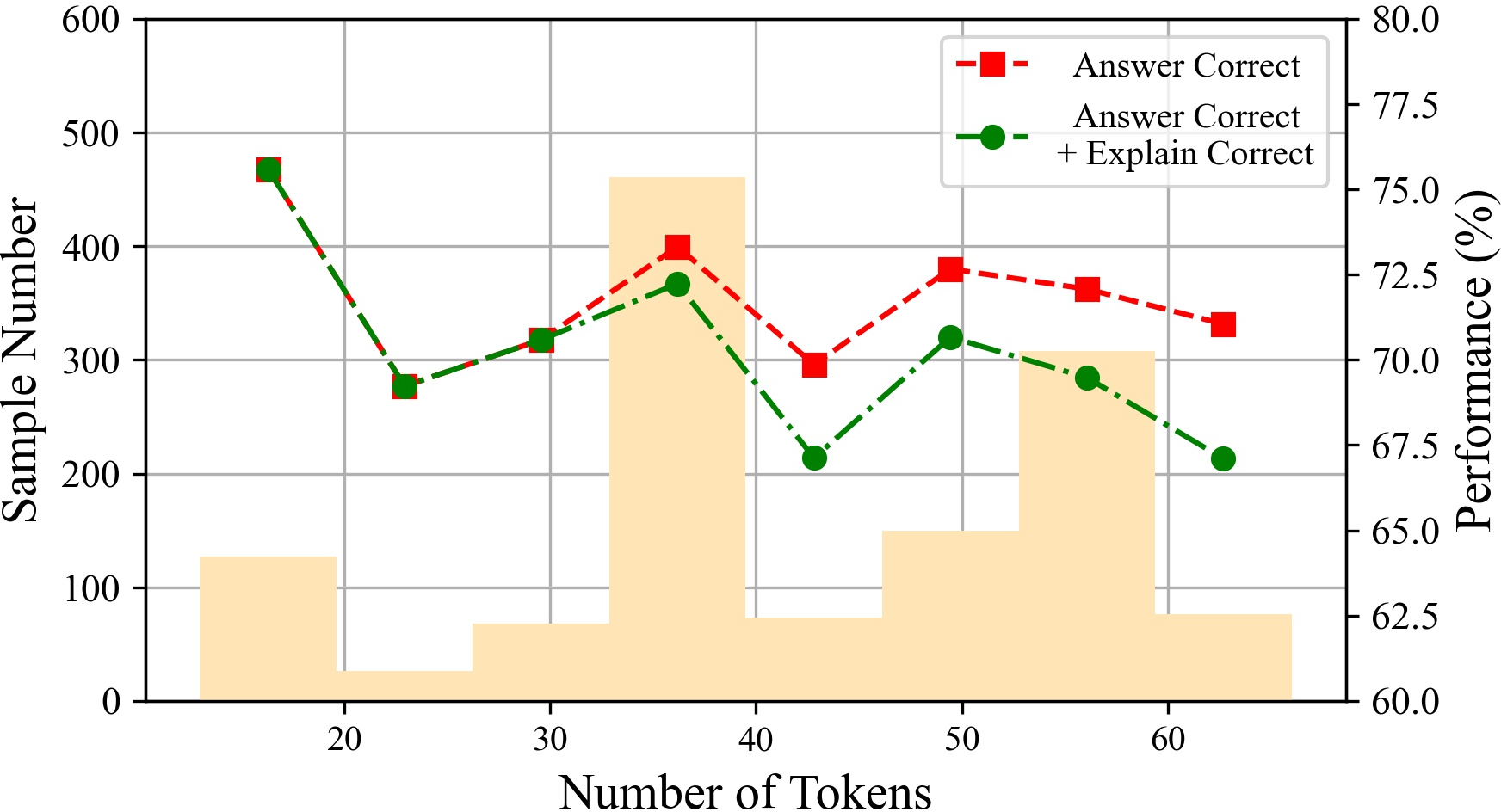
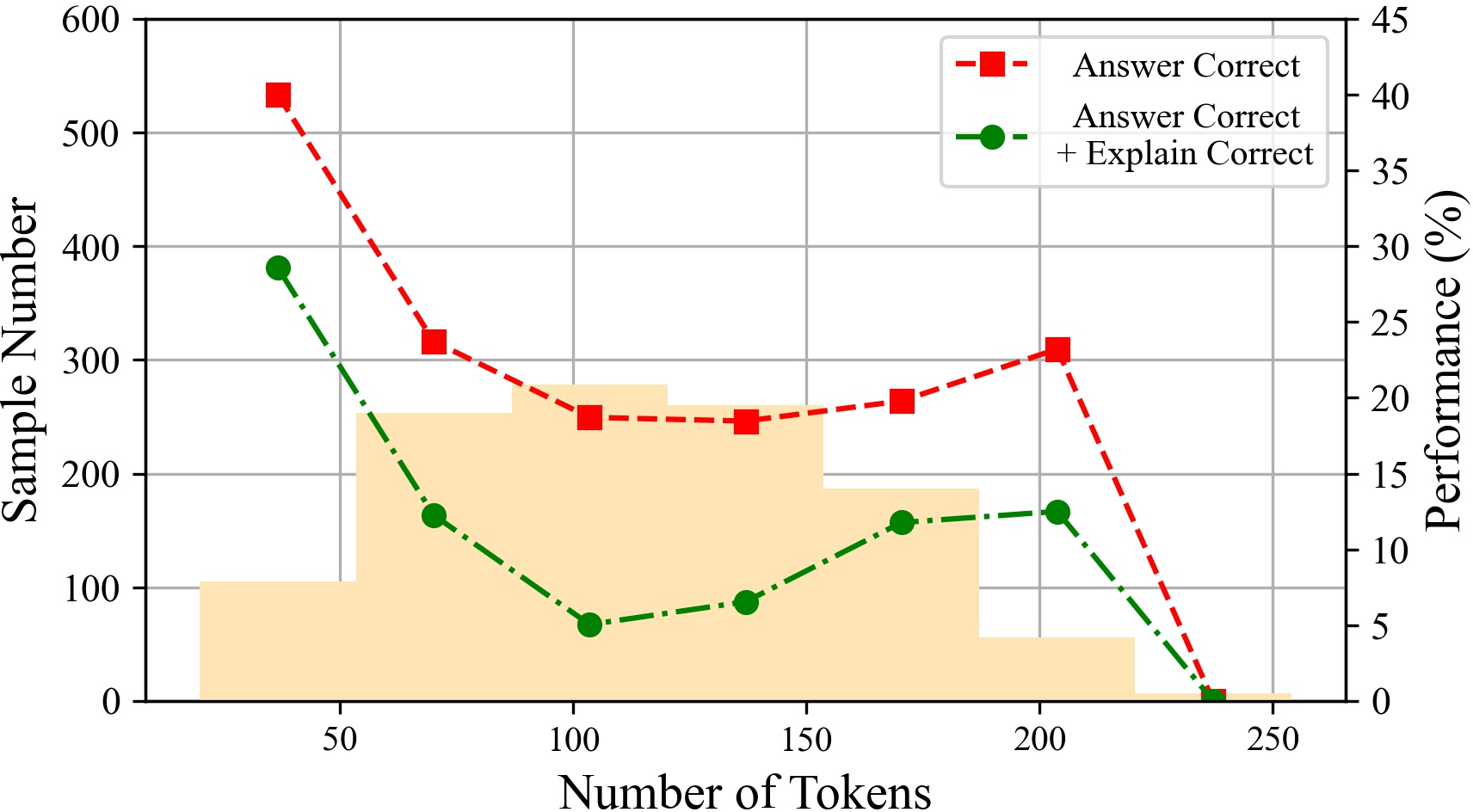
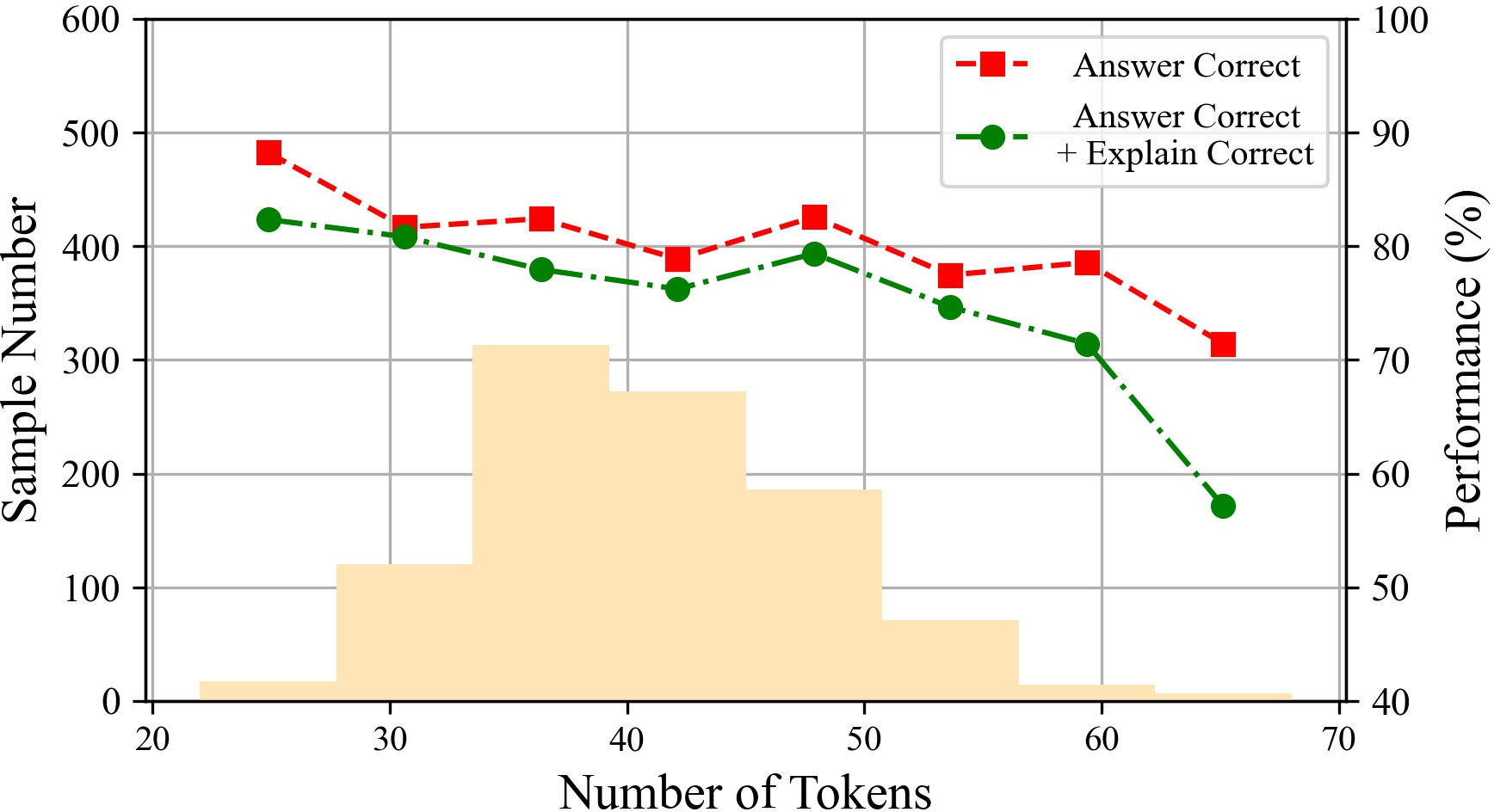
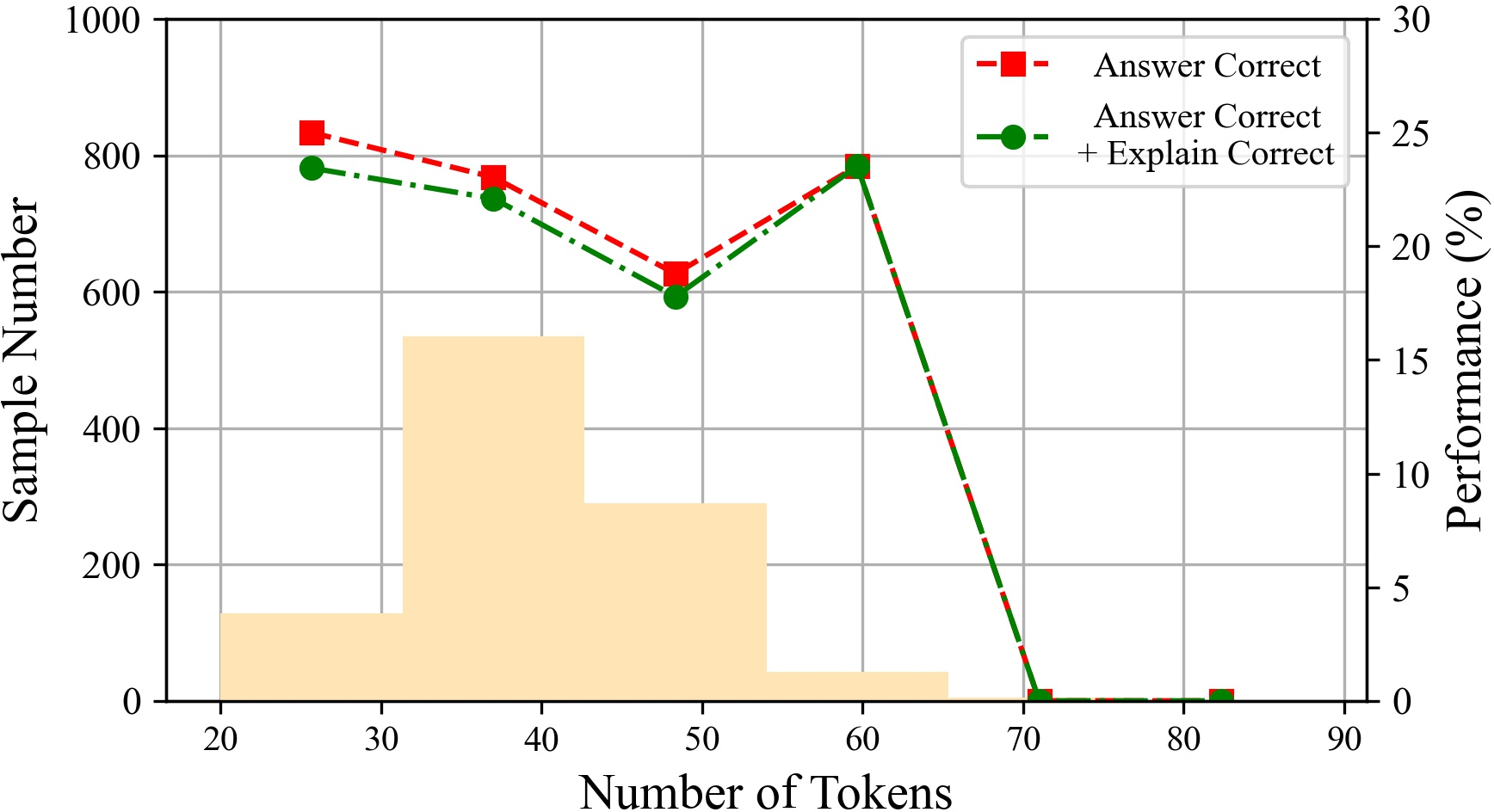
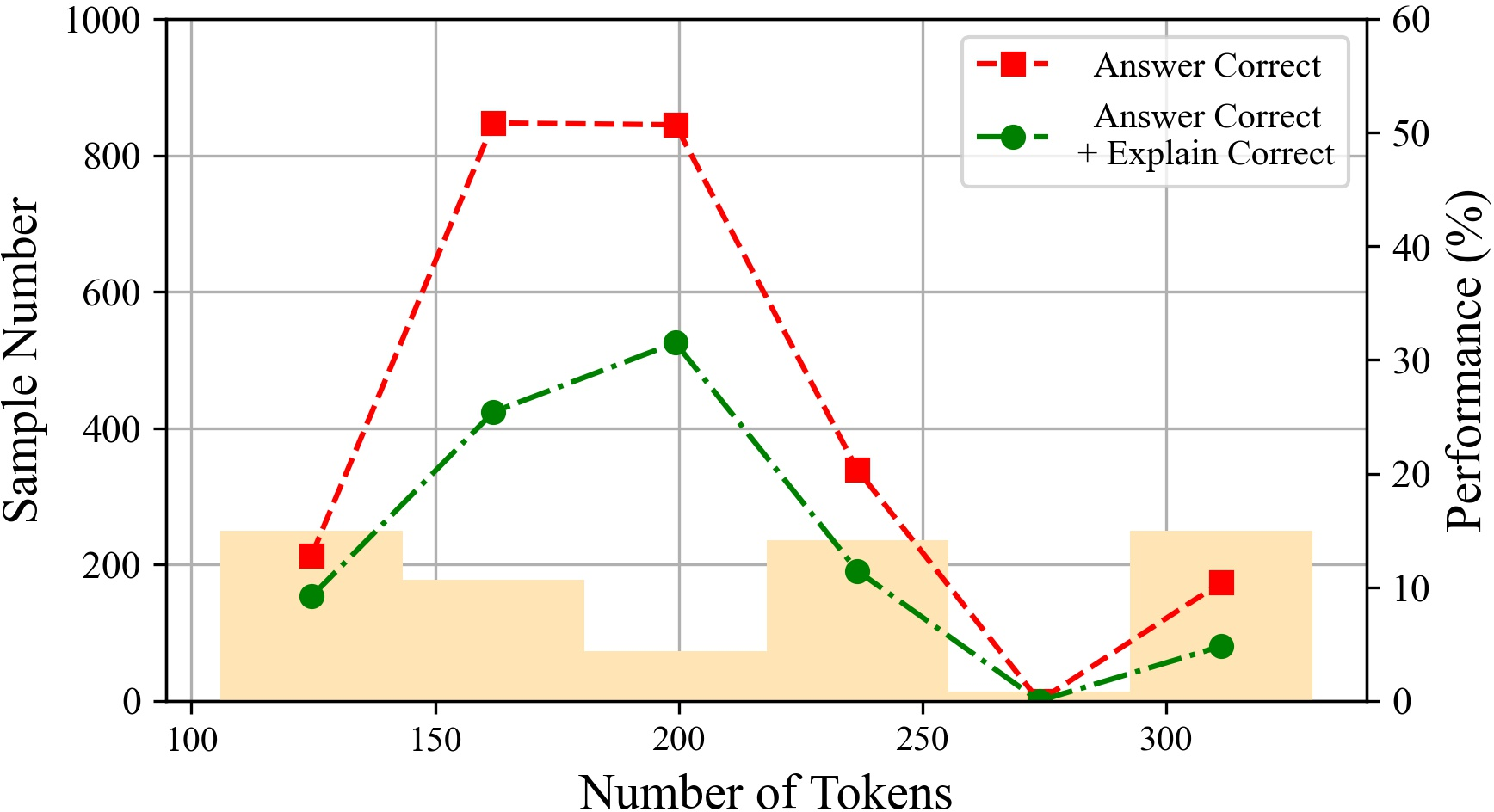
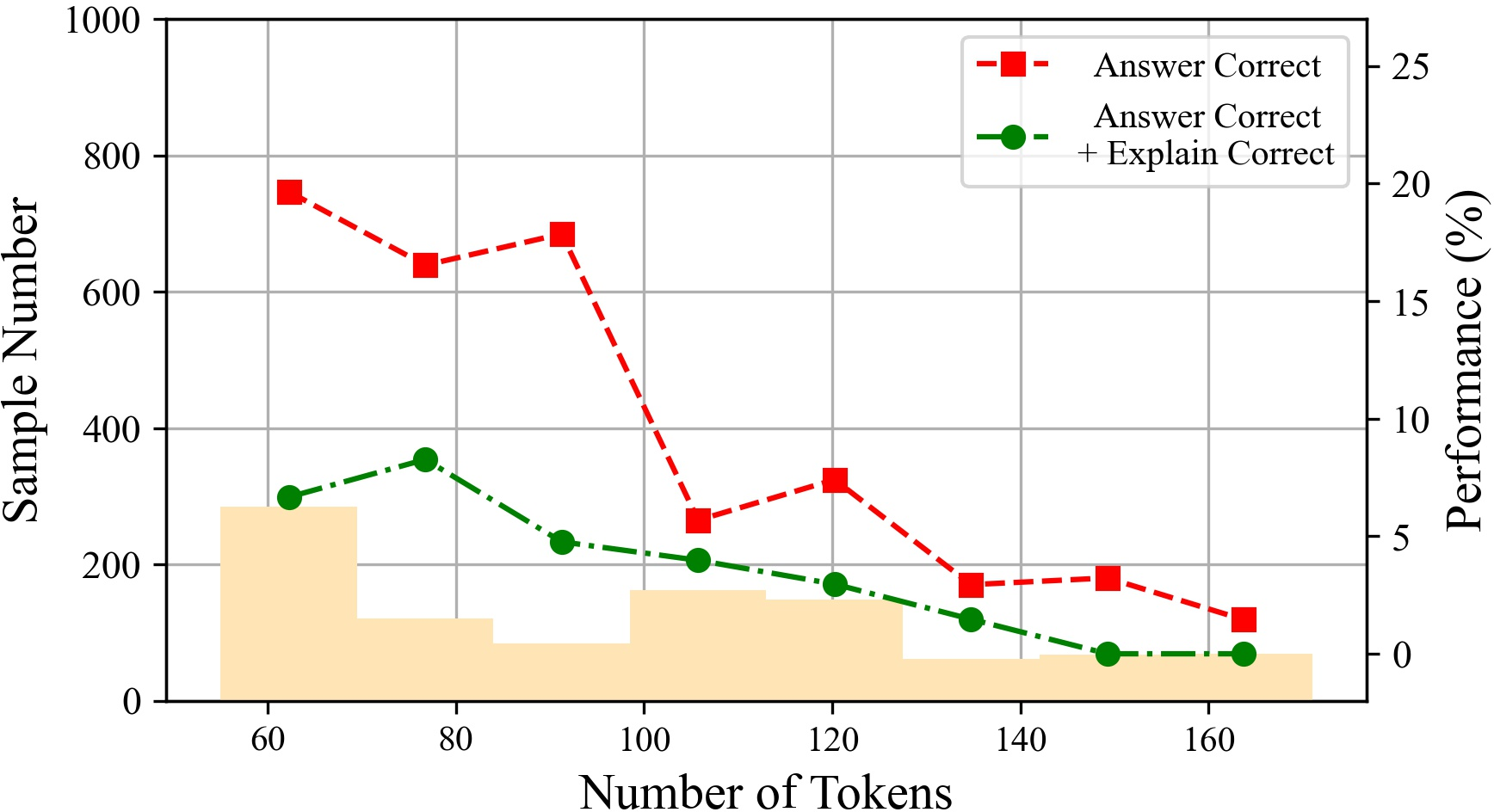
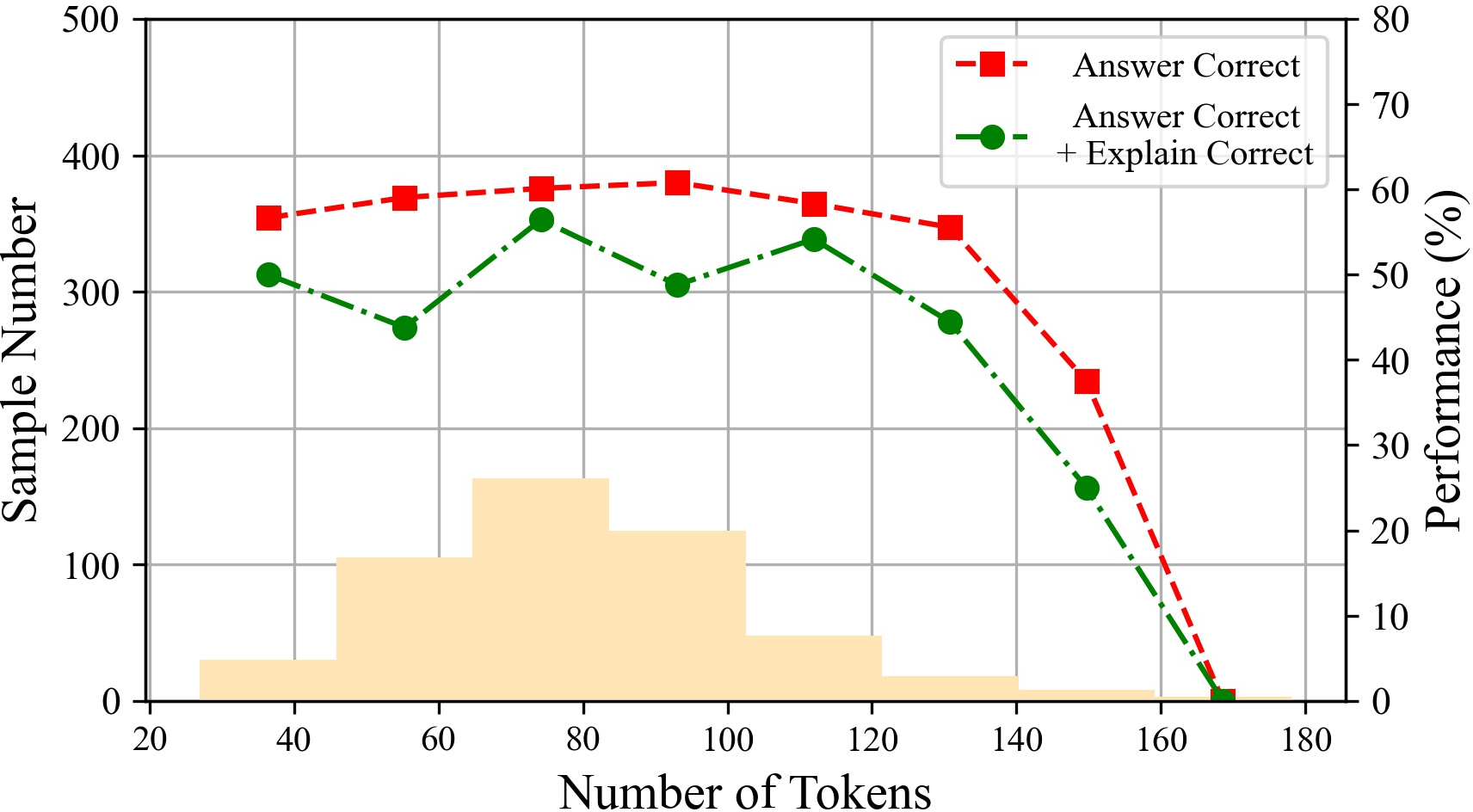
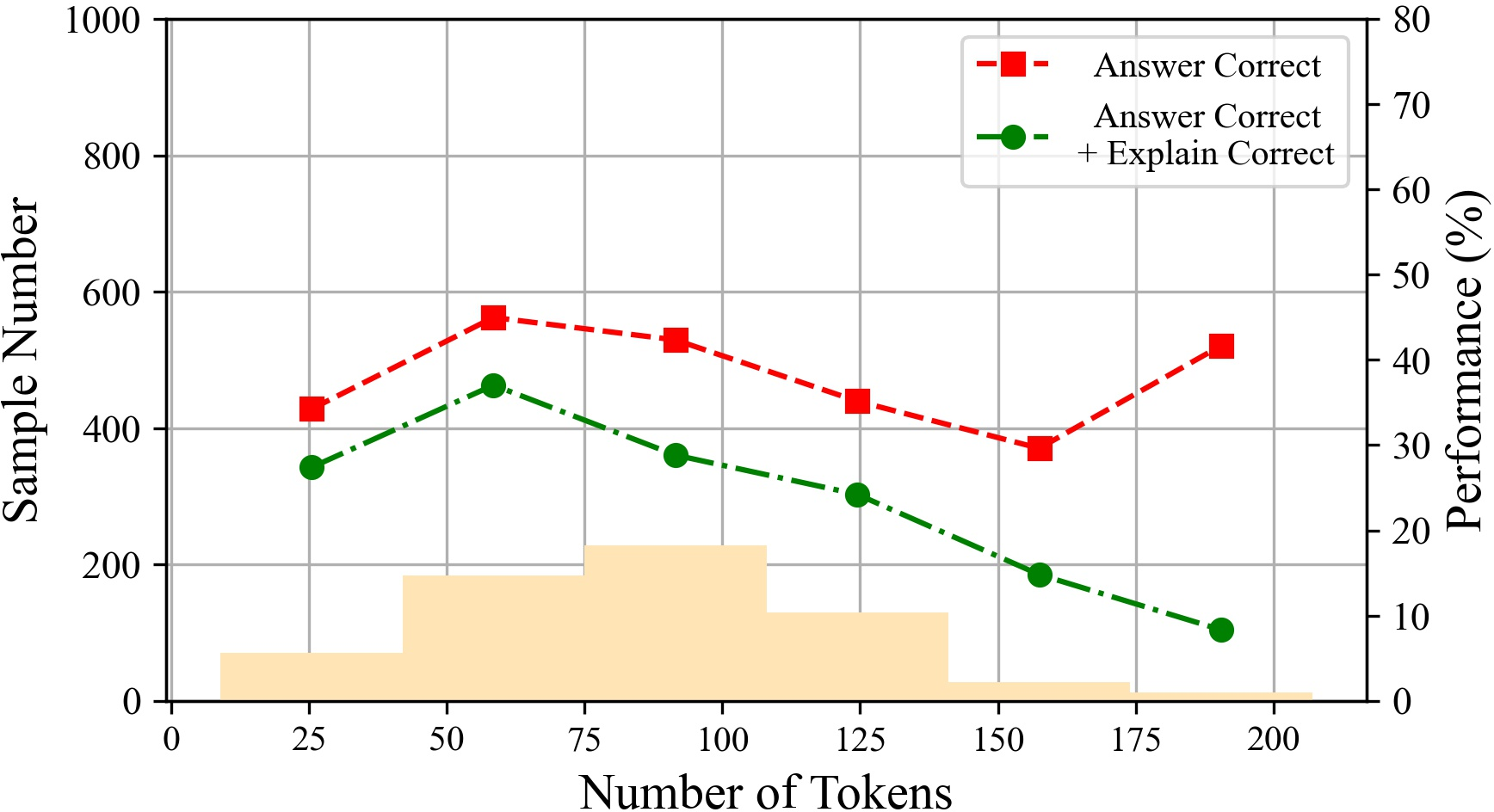
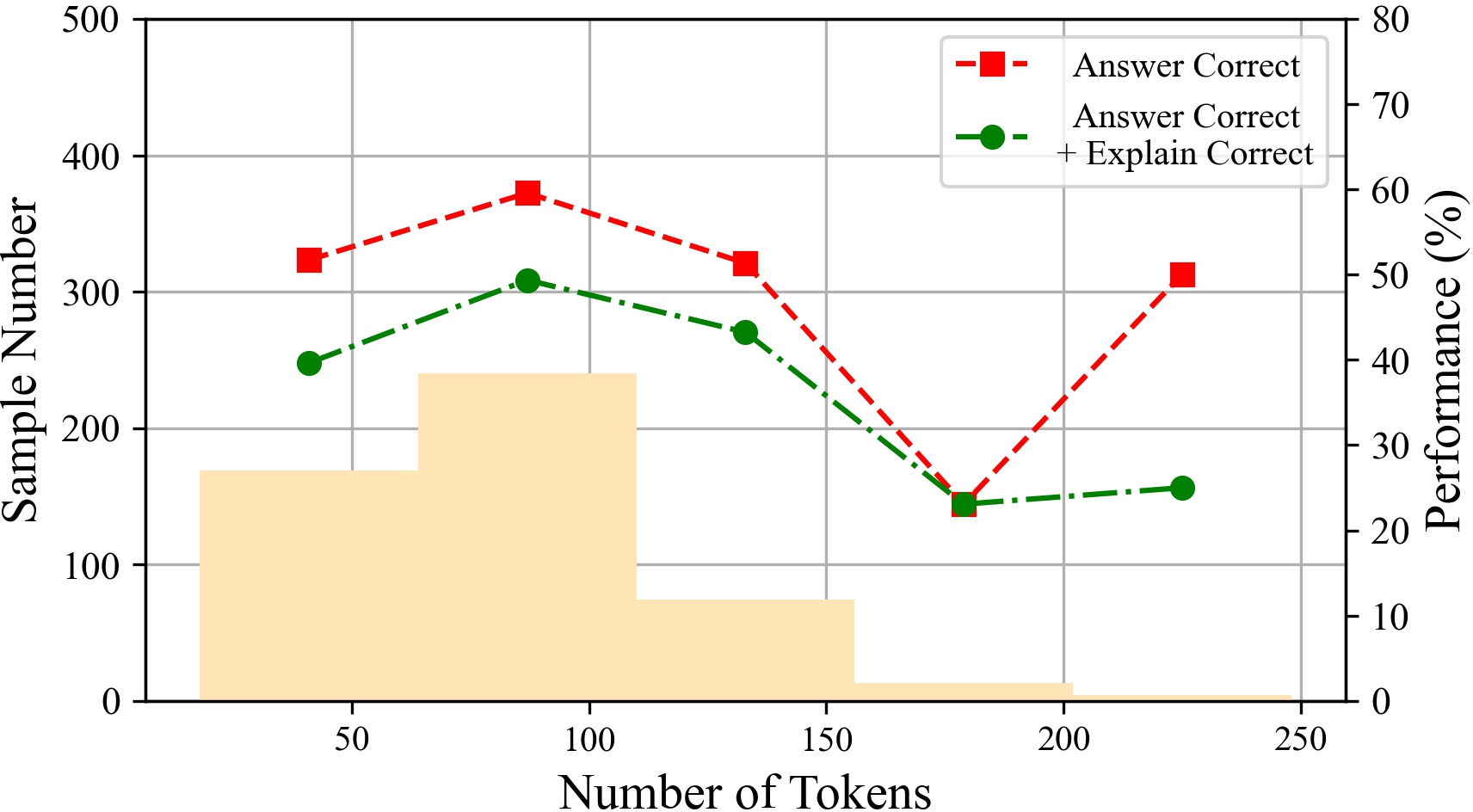
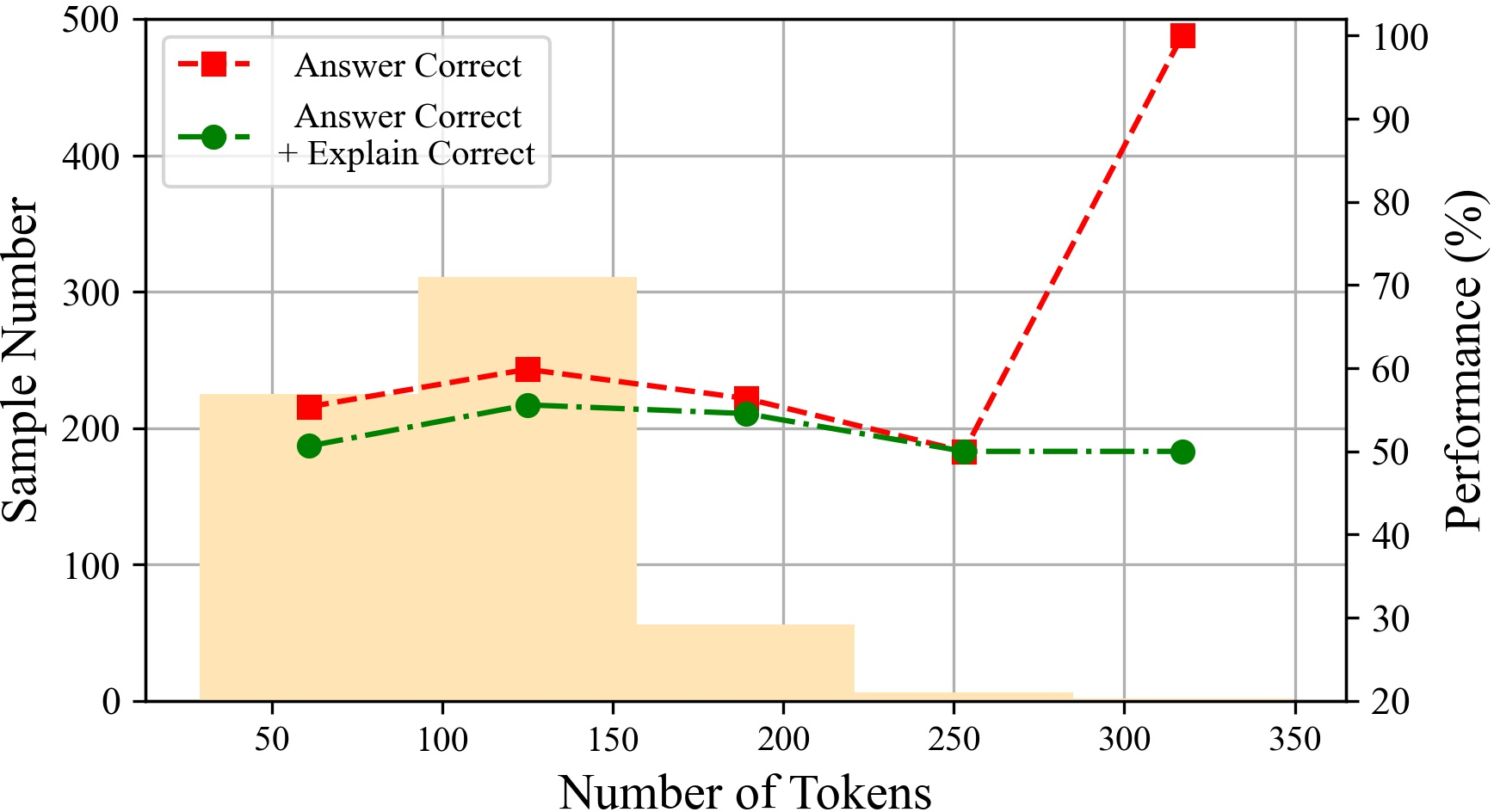
Figure 6: The performances of ChatGPT with different tokens on various datasets.
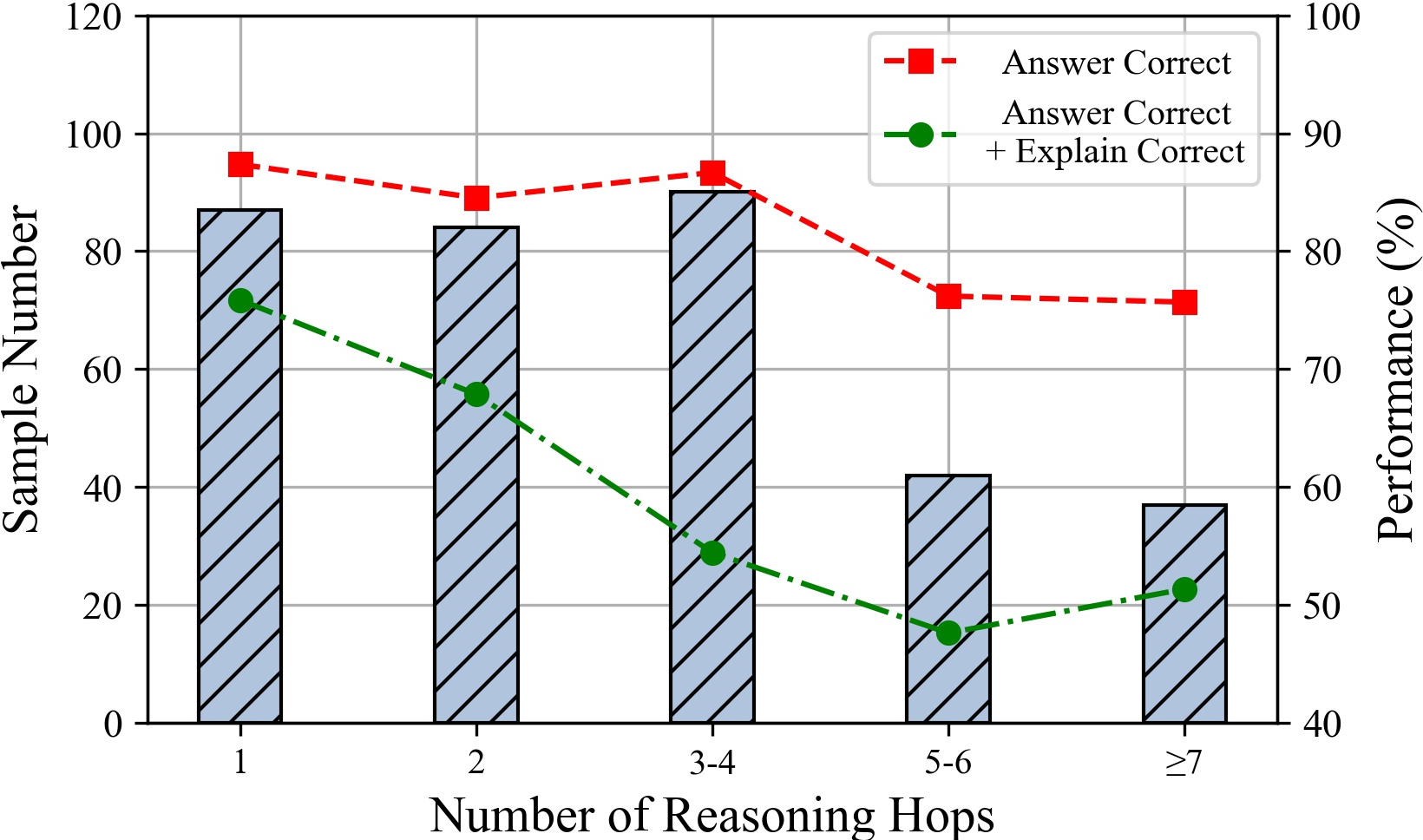
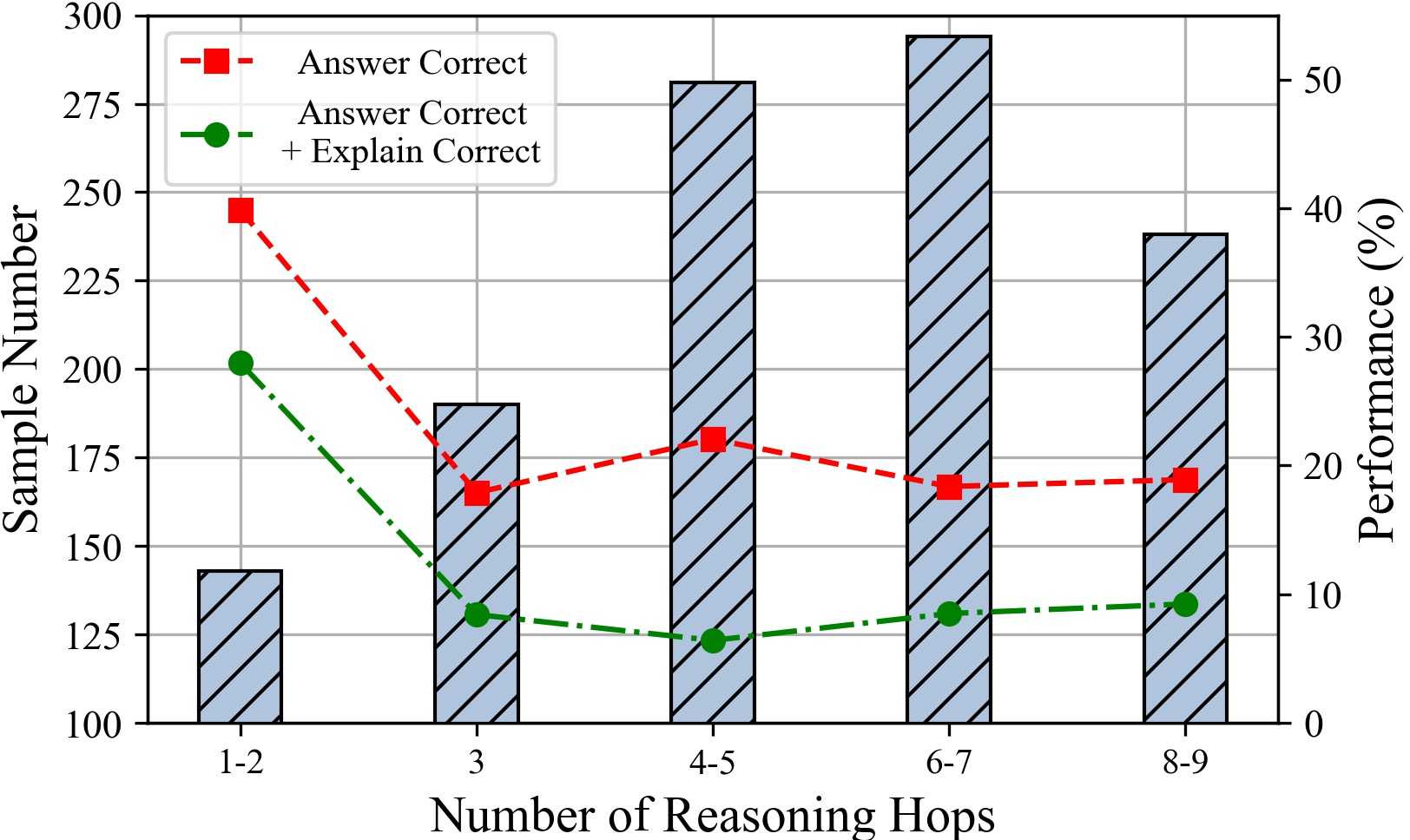
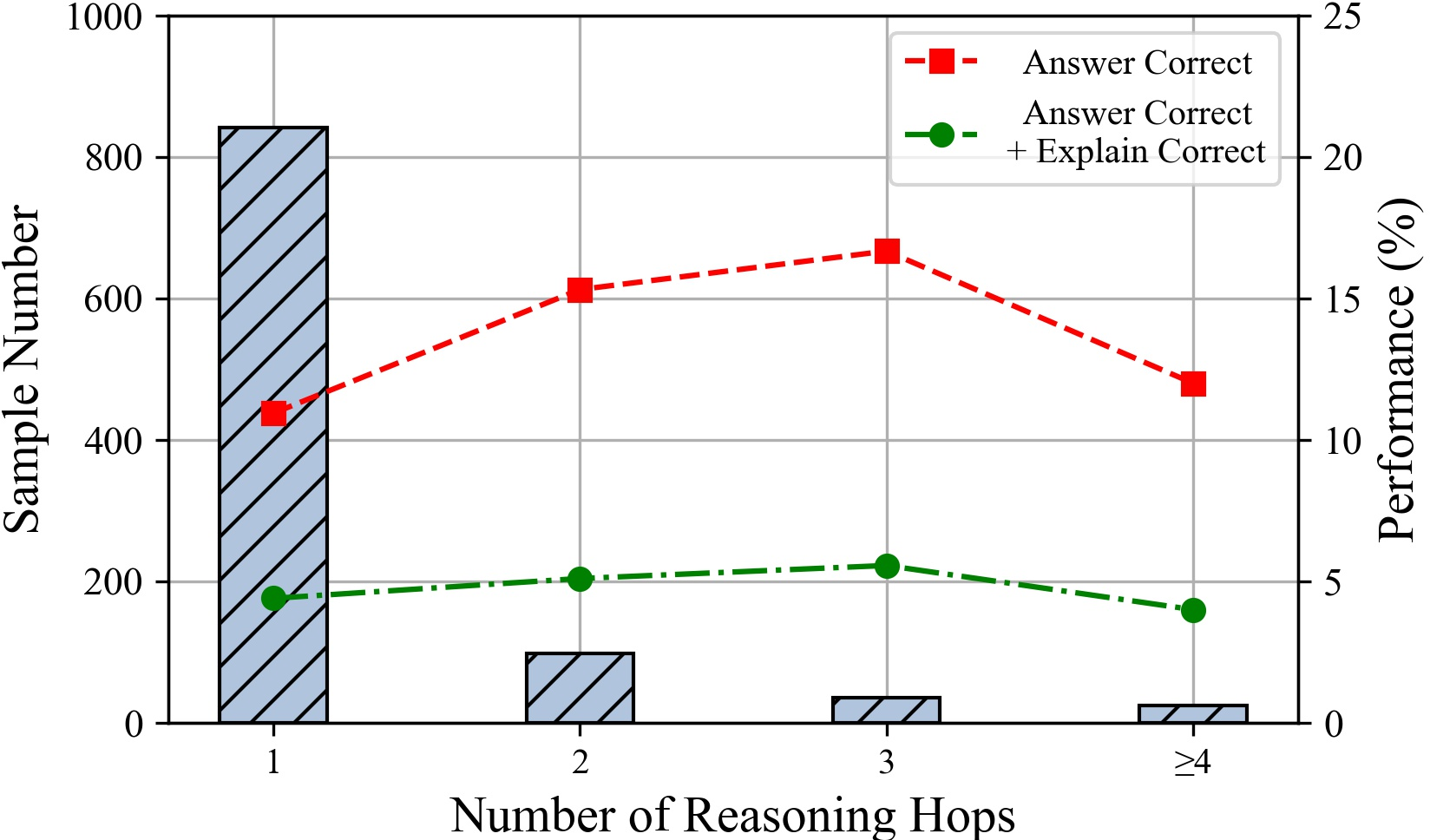
Figure 7: The performances of ChatGPT under different number of hops. Comparison of Deductive, Inductive and Abductive reasoning settings.
Neutral-Content Logical Reasoning
The authors evaluate the performance of LLMs on the new dataset NeuLR, which comprises content-neutral samples across deductive, inductive, and abductive reasoning types. Few-shot prompting and chain-of-thought prompting can boost the performance of LLMs in most cases, with chain-of-thought prompting helping most to the model accuracy. On NeuLR, LLMs generally perform better on inductive reasoning compared to deductive and abductive reasoning, which contrasts with the findings on classical datasets.
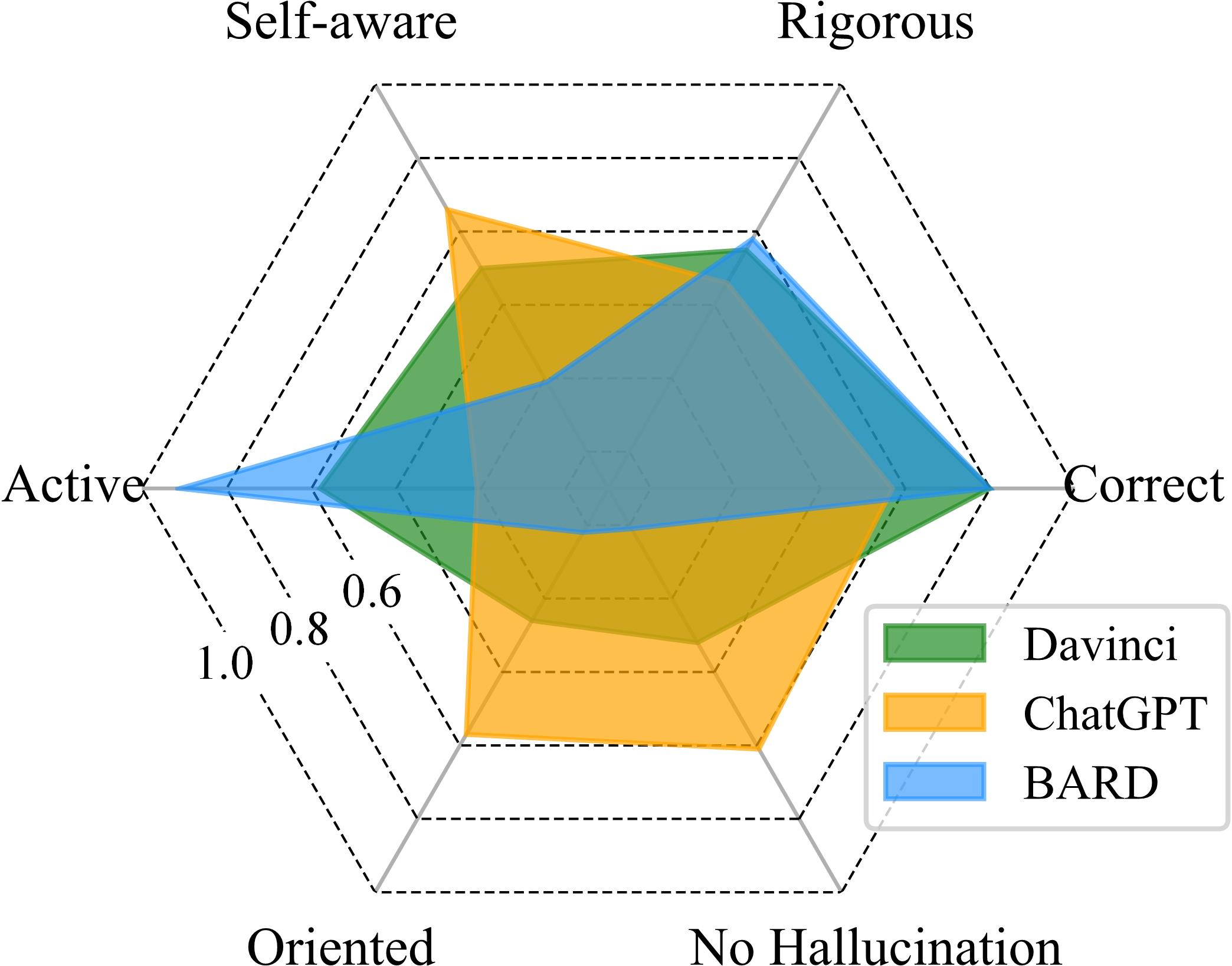
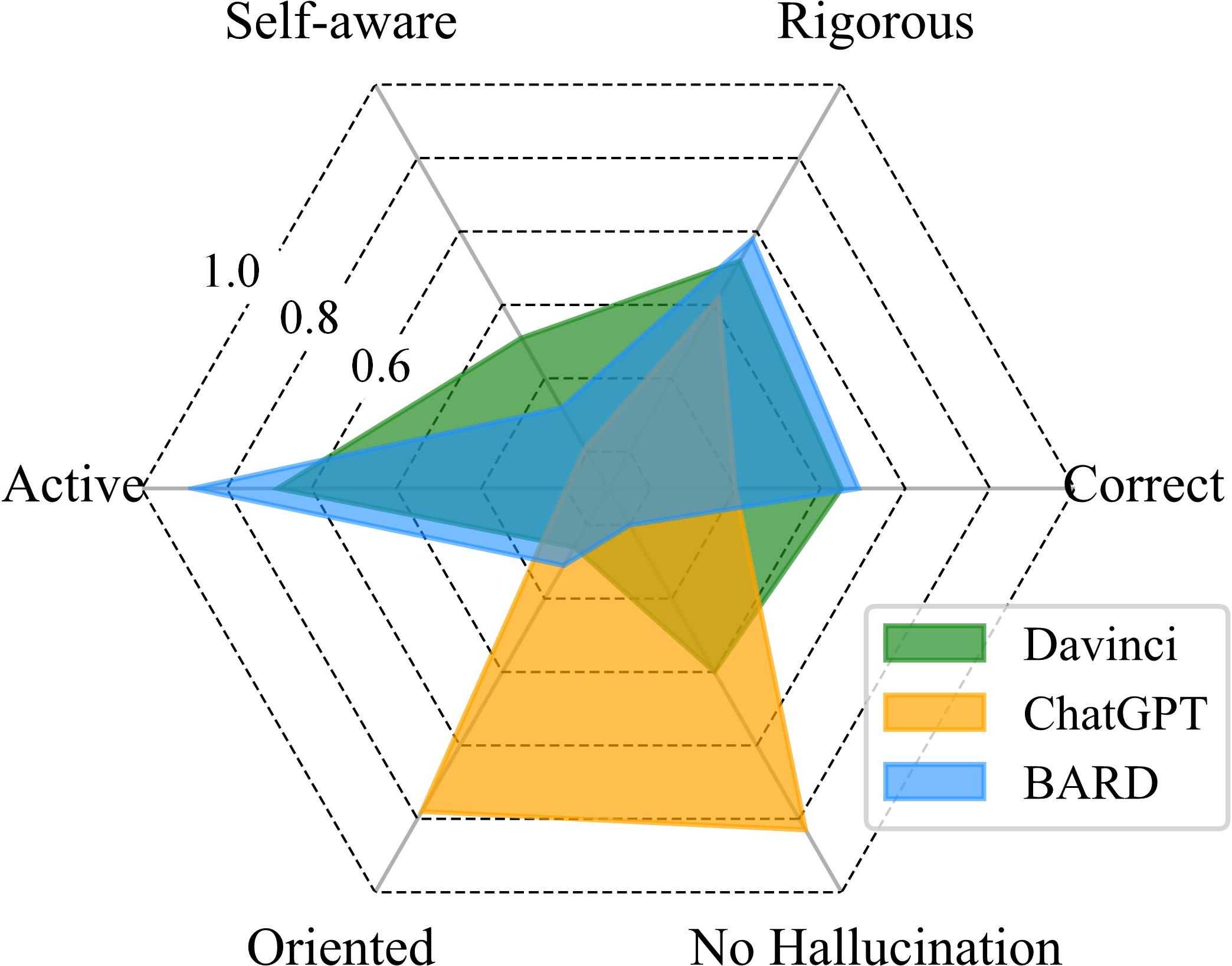
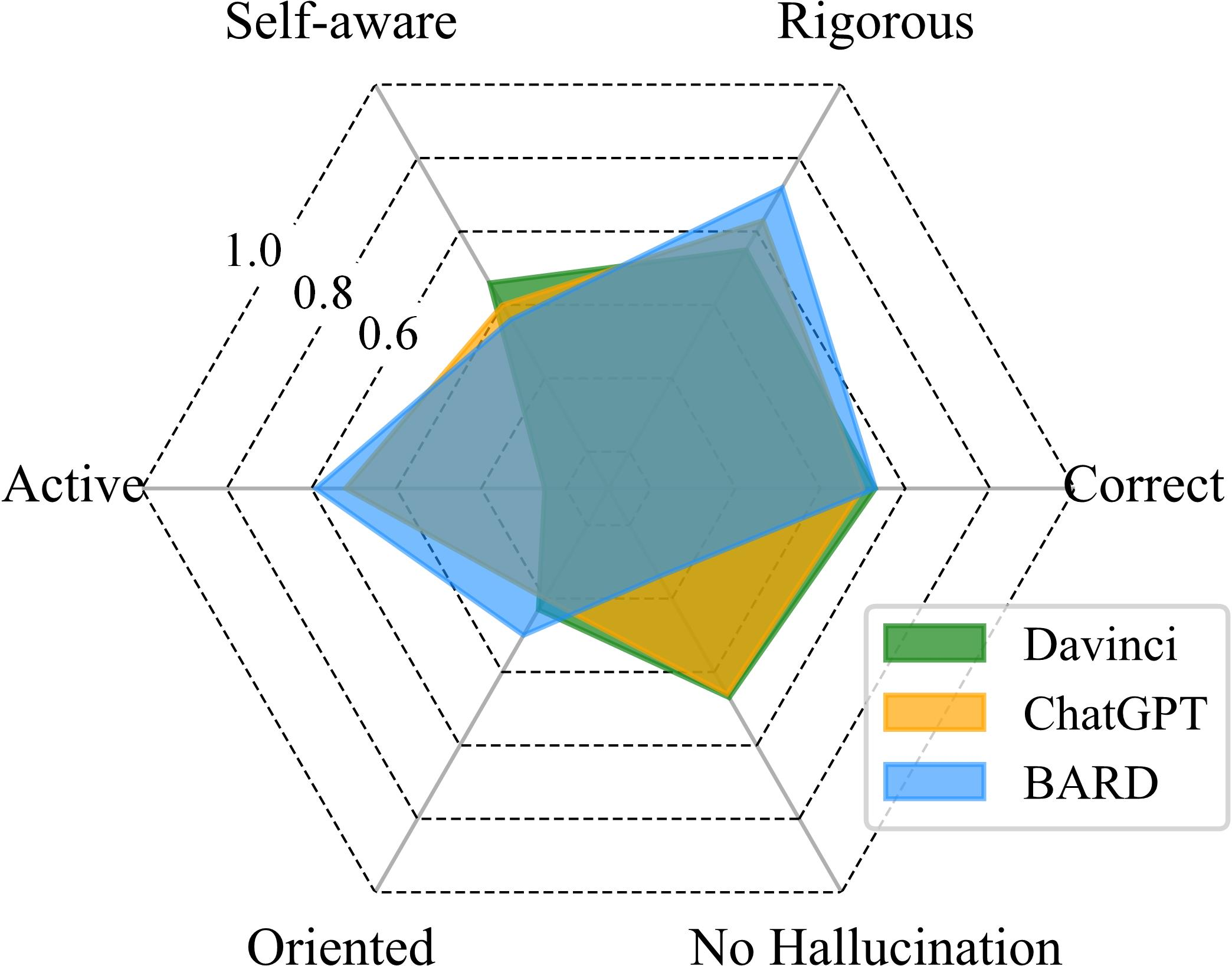
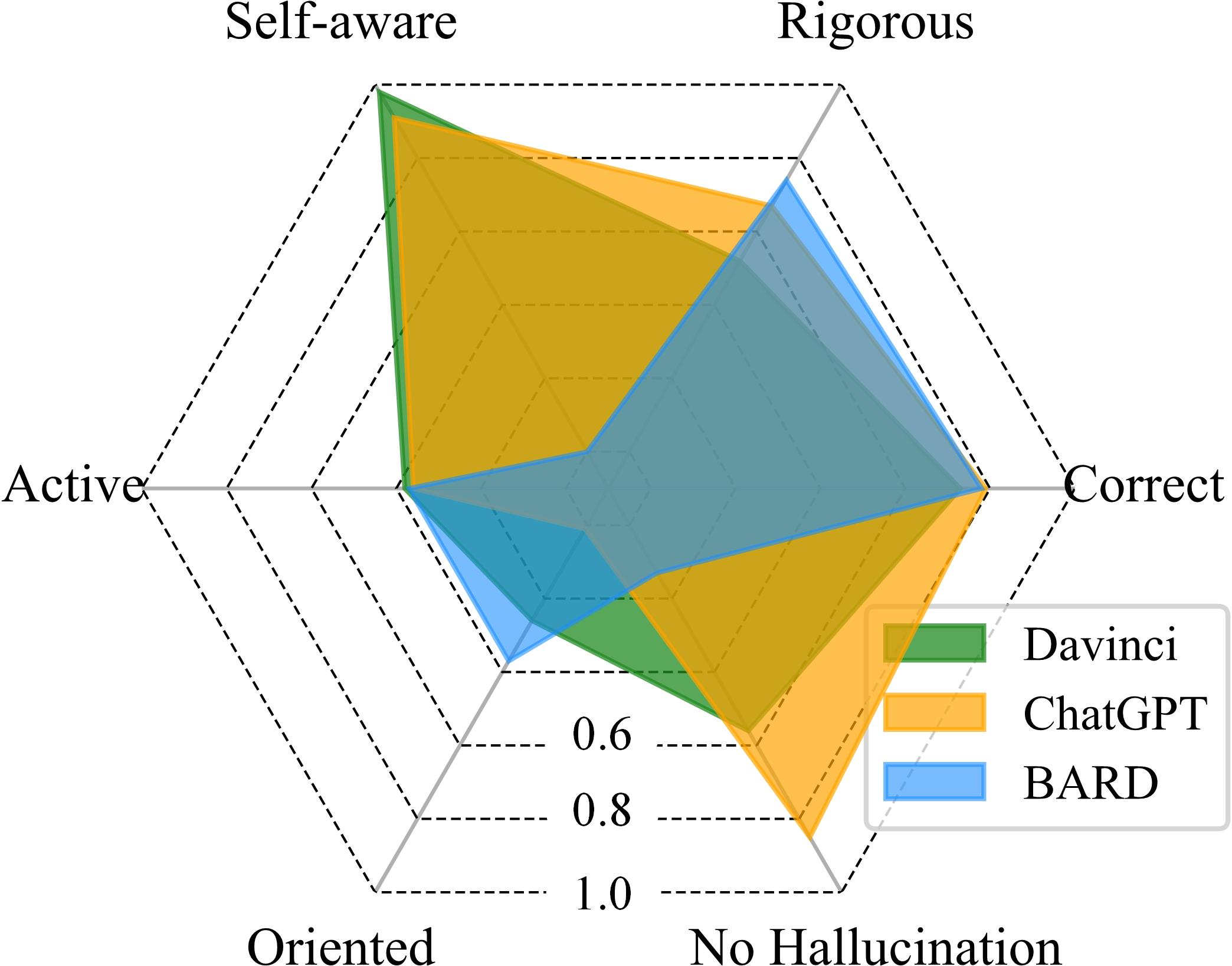
Figure 8: Visualization of LLM capability under four reasoning settings.
Conclusion
The paper concludes that LLMs exhibit specific limitations in logical reasoning, with relative strength in deductive reasoning but evident struggles in inductive settings. Furthermore, current evaluation benchmarks, which primarily depend on objective metrics, are not sufficient to comprehensively evaluate LLMs. The authors propose an evaluation scheme based on six dimensions: Correct, Rigorous, Self-aware, Active, Oriented, and No hallucination.
Future Directions
The paper identifies six future directions for logical reasoning tasks: strengthening inductive reasoning, enhancing the perception of capability boundaries, strengthening rigorous reasoning for real-world scenarios, minimizing hallucinations, improving multi-hop reasoning, and increasing explainability.

