- The paper introduces a novel SSD-KD framework that leverages small-scale synthetic samples for efficient, data-free knowledge distillation.
- It balances sample diversity and difficulty via a modulating function and dynamic replay buffer guided by reinforcement learning.
- SSD-KD achieves significant efficiency gains, with up to 3.92× faster training on CIFAR-10 and notable accuracy improvements on CIFAR-100 and NYUv2.
Small Scale Data-Free Knowledge Distillation
Introduction
The paper "Small Scale Data-Free Knowledge Distillation" (2406.07876) introduces an advanced method for efficient data-free knowledge distillation (D-KD). D-KD is crucial for deploying neural networks on resource-constrained devices without accessing the original training dataset, thus avoiding privacy and security concerns. Traditional D-KD methods synthesize large-scale samples using a generative adversarial network, guided by a pre-trained large teacher network. This paper proposes a paradigm shift by employing a strategy that leverages small-scale synthetic samples to accelerate training while maintaining high model performance.
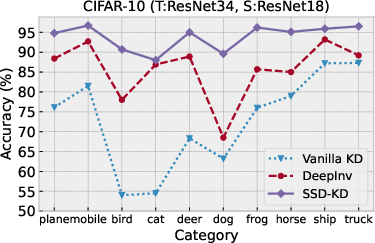
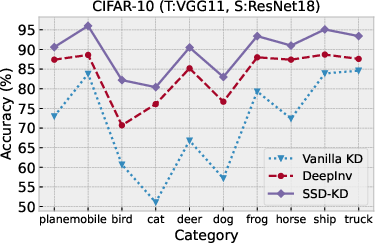
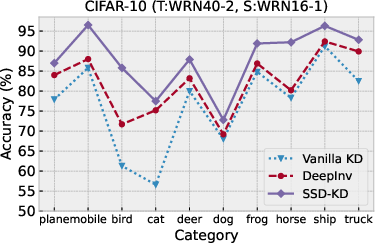
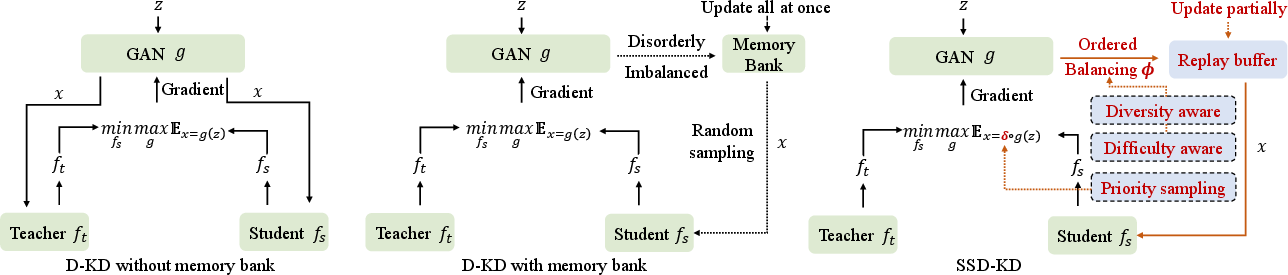
Figure 1: Comparison of knowledge distillation (KD) using original samples vs. synthetic samples, under the same training data scale: 5000 samples (10% of the CIFAR-10 training dataset size).
Methodology
Small Scale Data-Free Knowledge Distillation (SSD-KD)
SSD-KD introduces a novel framework that focuses on using a significantly reduced dataset scale for synthetic samples. This approach is rooted in three key empirical observations:
- Synthetic Sample Superiority: Synthetic samples can perform better than original samples under a reduced data scale since they inherently reflect alternative views of the distribution learned by the teacher network.
- Balanced Class Distributions: Efficient D-KD requires balancing class distributions in terms of both diversity and difficulty of synthetic samples.
- Dynamic Replay Buffer: A dynamic buffer stores synthetic samples, regulated through reinforcement learning to prioritize and optimize sample selection.
The SSD-KD utilizes a modulating function that adjusts the priority of each synthetic sample, facilitating more efficient training. This function is composed of diversity-aware and difficulty-aware terms, enabling better balance during data inversion and distillation processes, thus reducing redundancy and computational costs.
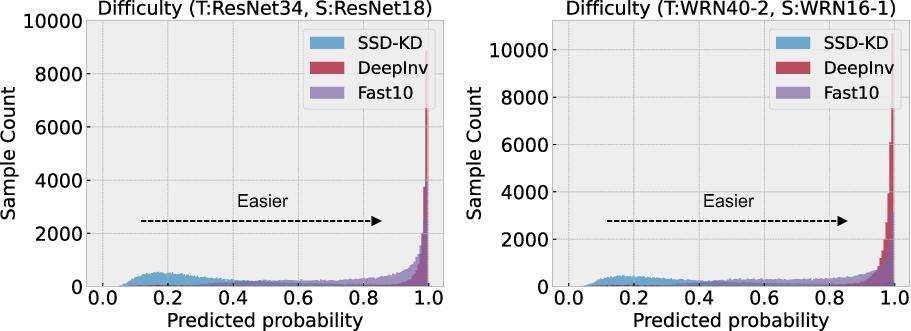
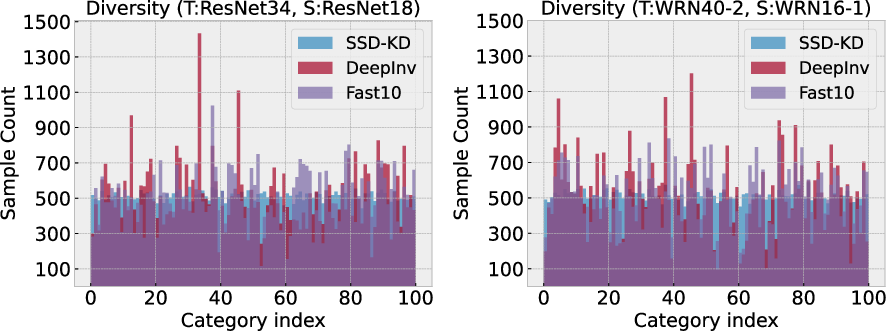
Figure 2: Difficulty distribution.
Results and Comparisons
The SSD-KD demonstrates remarkable improvements in training efficiency, achieving model performance comparable to or better than existing methods.
Image Classification
Table-based experiments on CIFAR-10 and CIFAR-100 illustrate SSD-KD's capabilities:
Semantic Segmentation
On NYUv2:
- SSD-KD delivers state-of-the-art mIoU performance, with synthetic sample usage reduced drastically compared to methods like DFND and Fast10.
- The process efficiency is confirmed by 8.9 hours of training for competitive model generation.
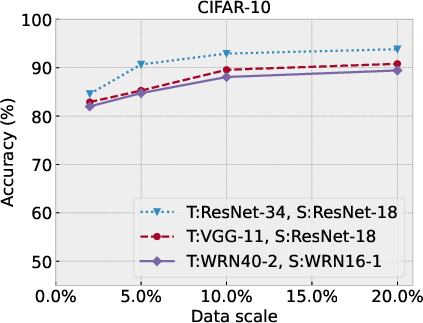
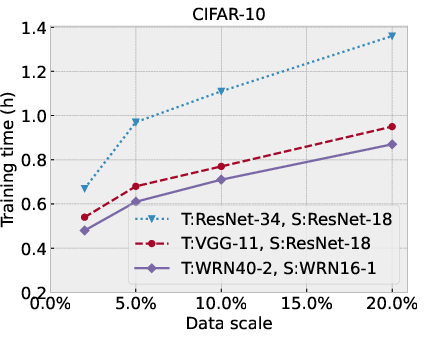
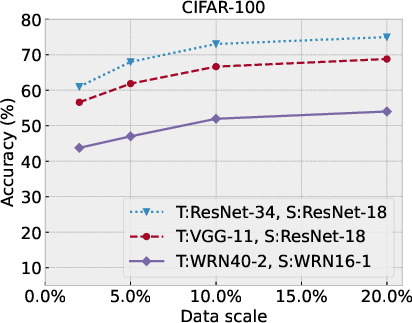
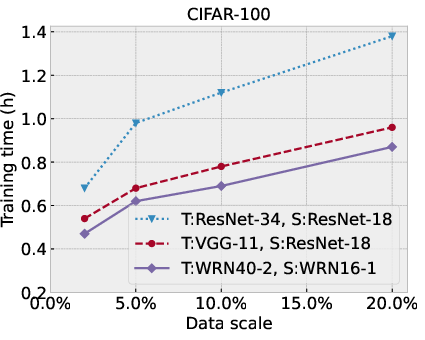
Figure 4: Performance comparison of SSD-KD under different synthetic data scales against the original training dataset size, in terms of top-1 classification accuracy (\%) and overall training time cost (hour).
Ablation Study
SSD-KD's core components were scrutinized to evaluate their contributions. The priority sampling function and modulating function (with diversity and difficulty terms) are integral to achieving balanced performance enhancements in both model accuracy and training efficiency.
Conclusion
The proposed SSD-KD represents a significant step forward in D-KD by enabling efficient knowledge distillation with small-scale synthetic datasets. By balancing sample diversity and difficulty during training, SSD-KD achieves high accuracy with a fraction of the data typically required. The method holds potential for broad application in AI, particularly for tasks involving resource-constrained devices, and sets a new standard for efficient D-KD practices.

Figure 5: Visualization examples of synthetic image samples generated by Fast10 and our SSD-KD for the NYUv2 dataset.