The Linear Representation Hypothesis and the Geometry of Large Language Models
Abstract: Informally, the 'linear representation hypothesis' is the idea that high-level concepts are represented linearly as directions in some representation space. In this paper, we address two closely related questions: What does "linear representation" actually mean? And, how do we make sense of geometric notions (e.g., cosine similarity or projection) in the representation space? To answer these, we use the language of counterfactuals to give two formalizations of "linear representation", one in the output (word) representation space, and one in the input (sentence) space. We then prove these connect to linear probing and model steering, respectively. To make sense of geometric notions, we use the formalization to identify a particular (non-Euclidean) inner product that respects language structure in a sense we make precise. Using this causal inner product, we show how to unify all notions of linear representation. In particular, this allows the construction of probes and steering vectors using counterfactual pairs. Experiments with LLaMA-2 demonstrate the existence of linear representations of concepts, the connection to interpretation and control, and the fundamental role of the choice of inner product.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper studies a simple, powerful idea about LLMs like LLaMA-2: many high-level ideas or “concepts” (like male vs. female, English vs. French, past vs. present tense) are stored inside the model as straight-line directions in a mathematical space. If that’s true, we can understand and even control what the model does by doing basic geometry with vectors (arrows) in that space.
The authors make this idea precise, show how different ways of using these directions are connected, and introduce a better way to measure angles and lengths in this space so that the geometry matches how language actually works.
Key Questions
The paper focuses on two friendly questions:
- What exactly does it mean for a language concept to be “linear,” i.e., a direction in the model’s representation space?
- What is the right way to measure similarity and do projections in that space, so that the geometry reflects real language structure?
How They Studied It (Methods)
To keep things concrete, here are the main ideas they use.
Concepts and “counterfactual pairs”
- Think of a concept as something you can switch without changing other things. For example, switching “king” to “queen” changes gender but not the idea of royalty; switching English to French changes language but not meaning.
- A “counterfactual pair” is a pair of words or phrases that are the same except for one concept. Examples:
- Gender: (king, queen), (man, woman)
- Language: (king, roi), (woman, femme)
- Case: (king, King)
- These pairs act like before/after snapshots that isolate just one concept change.
Two spaces inside an LLM
LLMs have two relevant vector spaces:
- Input/Context space (embedding space): vectors that represent the current sentence or context the model is reading.
- Output/Word space (unembedding space): vectors that represent the possible next words.
The paper defines a “linear representation” of a concept in both spaces:
- In the output (word) space: concept = one direction all relevant counterfactual pairs line up with. For example, arrows like “queen − king” and “woman − man” point roughly in the same direction: the gender direction.
- In the input (context) space: concept = one direction that, when added to the context vector, raises the chance of that concept showing up (e.g., switching outputs toward “queen” over “king”) without affecting unrelated concepts.
These two views connect to two useful tools:
- Measuring a concept (linear probing): use a simple dot product with a direction to predict the concept (e.g., “is this context French?”).
- Steering a concept (intervention/editing): add a direction to push the output toward a concept (e.g., make the next word more likely to be French or female).
Choosing the right “ruler”: a causal inner product
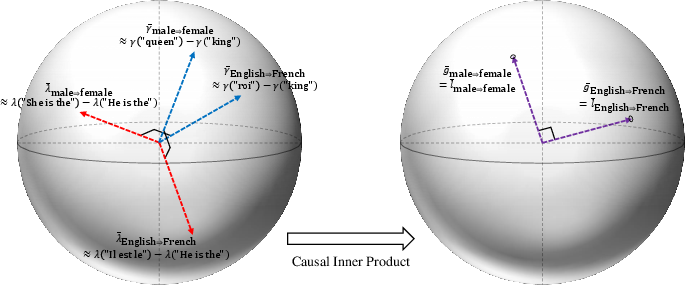
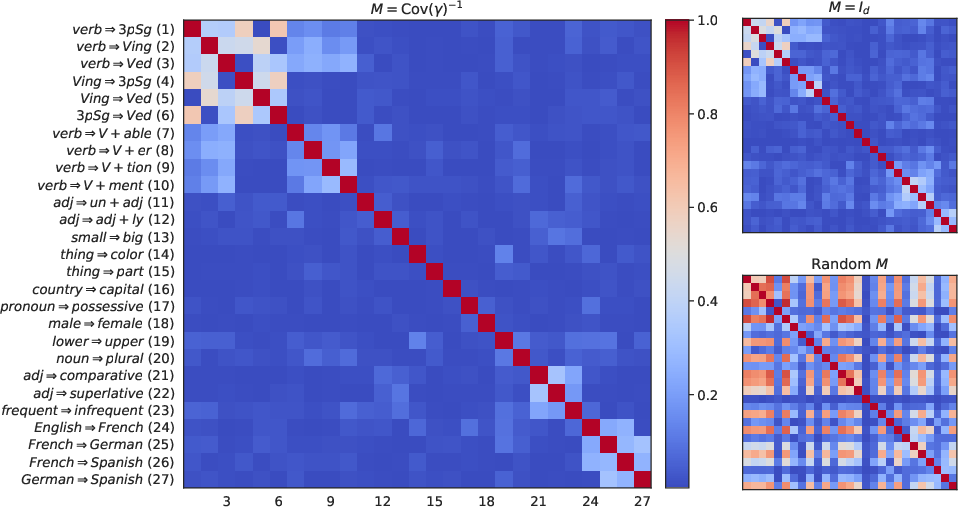
- To compare directions (similarity, angle, projection), you need a “ruler”—a way to measure lengths and angles called an inner product. The usual one is Euclidean, but the authors argue this may not match language structure.
- They propose a “causal inner product” that makes causally independent concepts perpendicular. For example, language (English vs. French) should be perpendicular to gender (male vs. female), because you can vary them separately.
- They show how to estimate a practical version of this inner product from the model’s word vectors using statistics (essentially whitening: use the inverse of the word-vector covariance matrix). This turns out to better reflect true separations between concepts.
Experiments with LLaMA-2
They test these ideas on LLaMA-2 (7B):
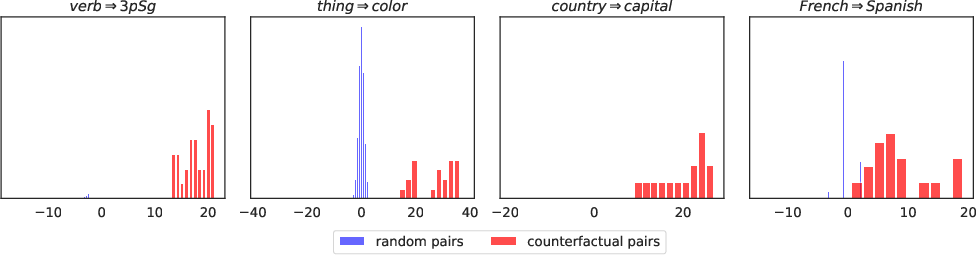
- Build concept directions from many counterfactual pairs, including classic word analogies (like king:queen = man:woman) and language pairs (English–French, French–Spanish, etc.).
- Show that these directions:
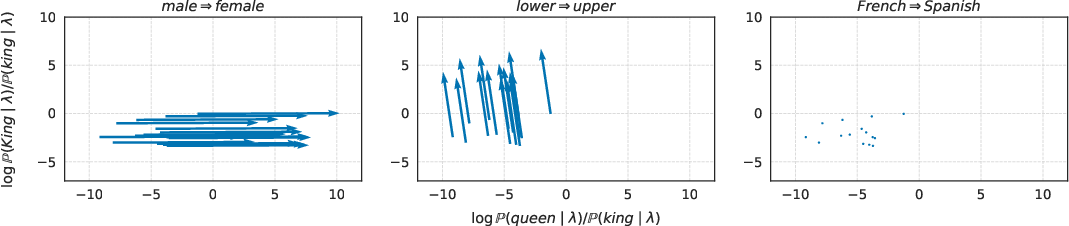
- Align well across many pairs for the same concept (evidence of linearity).
- Act as simple linear probes to detect concepts in context.
- Serve as steering vectors that shift the model’s next-word probabilities toward the target concept without disturbing unrelated concepts.
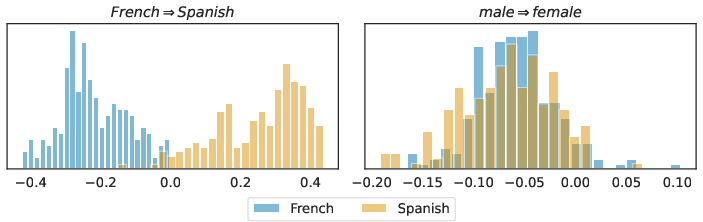
- Compare different inner products (Euclidean vs. their causal one) and show the causal one better matches meaningful separations between concepts.
What They Found (Results)
Here are the main takeaways:
- Linear concept directions exist. Across many word pairs, the difference vectors roughly point in the same direction for the same concept. So “concepts as directions” is a good model.
- Measurement and control are two sides of the same coin. The concept direction in the output space explains why simple linear probes work. The concept direction in the input space explains why adding a vector can steer the model’s behavior.
- A better geometry matters. Using their causal inner product:
- Concepts that can vary independently (like language vs. gender) become perpendicular, which makes sense.
- The two kinds of concept directions (input and output) can be unified, so you can build steering vectors from word-space directions in a principled way.
- Similarity heatmaps show clearer blocks and separations that match real linguistic structure, better than the default Euclidean view.
- Practical steering works. Adding the “female” direction to the context increases the chance of “queen” over “king,” while leaving capitalization or language largely unchanged. Similarly for language directions, and so on.
Why It Matters (Implications)
This work gives a cleaner, more reliable way to understand and control LLMs:
- Interpretability: You can discover concept directions from counterfactual word pairs, then use them to probe what the model “thinks” about a context.
- Controllability: You can edit model behavior in predictable ways (e.g., nudge the next word toward French or toward feminine forms) without accidentally changing unrelated properties.
- Better tools via better geometry: Picking the right inner product—the “causal” one—makes the math line up with how language concepts combine, leading to more meaningful similarity and projection operations.
- Unifying ideas: The paper ties together three popular notions—subspace directions, linear probes, and steering vectors—into one consistent picture.
In simple terms: the paper shows that many language features inside LLMs behave like sliders on a soundboard. If you know the right direction for a concept, you can read it (probe) or adjust it (steer). And if you use the right “ruler” to measure directions, those sliders become cleanly separated, making interpretation and control safer and more dependable.
Collections
Sign up for free to add this paper to one or more collections.

