- The paper introduces a novel MMGL framework that integrates rich multimodal graph-structured neighbor information to boost generative language model performance.
- It evaluates three encoding strategies (SA-TE, SA-E, CA-E) and graph-aware methods like Laplacian and GNN to effectively embed complex multimodal relationships.
- Experiments on the WikiWeb2M dataset demonstrate that parameter-efficient tuning techniques, including LoRA and Flamingo-style adaptations, significantly improve scalability and performance.
Multimodal Graph Learning for Generative Tasks
Introduction
Multimodal Graph Learning (MMGL) represents a significant advancement in the field of multimodal machine learning by extending the traditional one-to-one modality mappings into the more complex and realistic many-to-many relationships. This paper presents a detailed framework of MMGL aimed at enhancing the generative capabilities of pretrained LLMs (LMs) by integrating rich multimodal neighbor contexts structured in graph formats. Unlike previous models, which often focus on straightforward pairings (such as image-caption or audio-text), MMGL accommodates and exploits the intricate inter-modal relationships inherent in datasets like Wikipedia articles.
The paper proposes a systematic MMGL framework that capitalizes on pretrained LMs to generate text, guided by multimodal neighbor datasets. This framework delineates three key research questions focusing on scalability, infusing graph structures into LMs, and parameter-efficient fine-tuning. These issues are critical for ensuring the MMGL model effectively handles the complexity of multimodal datasets without compromising computational efficiency.
Multimodal Graph Learning Framework
Neighbor Encoding
A vital component of the MMGL framework is the efficient encoding of neighbor information. Three encoding methodologies are proposed: Self-Attention with Text+Embeddings (SA-TE), Self-Attention with Embeddings (SA-E), and Cross-Attention with Embeddings (CA-E). Each method is designed to optimize different trade-offs between computational scalability and generative performance.
SA-TE involves concatenating raw text neighbors with image embeddings derived from frozen encoders, effectively allowing LMs to leverage rich neighbor information at the cost of increased input length requirements. SA-E follows a similar process but utilizes embeddings for all modalities, including text, which helps to manage input length but may compromise on the richness of the information provided. CA-E distinguishes itself by feeding embeddings into cross-attention layers within the LMs, requiring significant adaptation but offering potential benefits in terms of input handling and information integration.
Graph Structure Encoding
To encapsulate the structural information inherent in multimodal graphs, the paper explores sequential position encoding and two graph-aware methods: Laplacian Position Encoding (LPE) and Graph Neural Networks (GNN). GNN encoding, in particular, demonstrates superior performance by embedding graph structure intricacies within the positional data, which is subsequently used to inform and enhance text generation within LMs.
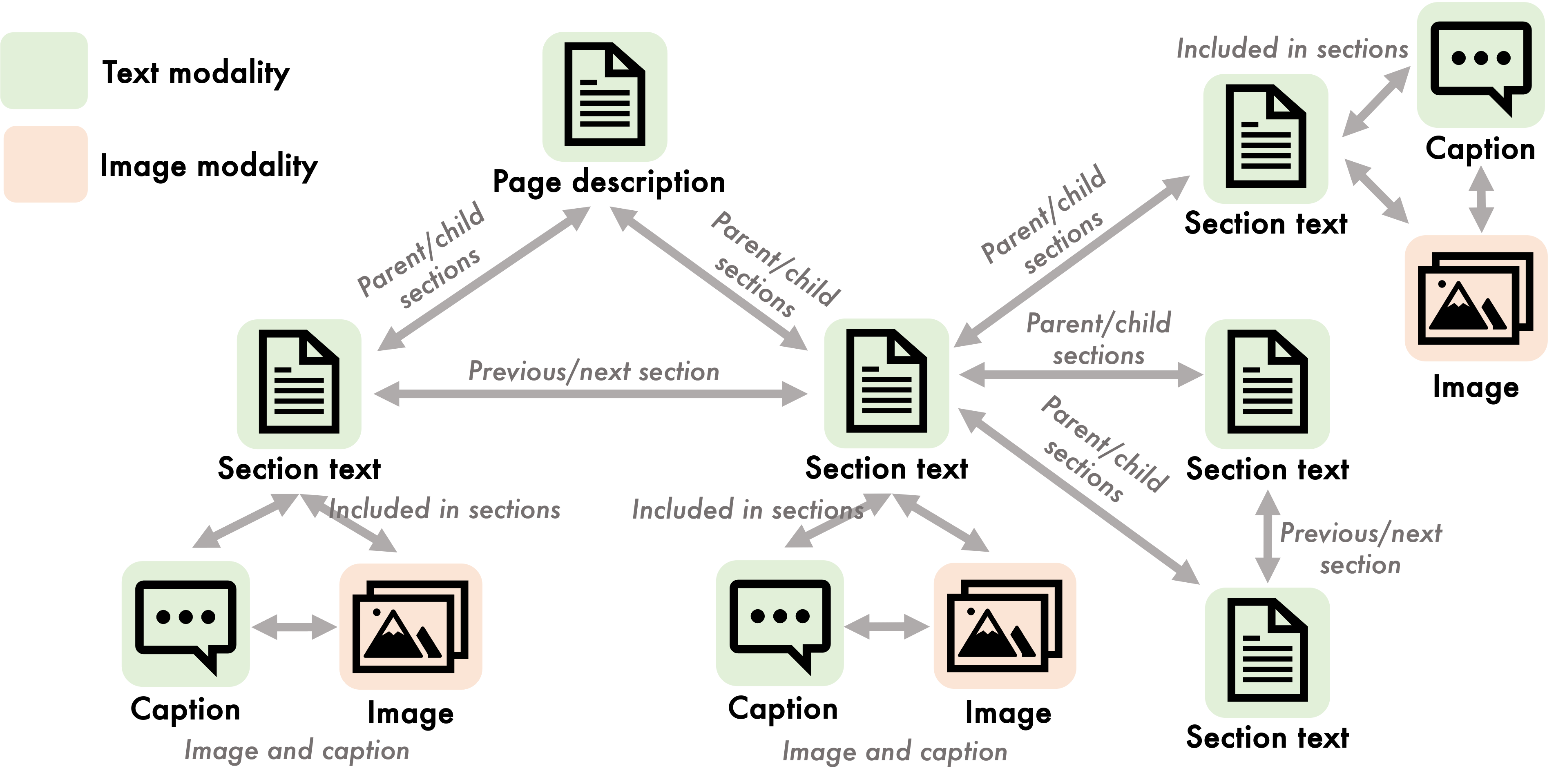
Figure 1: Multimodal datasets extracted from Wikipedia, illustrating $1$-to-$1$ mapping for traditional models and many-to-many mapping for MMGL.
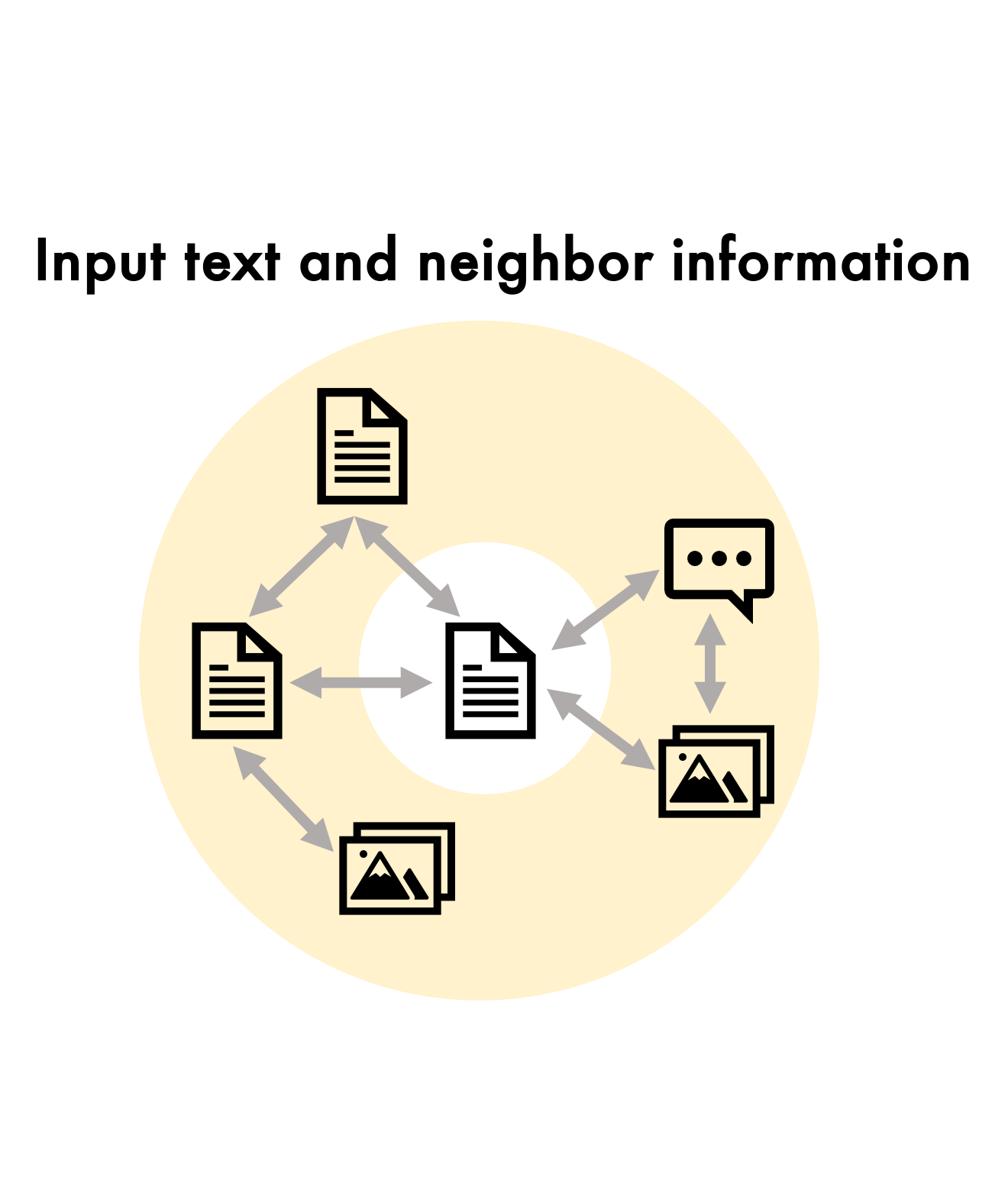
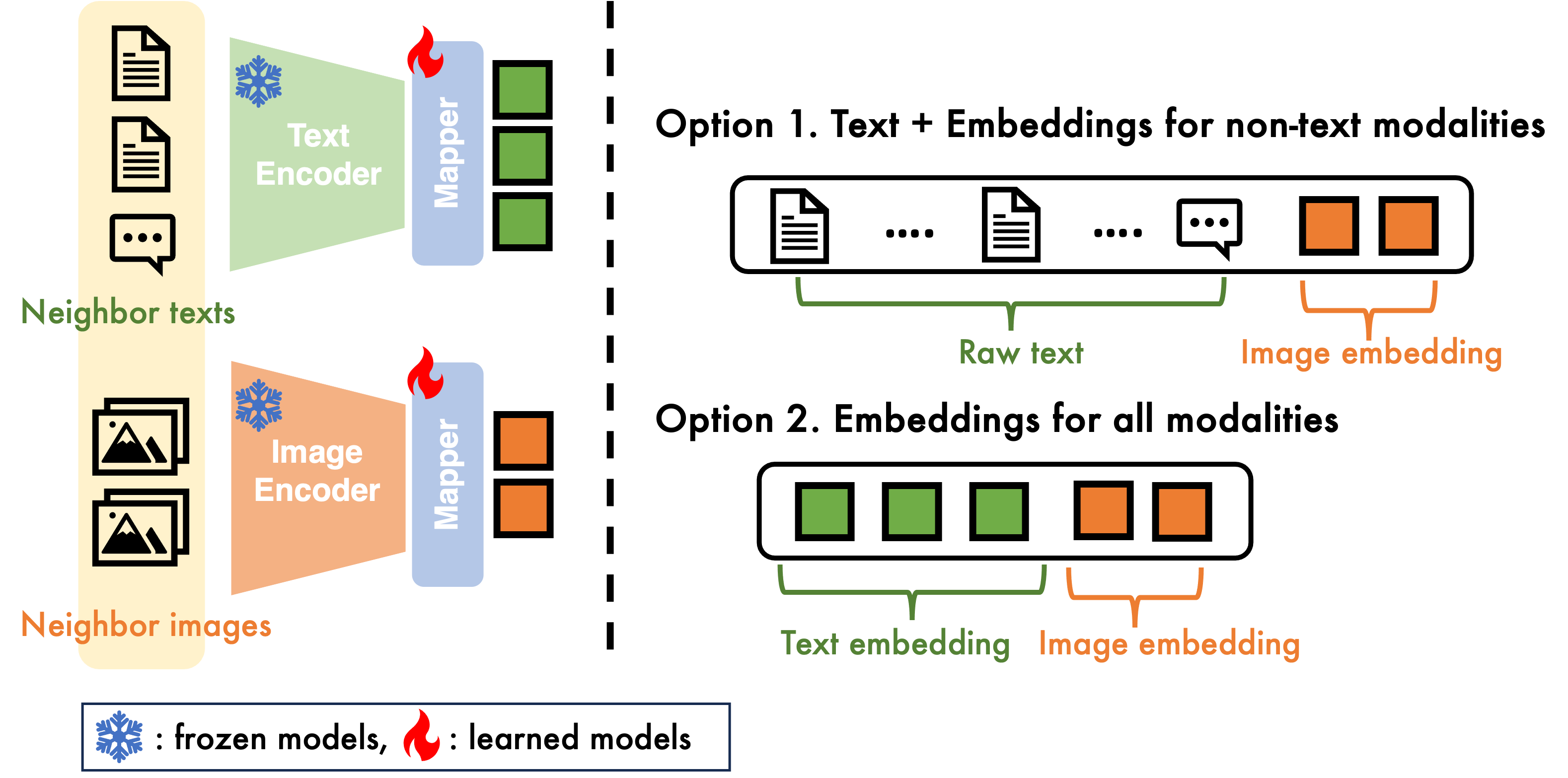
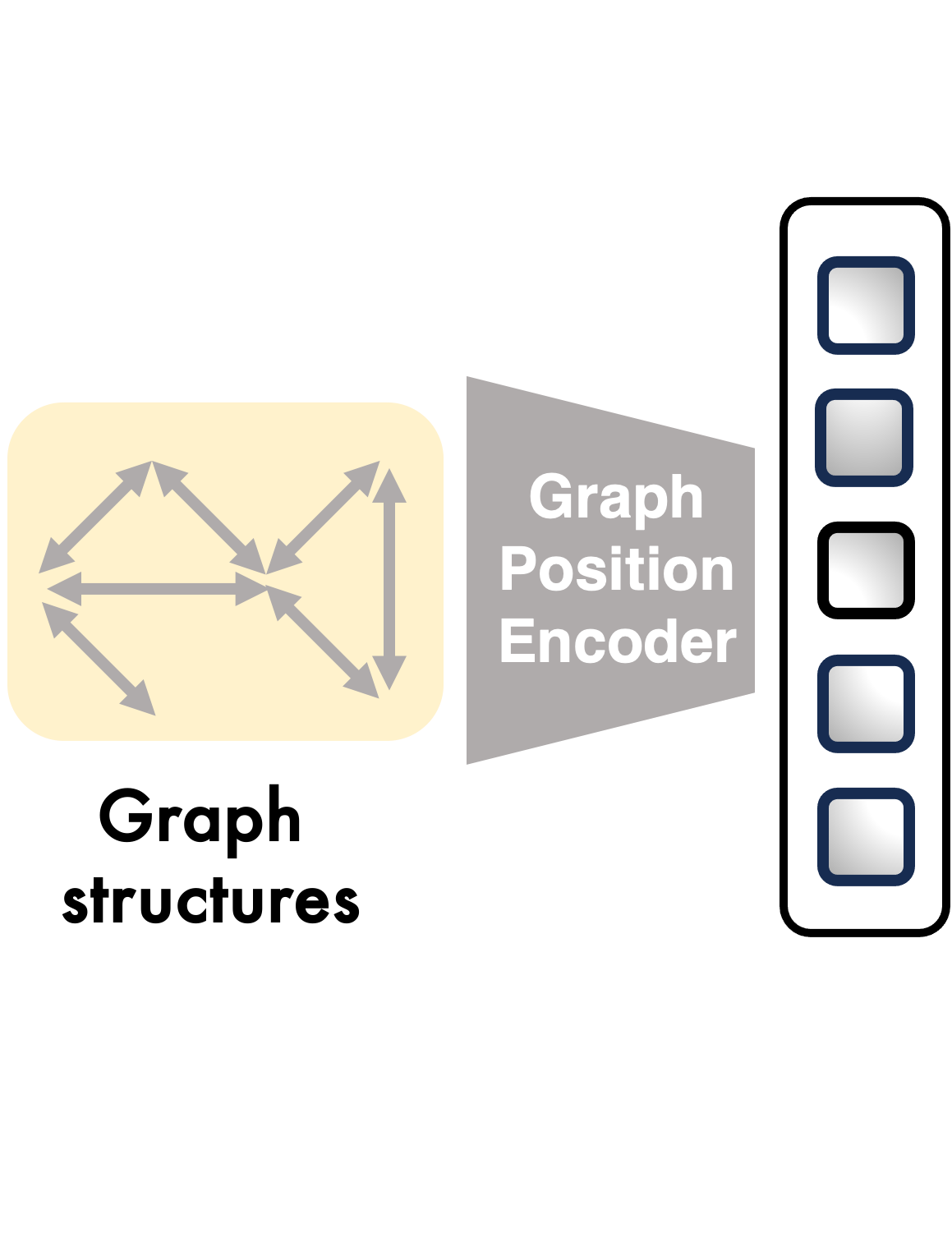
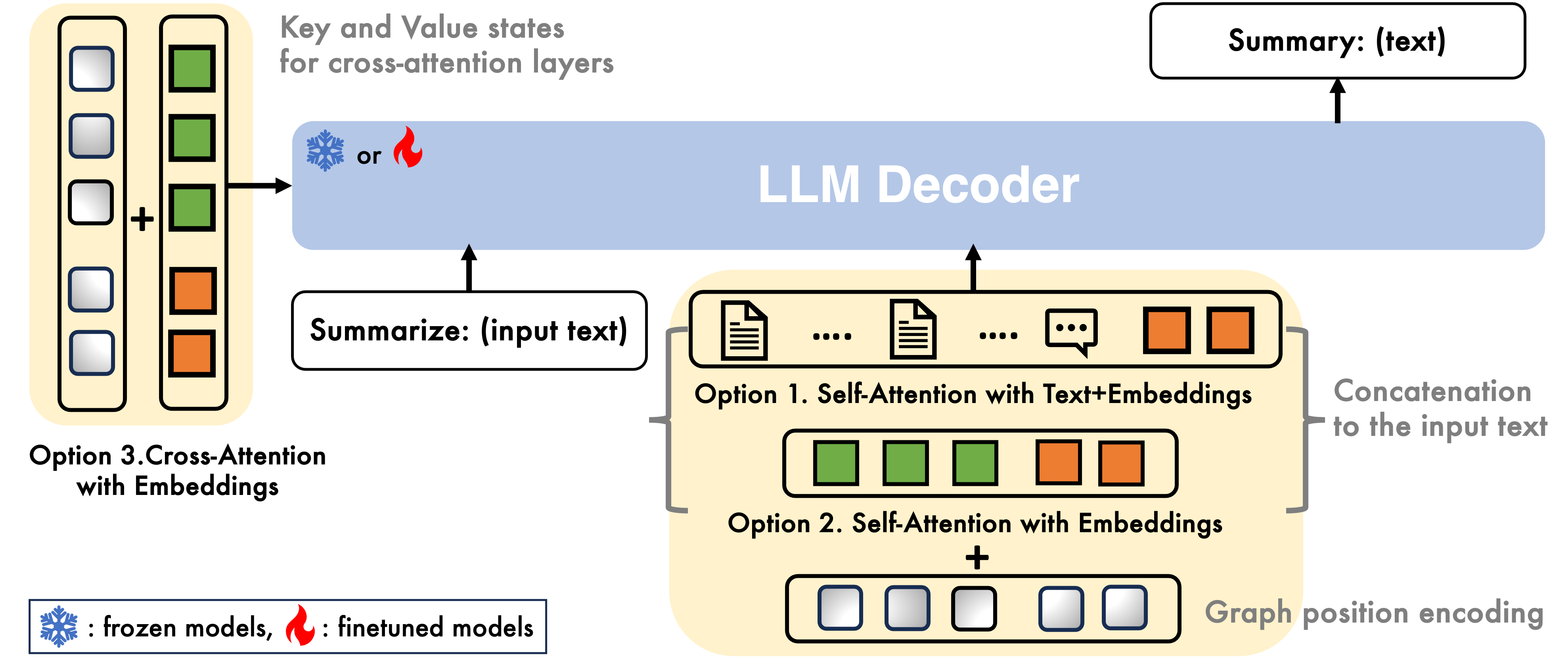
Figure 2: MMGL framework demonstrating multimodal neighbor encoding, graph structure processing, and text generation phases.
Parameter Efficiency
Given the substantial computational demands of full LM fine-tuning, the paper evaluates parameter-efficient fine-tuning (PEFT) techniques including Prefix Tuning, Low-Rank Adaptation (LoRA), and Flamingo-style tuning. These methods strategically trim the number of trainable parameters, effectively reducing computational costs without substantially sacrificing performance. The findings highlight that LoRA generally enhances performance relative to Prefix tuning, while Flamingo-style tuning proves particularly adept when combined with CA-E encoding.
Experiments and Results
The paper presents extensive empirical analysis using the WikiWeb2M dataset, specifically focusing on the section summarization task. This dataset presents a rich multimodal structure that challenges traditional one-to-one mapping paradigms and is perfectly suited for demonstrating the capabilities of the MMGL framework. The results unequivocally exhibit the benefits of incorporating multimodal neighbor information for improved generative performance, underscoring the MMGL framework's ability to harness complex inter-modal data.
Key findings illustrate that SA-TE achieves the highest generative performance, benefiting from detailed input data at the cost of computational burdens. GNN-based graph encoding further enriches this process by injecting structural context into the data fed to pretrained LMs. Moreover, employing Flamingo tuning with CA-E encoding optimizes model performance, marrying parameter efficiency with computational gains.
Conclusion
The research introduces a comprehensive framework for Multimodal Graph Learning tailored for generative tasks, establishing a foundation for future exploration into multimodal data processing. By advancing the state-of-the-art in encoding complex multimodal relationships and optimizing parameter efficiency in large models, this paper paves the way for scalable, robust generative LMs that can better interpret and generate text from rich multimodal information contexts. This work not only enhances current multimodal capabilities but also opens avenues for further research into addressing challenges like information loss, missing modality robustness, and improving scalability without performance trade-offs.

