- The paper introduces the Scissorhands algorithm that compresses the KV cache for LLMs by exploiting the persistence of importance hypothesis.
- It employs a mechanism similar to reservoir sampling and LRU cache replacement to prune non-influential tokens and preserve key ones.
- Empirical results show up to a 5× memory reduction with minimal accuracy loss, enabling efficient deployment in memory-constrained setups.
Scissorhands: Exploiting Persistence of Importance for LLM KV Cache Compression
Introduction
The research article "Scissorhands: Exploiting the Persistence of Importance Hypothesis for LLM KV Cache Compression at Test Time" (2305.17118) addresses a significant challenge in the deployment of LLMs: the substantial memory usage associated with key-value (KV) cache during autoregressive inference. The study builds upon the observation that only pivotal tokens, which have a significant impact at one step, continue to exert influence at future steps. This hypothesis—termed the Persistence of Importance—forms the basis for the Scissorhands compression algorithm, which compresses the KV cache without fine-tuning the model, achieving up to a 5× memory reduction while maintaining model quality.
KV Cache Memory Bottleneck
LLMs such as OPT-175B necessitate a vast memory footprint due to both model weights and the KV cache. The KV cache, exceeding model weights in terms of memory requirements, significantly restricts batch sizes during inference—an essential factor for high throughput. The paper illustrates that at batch size 128 and sequence length 2048, the memory used by the KV cache can triple the model size (Figure 1).
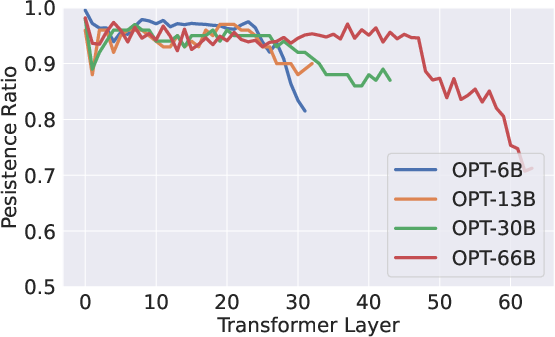
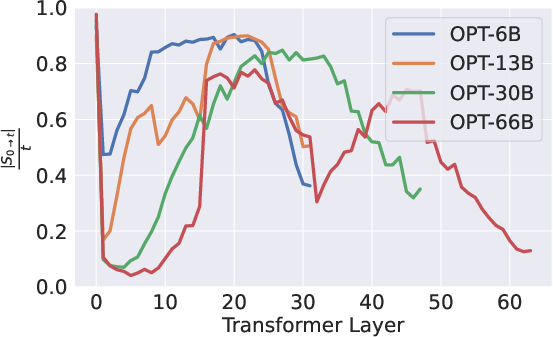
Figure 1: The persistence ratio remains over 95% through most layers, with a pivotal token set considerably smaller than the sequence length.
Quantization techniques have been explored to reduce model sizes but compressing the KV cache while preserving sequence length dimensions remains elusive. The persistence of importance hypothesis offers insight into selecting influential tokens—those receiving high attention scores—and discarding others to streamline cache memory usage.
Methodology: Scissorhands Algorithm
Persistence of Importance Hypothesis
Empirical observations demonstrate repetitive attention patterns, where specific tokens repeatedly receive high attention scores across token positions and layers (Figures 3-6). This repetitive behavior suggests that certain tokens consistently influence the attention mechanism, validating the hypothesis.



Figure 2: Attention map at Layer 5.
The hypothesis posits that pivotal tokens, once influential, remain significant throughout subsequent processing steps, allowing foresight into which tokens will maintain importance in future generations.
Compression Approach
Scissorhands employs an algorithm akin to reservoir sampling and least recently used cache replacement to maintain the KV cache under a predetermined budget. When the cache threatens to exceed this budget, less influential tokens—as determined by historical attention scores—are pruned, while recent tokens are preserved due to insufficient information on their relevance. This results in a reduced memory footprint without degradation in attention precision, as attention scores produced by Scissorhands closely resemble those of the uncompressed cache (Figure 3).
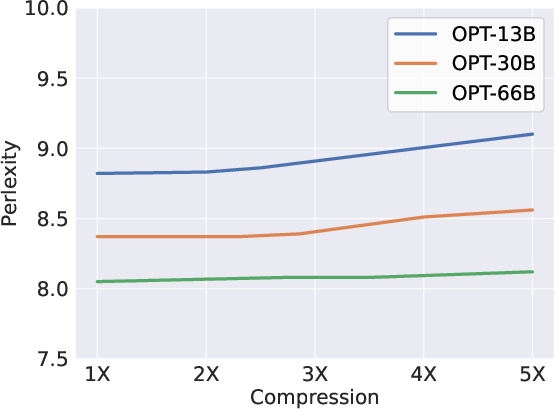
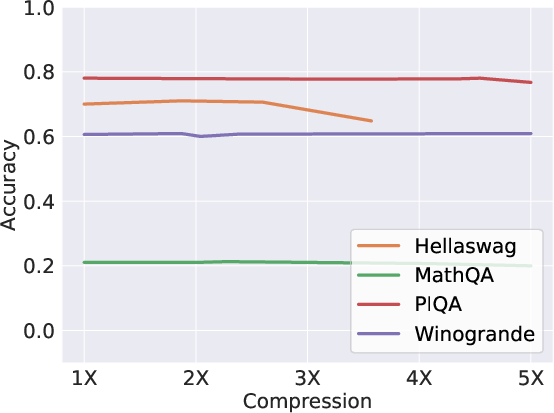
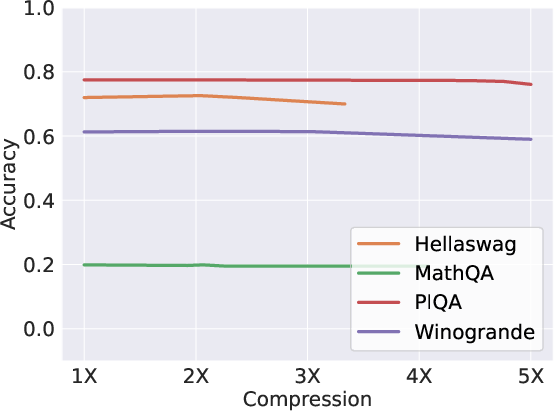
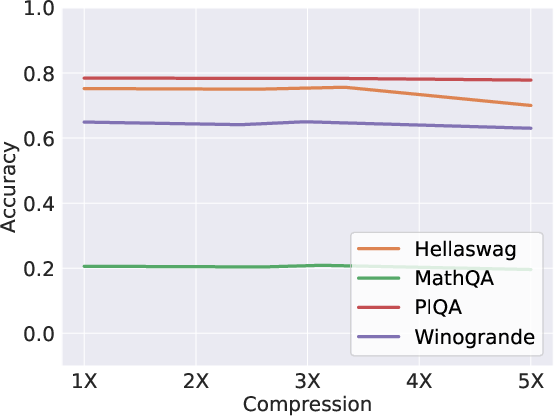
Figure 3: Scissorhands shows no accuracy drop until 5× compression on OPT-66B.
Incorporating factors such as batch size and sequence length, the algorithm adapts checkpoints to distribute memory budgets sensibly across layers and heads, emphasizing later layers with lower persistence ratios.
Empirical Evaluation
The empirical results validate Scissorhands' efficacy, demonstrating no significant model quality loss across language modeling and few-shot downstream tasks until reaching substantial compression rates (Figure 3). Additionally, Scissorhands exhibits compatibility with 4-bit quantization—critical for further reducing memory demands.
Implications and Future Work
Scissorhands' approach to reducing KV cache memory offers a promising avenue for deploying LLMs on constrained hardware setups without sacrificing inference throughput or quality. The study stimulates further exploration into understanding whether the repetitive attention patterns arise from inherent architectural biases or training-related phenomena. Future work could explore extending these findings to larger models and investigating potential correlations between attention behavior and generation quality issues, like repetitions or undesired outputs.
Conclusion
The research presents Scissorhands, leveraging the persistence of importance hypothesis to achieve a remarkable reduction in KV cache memory usage during LLM inference. This contribution supports more efficient and scalable deployment of LLMs, marking a significant step forward in the optimization of AI systems, particularly within environments constrained by memory budgets.