- The paper introduces a novel pyramidal information funneling approach that dynamically compresses KV cache in transformer layers to optimize memory usage.
- It employs dynamic cache allocation and selective retention of KV states based on attention scores, ensuring crucial information is preserved.
- Experimental results on the LongBench benchmark show that PyramidKV maintains performance with only 12% of the full cache size, enhancing long-context processing.
Introduction
The paper "PyramidKV: Dynamic KV Cache Compression Based on Pyramidal Information Funneling" presents a novel approach to enhance memory efficiency in LLMs by utilizing pyramidal information funneling. This technique addresses the crucial challenge of handling long-context inputs in LLMs while minimizing memory usage. It focuses on optimally compressing the key-value (KV) cache across different layers in transformer-based LLMs.
The cornerstone of PyramidKV is the concept of Pyramidal Information Funneling, where attention is initially dispersed across a broad spectrum in lower layers and gradually narrows to focus on crucial tokens in the higher layers. This model of information progression suggested that the KV cache can be dynamically adjusted across layers, allocating more resources in the lower layers where attention is widespread, and less in the higher layers where attention is concentrated.
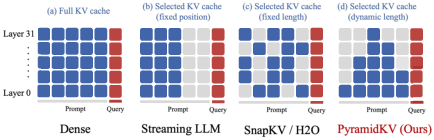
Figure 1: Illustration of ~PyramidKV compared with existing KV cache compression methods.
By adopting this pyramidal structure, PyramidKV deviates from traditional methods that uniformly distribute KV cache across layers, offering a more memory-efficient solution without sacrificing model performance.
Methodology
PyramidKV comprises two key elements: dynamic cache size allocation and specific KV selection.
Dynamic Cache Allocation
PyramidKV allocates an uneven cache budget across layers, based on the principle established by the pyramidal attention pattern. More cache space is provided to the lower layers, where information is scattered over a wide range, while the cache size diminishes through successive layers, reflecting increased attention focus.
Selection of KV States
The selection of KV states to retain is based on the level of attention each token receives from critical "instruction tokens." The method carefully chooses which tokens' KV states to maintain in the cache, leveraging attention scores to retain only the most relevant states, particularly those which receive significant attention from critical downstream tokens.
Experimental Results
Experiments conducted with PyramidKV reveal significant advancements in maintaining model performance with reduced memory usage. Utilizing the LongBench benchmark, PyramidKV demonstrates the ability to match full KV cache performance while retaining only 12% of the cache size in a memory-optimized scenario, and notably outperforming other baseline KV compression methods like H2O and SnapKV.
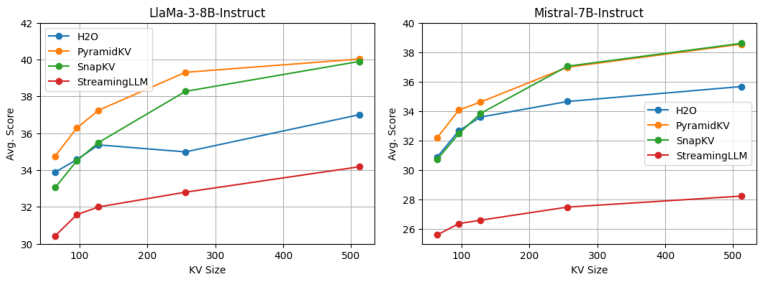
Figure 2: The evaluation results from LongBench demonstrate PyramidKV's superior performance across cache sizes.
The evaluations confirm that PyramidKV leads to substantial improvements in memory efficiency with minimal impact on task performance, proving highly effective in environments where memory resources are constrained.
Long-Context Understanding
PyramidKV has been shown to mitigate the negative effects of cache compression on long-context understanding, which is critical for tasks demanding extensive context processing. In the Fact Retrieval Across Context Lengths test (Figure 3), PyramidKV sustains LLMs' retrieval ability better than competing methods, which is essential for real-world applications involving long-context inputs.
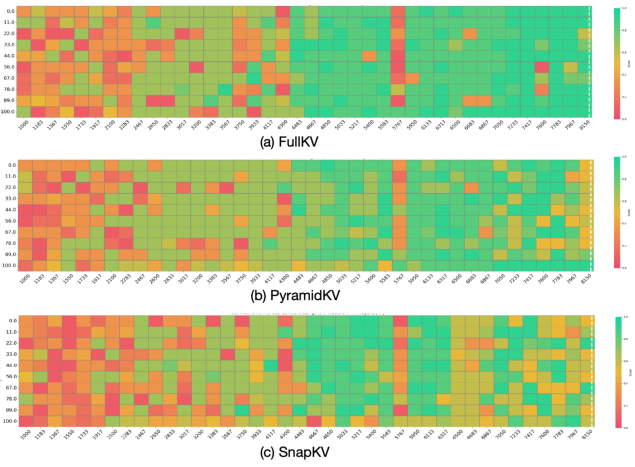
Figure 3: Results of the Fact Retrieval Across Context Lengths (``Needle In A HayStack'') test showing PyramidKV's superior performance.
Conclusion
PyramidKV offers a significant step forward in optimizing memory usage in LLMs. By dynamically adjusting cache sizes based on pyramidal attention patterns, it achieves an efficient balance between performance and resource allocation. This method not only facilitates better memory management in LLMs but opens avenues for future research into more nuanced and adaptive cache strategies that cater to varying computational demands. The implications for real-world deployment of LLMs are profound, especially in resource-constrained settings. This work sets a foundational step for more intelligent and resource-efficient LLM operation.