Abstract
We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters~(LoRA). Our best model family, which we name Guanaco, outperforms all previous openly released models on the Vicuna benchmark, reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of finetuning on a single GPU. QLoRA introduces a number of innovations to save memory without sacrificing performance: (a) 4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights (b) double quantization to reduce the average memory footprint by quantizing the quantization constants, and (c) paged optimziers to manage memory spikes. We use QLoRA to finetune more than 1,000 models, providing a detailed analysis of instruction following and chatbot performance across 8 instruction datasets, multiple model types (LLaMA, T5), and model scales that would be infeasible to run with regular finetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA finetuning on a small high-quality dataset leads to state-of-the-art results, even when using smaller models than the previous SoTA. We provide a detailed analysis of chatbot performance based on both human and GPT-4 evaluations showing that GPT-4 evaluations are a cheap and reasonable alternative to human evaluation. Furthermore, we find that current chatbot benchmarks are not trustworthy to accurately evaluate the performance levels of chatbots. A lemon-picked analysis demonstrates where Guanaco fails compared to ChatGPT. We release all of our models and code, including CUDA kernels for 4-bit training.
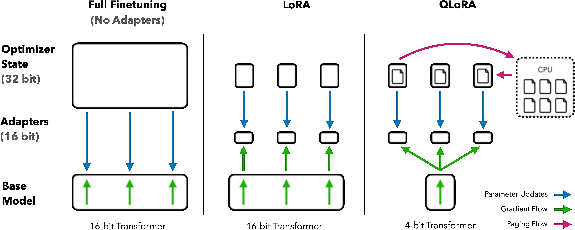
Overview
-
QLoRA introduces an efficient fine-tuning method for LLMs using quantization and Low-Rank Adapters to reduce memory requirements.
-
The approach employs 4-bit NormalFloat quantization, Double Quantization, and Paged Optimizers to manage memory usage effectively.
-
The study tested QLoRA's efficacy on over 1,000 models, achieving state-of-the-art performance while underlining the importance of fine-tuning data quality.
-
A new benchmarking system is proposed to assess chatbot performance, and existing benchmarks are scrutinized for inconsistencies.
-
All materials, including models and code, are made publicly available, promoting transparency and broadened access to advanced LLM fine-tuning.
Introduction
The evolution of LLMs demonstrates their potential in handling complex tasks across numerous domains. One way to enhance LLMs' capabilities is through fine-tuning, a process of adjusting an already pre-trained model to perform specific tasks better. However, this process usually demands a significant amount of computational resources, particularly memory, making it challenging for many researchers and developers to fine-tune larger models effectively.
Efficient Fine-Tuning Method
A recent study presents a novel fine-tuning approach that can alleviate the memory burden when fine-tuning large LLMs. By cleverly combining quantized 4-bit model weights with the augmentation of Low-rank Adapters, the method, referred to as QLoRA, manages to fine-tune models with billions of parameters using much less memory, without sacrificing performance.
QLoRA incorporates several innovative techniques to achieve this efficiency. The first is the introduction of a new data type called 4-bit NormalFloat (NF4), optimized for normally distributed weights and provides better results than previous quantization types. The second is Double Quantization, a strategy to further reduce memory overhead by compressing the constants used in the first round of quantization. Lastly, Paged Optimizers utilize a feature in NVIDIA's computational platform to handle memory spikes during training, effectively preventing out-of-memory errors which are common in large-scale fine-tuning.
Performance Evaluation
The efficacy of QLoRA is tested extensively. The team fine-tuned more than 1,000 models, utilizing a range of instruction datasets and model scales, with parameters ranging from millions to tens of billions. The Guanaco model family, fine-tuned using QLoRA, achieved state-of-the-art results on various benchmarks, competing closely with high-profile models like ChatGPT. Moreover, evaluations indicated that the quality of the fine-tuning dataset had a more substantial impact on the model's performance than its size, highlighting the importance of fine-tuning data selection.
Evaluation and Model Release
The paper proposes a new tournament-style benchmarking system, which uses both human annotators and automated GPT-4 evaluations for more robust chatbot performance assessment. Furthermore, the team conducted a thorough analysis of current chatbot benchmarks and found significant inconsistencies. They argue for reassessing the methods used to rank chatbot quality.
In a step towards greater transparency and accessibility, all models, code, and new CUDA kernels are released for public use. This includes a collection of adapters trained on multiple datasets for various model sizes, making advanced fine-tuning accessible to the broader AI community and potentially democratizing access to high-performance LLM use.
Conclusion
Through QLoRA, fine-tuning massive LLMs becomes significantly more feasible, requiring less memory and enabling the use of sophisticated models on consumer-grade hardware. This advancement not only propels research forward by providing state-of-the-art LLMs but also addresses key concerns regarding the accessibility and practicality of fine-tuning large models. The ripple effects of such an efficient fine-tuning method are poised to impact the development and deployment of AI applications positively.