Optimizing Loss Functions Through Multivariate Taylor Polynomial Parameterization
Published 31 Jan 2020 in cs.LG, cs.NE, and stat.ML | (2002.00059v4)
Abstract: Metalearning of deep neural network (DNN) architectures and hyperparameters has become an increasingly important area of research. Loss functions are a type of metaknowledge that is crucial to effective training of DNNs, however, their potential role in metalearning has not yet been fully explored. Whereas early work focused on genetic programming (GP) on tree representations, this paper proposes continuous CMA-ES optimization of multivariate Taylor polynomial parameterizations. This approach, TaylorGLO, makes it possible to represent and search useful loss functions more effectively. In MNIST, CIFAR-10, and SVHN benchmark tasks, TaylorGLO finds new loss functions that outperform functions previously discovered through GP, as well as the standard cross-entropy loss, in fewer generations. These functions serve to regularize the learning task by discouraging overfitting to the labels, which is particularly useful in tasks where limited training data is available. The results thus demonstrate that loss function optimization is a productive new avenue for metalearning.
The paper introduces TaylorGLO, which parameterizes loss functions as multivariate Taylor polynomials to enable smooth, continuous optimization.
It leverages evolutionary strategies (CMA-ES) to efficiently search and prune the parameter space, achieving faster convergence than traditional tree-based methods.
Empirical results on MNIST, CIFAR-10, and SVHN demonstrate improved accuracy, lower variance, and enhanced regularization, especially in data-scarce regimes.
Loss Function Metalearning with Multivariate Taylor Polynomial Parameterization
Introduction
"Optimizing Loss Functions Through Multivariate Taylor Polynomial Parameterization" (2002.00059) introduces TaylorGLO, a metalearning approach leveraging multivariate Taylor polynomial expansions for loss function discovery and optimization in deep neural network (DNN) training. The paper formally frames the search for improved loss functions as a parameter optimization task in a smooth, continuous space, circumventing the discrete, combinatorial inefficiencies and instability inherent in earlier techniques such as Genetic Loss Optimization (GLO), which relied on tree-based representations and genetic programming for loss function topologies.
Related Work and Motivation
Conventional metalearning has typically focused on hyperparameters and neural architectures, but recent progress indicates that other differentiable components—most critically, loss functions—are tractable and promising targets for meta-optimization. Previous work (notably GLO) successfully obtained superior loss functions (e.g., Baikal) versus standard cross-entropy, but its two-stage process (first discrete structure search, then real coefficient search) was computationally expensive, fragile with respect to mutation, and frequently produced pathological, ill-defined candidates. TaylorGLO circumvents these limitations via direct parameterization of loss functions as multivariate Taylor polynomials, enabling smooth, locally navigable fitness landscapes and guaranteed differentiability.
Multivariate Taylor Parameterization of Loss Functions
TaylorGLO models a candidate loss as a low-order (typically third-order) multivariate Taylor expansion in terms of predicted output and reference label, with all cross and higher order terms, parameterized by vector θ. The method enforces only smooth, pole-free, finitely parameterized polynomial losses, which have desirable computational and optimization properties. The dimensionality of the parameterization is kept manageable, and the method trivially supports generalizations beyond bivariate settings, e.g., including time, batch statistics, or intermediate activations as additional arguments. This formalization ensures local smoothness in the search space, robust gradients for DNN training, and the capacity for loss shape evolution that aligns with the empirical gradient flow required for highly effective regularization.
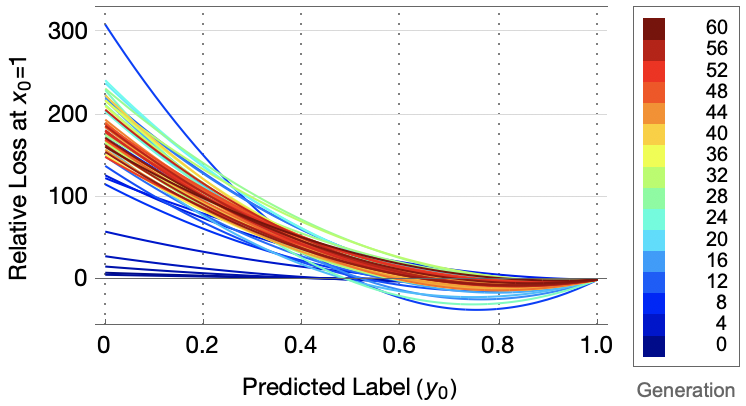
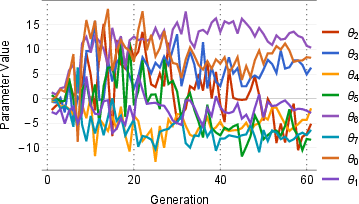
Figure 1: Generational progression of the best loss functions (a) and their parameters (b) on MNIST, with the loss plotted against predicted output for the correct class.
Optimization via Evolution Strategies
Unlike GLO, which operated in a discrete tree-graph space, TaylorGLO exploits the continuity of its parameterization, applying Covariance Matrix Adaptation Evolutionary Strategy (CMA-ES) for black-box optimization of the loss parameters. Fitness is based on validation accuracy after partial training, and candidate evaluation is robustly parallelized. Redundant or degenerate parameters (those whose derivative vanishes with respect to prediction) are pruned, reducing search space dimensionality. This synergy with CMA-ES results in orders of magnitude faster convergence and improved solution quality compared to tree-based alternatives.
Empirical Evaluation
TaylorGLO is comprehensively evaluated on MNIST, CIFAR-10, and SVHN, using multiple standard architectures (basic CNN, AlexNet, AllCNN-C, preactivation ResNet-20, Wide ResNet variants). Baselines are strictly the canonical cross-entropy loss and previously-evolved losses such as Baikal. Statistical analysis is conducted over 10 runs per comparison. TaylorGLO consistently yields higher accuracy, lower variance, and improved generalization, especially with limited data regimes where regularization is more critical.
Noteworthy findings include:
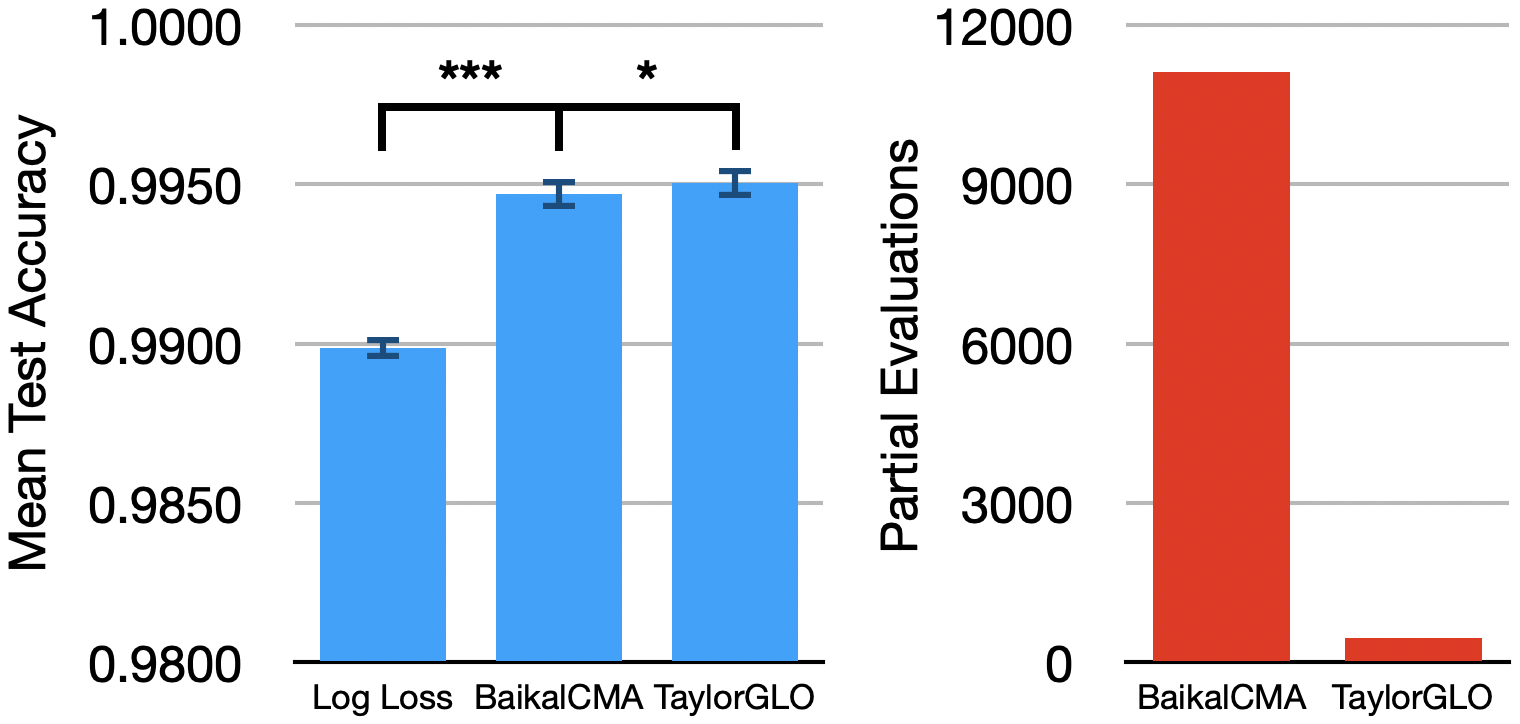
On MNIST, TaylorGLO discovers loss functions yielding a mean test accuracy of 0.9951, compared to 0.9899 for cross-entropy (p = 2.95×10−15), and does so with only 4% the number of candidate evaluations required by GLO.
TaylorGLO's improvements persist even when established data augmentation and regularization techniques (such as Cutout) are used, indicating a complementary, not redundant, mechanism.
Figure 2: TaylorGLO loss functions on MNIST significantly outperform both cross-entropy and previously-evolved BaikalCMA losses. The right subplot highlights TaylorGLO's optimization efficiency (∼25× reduction in partial evaluations).
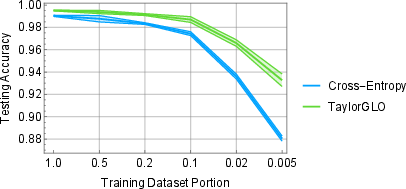
On CIFAR-10 and SVHN using Wide ResNets, TaylorGLO outperforms cross-entropy with strong statistical significance in most evaluated regimes, with performance gains amplified on smaller data splits.
Analysis of Evolved Loss Functions
Inspection of evolved loss functions reveals a counterintuitive structure: final losses punish predicted probabilities near, but not at, 1.0 for the correct class. The loss curve attains a minimum not at y0=1, but slightly before. This deviation from cross-entropy's monotonic decrease encourages the model to resist overconfident outputs, implicitly regularizing the training and improving generalization, especially in low-data settings.
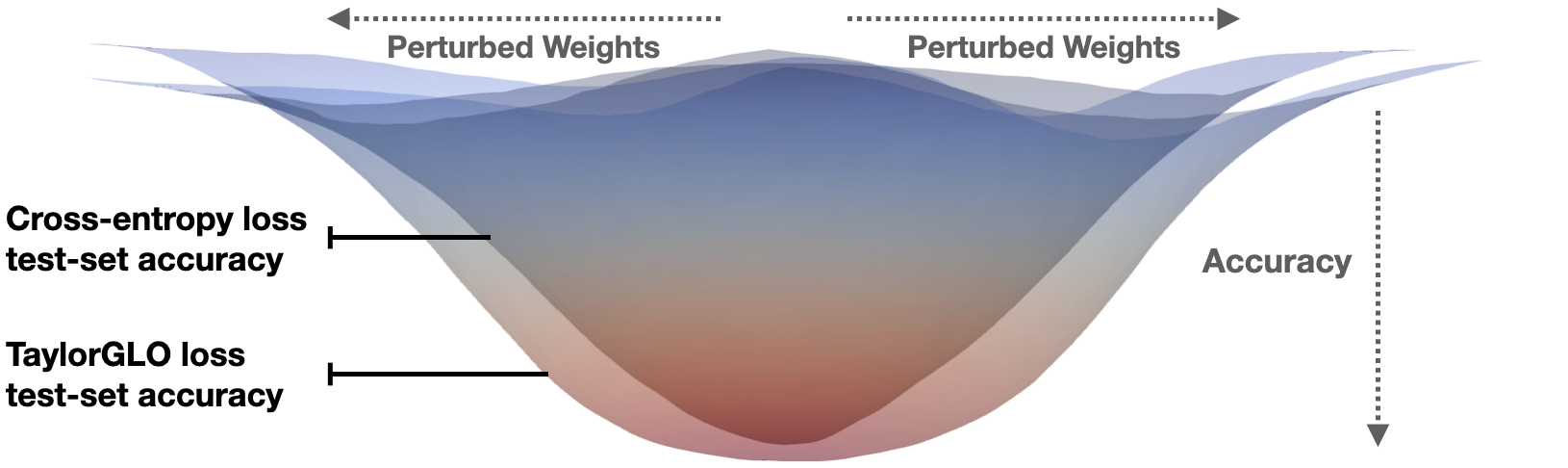
Figure 3: Loss landscape "basins" comparison on AllCNN-C: TaylorGLO-trained models exhibit flatter, wider minima, indicating increased robustness and improved generalization capacity.
Efficiency and Evolutionary Dynamics
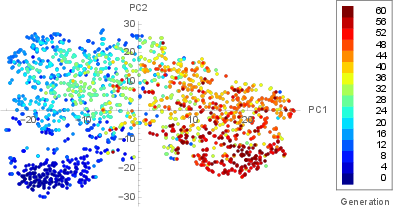
TaylorGLO's parameter space enables efficient and rapid exploration. Evolutionary trajectories demonstrate smooth population migration towards narrow function bands with desirable characteristics. t-SNE visualizations confirm the population's focused convergence.
Figure 4: All TaylorGLO candidate losses on MNIST visualized with t-SNE, demonstrating convergence towards high-performing regions over generations.
Implications and Future Directions
TaylorGLO establishes that direct optimization of smooth, parameterized loss functions, rather than architecture or hyperplots alone, can produce practical, statistically significant gains in DNN performance. These gains arise not merely from improved optimization, but from regularization effects inaccessible to classical losses or even prevalent regularization techniques.
Practical implications include:
Data-starved regimes: TaylorGLO's evolvable losses especially benefit settings with limited labeled data, reflecting a robust tendency to avoid overfitting.
Automation in ML pipeline: Loss function metalearning becomes feasible as a routine, computationally affordable meta-optimization, upstream from hyperparameter or architecture search.
Synergistic regularization: Combination with methods such as dropout or Cutout provides additive generalization benefits.
Theoretical implications and open directions encompass:
Loss function architecture co-evolution: Simultaneous metalearning of loss, architecture, and optimization procedure may yield non-additive improvements.
State or context-dependent losses: Incorporating training progress, batch statistics, or Hessian-based features into the loss function could enable self-adaptive loss scheduling or dynamic regularization within the training process.
Transferability and generalization of evolved losses: Characterizing which evolved losses transfer between tasks or architectures remains an open research frontier.
Conclusion
TaylorGLO advances the theory and practice of loss function optimization by harnessing a flexible, polynomial parameterization and efficient, smooth-space evolutionary search. Its empirical superiority—across architectures, datasets, and under regularization—establishes loss function discovery as a critical, practical lever in the metalearning toolbox. This framework opens the path to automated, data-driven derivation of optimization objectives, with potential for new forms of regularization and generalization previously inaccessible through manual engineering or less principled meta-optimization schemes.