- The paper introduces a data-efficient visual servoing algorithm that leverages deep visual features to improve generalization and robustness in robot control.
- It employs a multiscale bilinear predictive model combined with fitted Q-iteration reinforcement learning to optimize feature dynamics under varying conditions.
- Experimental results demonstrate over two orders of magnitude improvement in sample efficiency and reliable adaptation to diverse environments compared to traditional methods.
Learning Visual Servoing with Deep Features and Fitted Q-Iteration
Introduction
In "Learning Visual Servoing with Deep Features and Fitted Q-Iteration," the authors address the complex task of visual servoing using a combination of learned visual features, predictive dynamics models, and reinforcement learning. Visual servoing traditionally involves controlling robot motion based on feedback from visual sensors to achieve a desired configuration. Despite conventional methods relying on handcrafted features and model-driven approaches, these systems fall short in generalization across varied environments and require extensive manual design.
The paper proposes a data-efficient algorithm for visual servoing, specifically targeting object-following problems. By using learned deep features, rather than raw image data or manually derived keypoints, the approach aims to enhance adaptability to new environments and reduce dependency on large-scale data collection.
Methodology
Use of Deep Features
The authors utilize deep visual features obtained from the VGG network trained on the ImageNet dataset as the building blocks for the servoing system. The rationale is that these features encapsulate broad semantic information, enabling the model to work robustly under conditions of occlusion, varying lighting, and different viewpoints.
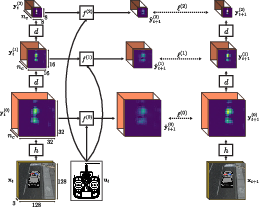
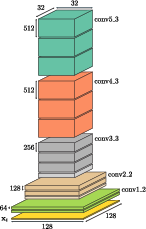
Figure 1: Multiscale bilinear model. The function $\h{}$ maps images x to feature maps $\y[0]{}$, the operator $\d{}$ downsamples the feature maps, and the bilinear function $\f[l]{}$ predicts the next feature $\ypred[l]{}$.
Predictive Dynamics Model
The system integrates a multiscale learning framework that predicts the dynamics across multiple levels of resolution. A bilinear model is applied at each scale to approximate interactions between features and control actions. This model improves upon previous rigid formulations by offering sparse local connections, which simplify parameterization and enhance computational efficiency.
Fitted Q-Iteration
Central to the visual servoing strategy is a fitted Q-iteration based reinforcement learning algorithm, which optimizes feature weights for servoing by minimizing the Euclidean distance between predicted and target features. The procedure leverages a linear analytic approximator for the Q-function, resulting in computationally efficient updates that reinforce favorable long-term behavior of the system.
Experimental Results
Experiments are conducted in synthetic environments simulating task conditions such as target following by aerial drones. Evaluation metrics highlight sample efficiency and generalization capabilities across both seen and unseen scenarios.
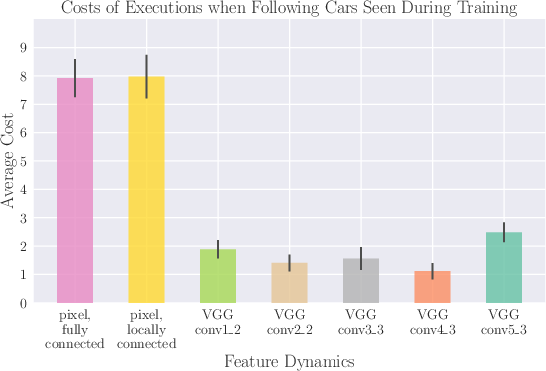
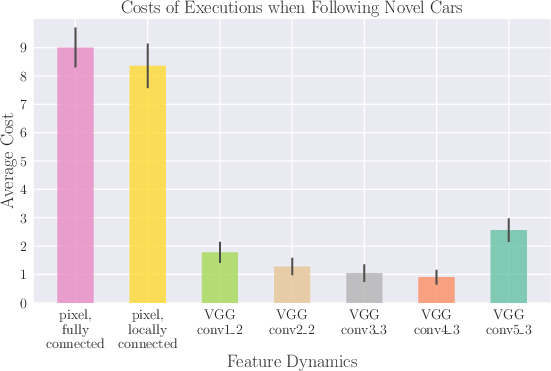
Figure 2: Costs of test executions using various feature dynamics models, demonstrating generalization on novel cars.
The analysis demonstrates that the proposed visual servoing mechanism outperforms conventional techniques based on image pixels and manually-designed features, achieving a notable increase in sample efficiency over model-free deep reinforcement learning approaches. Furthermore, the model successfully adapts to new object targets with minimal data requirements, showcasing a stark advantage in sample efficiency—over two orders of magnitude compared to prior works.
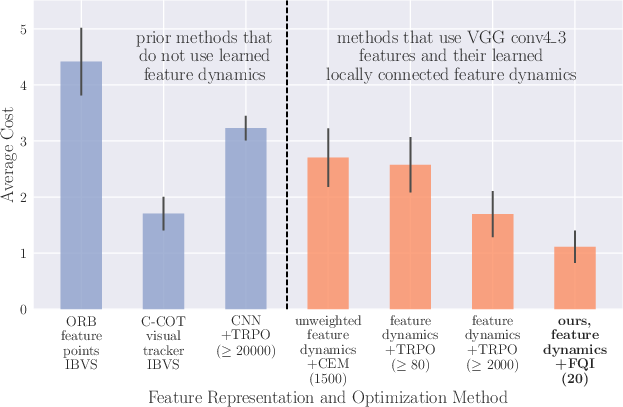
Figure 3: Comparison of costs on test executions of prior methods against our method.
Conclusion
This work underscores a significant progression in learning-driven visual servoing tasks by harnessing deep features and reinforcement learning mechanisms. The proposed methodology achieves marked improvements in robustness and efficiency, suggesting a scalable path to dealing with the inherent variability of real-world robot perception-action loops. Future developments may refine the integration of predictive models with visual learning processes, as exploration in larger, more diverse settings continues.