- The paper introduces a deep learning approach that predicts future video frames to plan robot motion for object manipulation.
- It leverages a convolutional LSTM network and stochastic pixel flow predictions for dynamic, calibration-free manipulation.
- The method utilizes sampling-based MPC with cross-entropy optimization to select actions that handle novel object scenarios.
Deep Visual Foresight for Planning Robot Motion
Introduction
The paper introduces an innovative approach to robotic manipulation using deep learning models that predict future video frames, aimed at planning robot motions for tasks such as object pushing. This methodology leverages deep neural network-based prediction models to perform actions like moving objects to desired locations with minimal prior inputs, such as camera calibration or 3D object modeling, which are traditionally required. The overarching goal of the research is to enable robots to perform manipulation tasks under the real-world complexity of dynamic environments, with the ability to generalize to novel objects not encountered during training.
Visual Imagination and Predictive Models
The proposed method involves using a deep predictive model, trained on large-scale video data, to perform model-predictive control (MPC). The model, a convolutional LSTM network, predicts image sequences conditioned on proposed future actions, thereby enabling the robot to foresee the visual outcome of its actions without requiring explicit feature-based object recognition or detailed physical simulations (Figure 1). By utilizing action-conditioned video predictions, the robot engages in nonprehensile manipulation tasks such as pushing, showcasing inference capabilities on dynamics and object interactions from purely visual inputs.
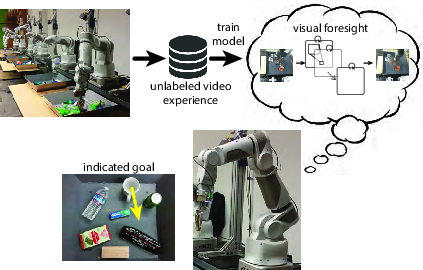
Figure 1: Using our approach, a robot uses a learned predictive model of images, i.e. a visual imagination, to push objects to desired locations.
Technical Implementation
The core technology involves predicting stochastic pixel flow transformations, representing the possible movement of each pixel in future frames following a sequence of inputs. This prediction is achieved through normalized convolution filters that determine probabilistic transition operators across image frames, facilitating the transformation of raw pixels to predict object movements. By iteratively refining this model via maximum likelihood estimation, the network learns to derive flows and masks as emergent properties, essential for compositing different object channels and enabling model-based planning through learned video representation (Figure 2).
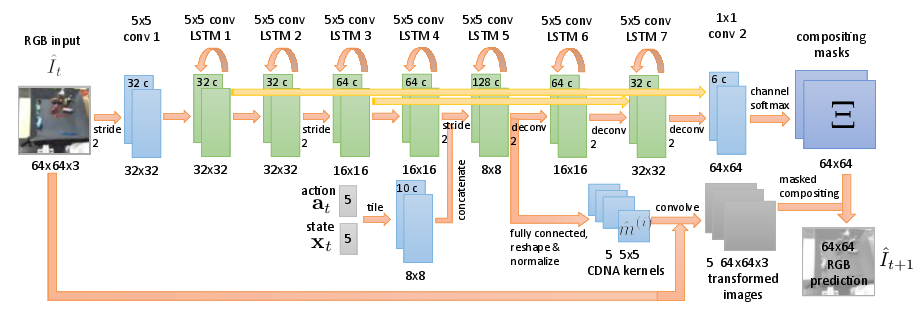
Figure 2: Predictive model forecasts image transformations based on stochastic pixel flow, generating predictions for subsequent frames conditioned on action sequences.
Model Predictive Control and Goal Specification
The algorithm employs a sampling-based MPC approach, using cross-entropy method (CEM) optimization to determine actions that maximize the likelihood of achieving a defined goal, represented as pixel transitions from source to target locations. Through recurrent model evaluation, the method dynamically replans actions, continuously adjusting the robot's movements based on the latest predictions and achieving control without direct calibration or predefined physics usage. Crucially, this paradigm allows the system to adapt to new, unforeseen object manipulations in real-time settings (Figure 3).





Figure 3: Experimental setup includes diverse, previously unseen objects with distinct pushing tasks indicating start and goal pixel locations.
Through experimental evaluations, the methodology demonstrates competent performance in handling tasks involving prediction-driven manipulation of new objects, as well as nuanced motions such as rotations, achieved through pixel-aligned goal specifications. Comparisons with baseline approaches, including random actions and static servoing, underscore the model's capability to capitalize on learned dynamics for effective task execution. Failures such as those caused by occlusions and underestimating physical properties highlight areas for further improvement, suggesting a positive trajectory in robotics driven by advancements in predictive model accuracy (Figure 4).


Figure 4: Varied camera angles in data collection enforce model invariance to positional changes in robot setup, fostering calibration-free manipulation capabilities.
Conclusion
The approach showcased in this paper marks a significant step towards robust robotic manipulation by eschewing classical dependency on explicit environmental modeling. While current results indicate promising performance in relatively straightforward scenarios, the prospect for extended applications through improved predictive model formulations and computational advancements appears viable. Future research should focus on enhancing model robustness, extending planning horizons, and integrating advancements from the broader field of visual forecasting, thereby refining robotic interaction capabilities in diverse, real-world environments.

