Runtime-Aware GPU Scheduling for Multi-Tenant DNN Inference
This presentation explores an automated framework that dramatically improves GPU scheduling for multi-tenant deep neural network inference. By treating scheduling as a concurrency control problem and using machine learning to optimize resource allocation, the researchers achieve 1.3 to 1.7 times faster inference compared to conventional methods like CuDNN and NVIDIA Multi-Stream, with immediate implications for real-time applications like autonomous driving.Script
When an autonomous vehicle processes its camera feed, it is not running one neural network but many simultaneously, all competing for the same GPU resources. Today's scheduling methods leave performance on the table.
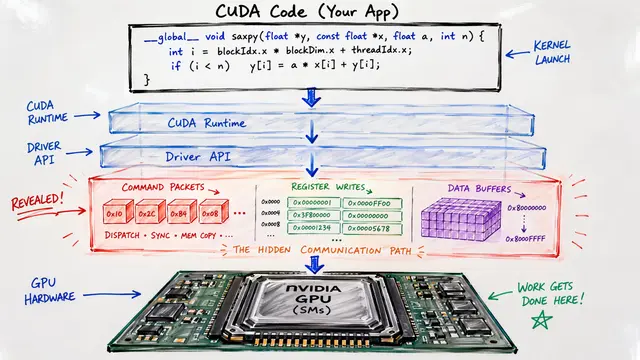
The researchers frame this as a concurrency control problem. Multiple deep neural networks must share GPU streams, and the order in which their operators execute determines whether the hardware sits idle or runs at full capacity.
Their framework uses an automated machine learning search to explore scheduling strategies. It profiles GPU runtime costs for different operator orderings, then selects the schedule that minimizes stalls and maximizes concurrency across all tenants.
A key insight is switching from depth-first to breadth-first operator issuing. Deep chains of operations from one network block other streams, but issuing operators layer by layer keeps all streams active and reduces stalls.
On ImageNet inference across NVIDIA Titan V and P6000 GPUs, the framework delivers 1.3 to 1.7 times speedup over CuDNN and existing multi-stream approaches. The gains come from fine-grained operator concurrency that adapts to each platform's runtime profile.
For applications like autonomous driving where milliseconds matter, smarter GPU scheduling turns waiting time into decision time. Explore more research that bridges systems and intelligence at EmergentMind.com, where you can create videos like this one.