The Dragon Hatchling: The Missing Link between the Transformer and Models of the Brain (2509.26507v1)
Abstract: The relationship between computing systems and the brain has served as motivation for pioneering theoreticians since John von Neumann and Alan Turing. Uniform, scale-free biological networks, such as the brain, have powerful properties, including generalizing over time, which is the main barrier for Machine Learning on the path to Universal Reasoning Models. We introduce `Dragon Hatchling' (BDH), a new LLM architecture based on a scale-free biologically inspired network of \$n\$ locally-interacting neuron particles. BDH couples strong theoretical foundations and inherent interpretability without sacrificing Transformer-like performance. BDH is a practical, performant state-of-the-art attention-based state space sequence learning architecture. In addition to being a graph model, BDH admits a GPU-friendly formulation. It exhibits Transformer-like scaling laws: empirically BDH rivals GPT2 performance on language and translation tasks, at the same number of parameters (10M to 1B), for the same training data. BDH can be represented as a brain model. The working memory of BDH during inference entirely relies on synaptic plasticity with Hebbian learning using spiking neurons. We confirm empirically that specific, individual synapses strengthen connection whenever BDH hears or reasons about a specific concept while processing language inputs. The neuron interaction network of BDH is a graph of high modularity with heavy-tailed degree distribution. The BDH model is biologically plausible, explaining one possible mechanism which human neurons could use to achieve speech. BDH is designed for interpretability. Activation vectors of BDH are sparse and positive. We demonstrate monosemanticity in BDH on language tasks. Interpretability of state, which goes beyond interpretability of neurons and model parameters, is an inherent feature of the BDH architecture.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new kind of AI LLM called “Dragon Hatchling” (BDH). The big idea is to build an AI that thinks more like a brain: lots of simple “neurons” that talk to nearby neighbors, learn by strengthening connections that matter, and can explain what they’re doing while still performing as well as Transformer models like GPT-2. The authors also make a practical version that runs efficiently on GPUs, called BDH-GPU.
Key Questions
The paper asks a few straightforward questions:
- Can we design an AI that reasons over long periods of time more like humans do, instead of getting confused when tasks get longer?
- Is there a direct link between how Transformers use “attention” and how real brains focus and learn?
- Can a brain-inspired model be both understandable and as strong as current LLMs?
- Can we build a version that is fast to train on common hardware (GPUs) and matches GPT-2-level performance?
How It Works (Methods and Approach)
Think of the model as a city of neurons connected by roads (synapses):
- Neurons: Small units that can be active (like turning a light on). They sit at intersections.
- Synapses: The roads between intersections. Some roads get more important (stronger) over time.
The model uses two simple ideas:
- Logic rule (“modus ponens”): If A usually leads to B, then when A is active, it should make B more likely. In everyday terms: “If it’s raining, roads are wet. It’s raining → roads are wet.”
- Hebbian learning (“neurons that fire together wire together”): If A helps trigger B now, the road from A to B gets a bit stronger for next time. Like practicing a skill and getting quicker because your brain strengthens the right connections.
Together, these ideas let the model do two things at once: use known rules to infer new facts, and adjust its rules on the fly based on what just worked. The short-term adjustments live in “fast weights,” which are like working memory.
Two versions:
- BDH (brain-like graph): Information moves along specific roads; state (working memory) sits on the roads between neurons. This is close to how real neurons and synapses work, including “excitatory” and “inhibitory” circuits and “integrate-and-fire” behavior (neurons fire when inputs pass a threshold).
- BDH-GPU (GPU-friendly): Instead of wiring every road individually, neurons “broadcast” like on a radio network. It’s mathematically equivalent in how it behaves but much easier to train on GPUs. BDH-GPU uses:
- Linear attention in a very high neuron dimension.
- A simple feed-forward block with ReLU (a standard AI function that keeps values positive).
- Positive, sparse activations (most neurons are off; a few are strongly active), which makes what the model is doing easier to read.
A helpful analogy: In BDH-GPU, neurons are like club members hearing a message over a speaker. Each neuron decides how much to care (attention), and the network updates which pairs of neurons have “strong friendships” (synapses) based on what just happened.
Main Findings and Why They Matter
The paper reports several results:
- Performance: BDH-GPU matches GPT-2-like Transformer performance on language and translation tasks at the same parameter sizes (from about 10 million up to 1 billion parameters). It follows similar “scaling laws,” meaning larger models predictably get better.
- Interpretability: The model’s activations are positive and sparse. This makes it easier to see which neurons are active and why. They also show “monosemanticity”: certain neurons or synapses consistently represent specific concepts, even in smaller models.
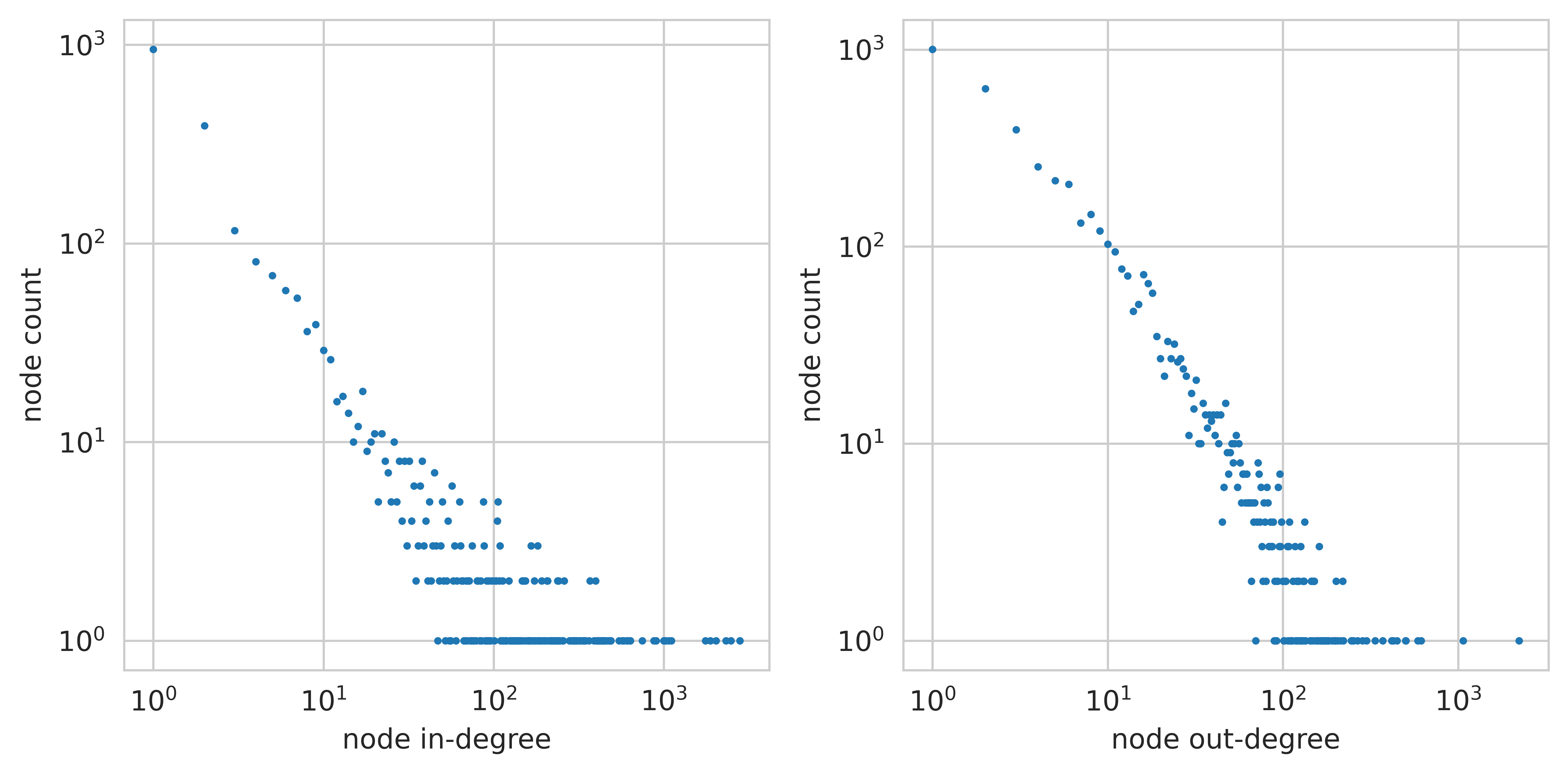
- Brain-like behavior: The network naturally forms clusters (modules) and uses a few highly connected neurons—similar to patterns seen in biological brains.
- In-context learning at synapses: When the model reads or reasons about a specific idea, the same synapses strengthen repeatedly across different prompts. That means you can point to a particular connection and say, “This link is currently storing the idea you’re working with.”
- A bridge between AI and neuroscience: The paper shows a formal match between the attention mechanisms used in LLMs and attention-like behaviors in the brain, all expressible as simple local rules at neurons and synapses.
Why this matters: It suggests a path to AI that is both powerful and predictable. By grounding model behavior in simple, local rules (like a brain), we can better understand and anticipate what the AI will do, especially over longer periods.
Implications and Impact
- Safer long-term reasoning: The authors aim toward “thermodynamic limit” behavior—predictable patterns as models get very large and run for a long time. This could help prevent AI from drifting into weird or harmful behavior when tasks become long or complex.
- Axiomatic AI: Instead of just explaining a model after the fact, this approach builds models with clear micro-foundations (the small local rules) that lead to understandable big-picture behavior. That makes testing and trusting AI easier.
- Neuroscience insights: BDH offers a plausible mechanism for how human neurons might support language using short-term synaptic changes (like working memory), linking attention in AI to attention in the brain.
- Practical benefits: BDH-GPU is GPU-friendly and matches transformer performance. It opens up a path for building models that are both interpretable and efficient without sacrificing accuracy.
In short, the Dragon Hatchling model is a step toward AI that thinks more like a brain, is easier to understand, and still competes with the best LLMs we have today.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list identifies what remains missing, uncertain, or unexplored in the paper, phrased concretely to guide future research:
- Formalization of “equations of reasoning”: The paper promises closed-form local graph dynamics aligning attention mechanisms with neuron/synapse updates but does not provide full derivations, formal proofs, or conditions of validity for these equations; supply a rigorous mathematical development, including stability and convergence properties.
- Equivalence of BDH and BDH-GPU: Claims of formal equivalence “up to placement of LayerNorms” and mean-field (radio) vs. graph (wire) communication lack precise theorems, assumptions, and counterexamples; prove exact equivalence classes, identify failure modes, and quantify the approximation error introduced by mean-field reductions.
- Thermodynamic limit and PAC-like bounds: The envisioned limit object P_A and “thermodynamic limit” behavior are not defined or proved; specify the measure space, uniformity conditions, mixing/ergodicity assumptions, and derive actual PAC-style generalization bounds over time.
- Long-context generalization: Despite motivating long reasoning chains, no experiments credibly test BDH-GPU beyond training lengths (e.g., 4×–10× longer contexts, multi-step CoT tasks with control of spurious shortcuts); create controlled benchmarks to measure length-generalization, the retention curve, and failure modes.
- Experimental comparability to Transformers: Scaling-law parity claims lack details on datasets, token counts, context lengths, optimizer, learning-rate schedules, regularization, compute budgets, and fairness controls; publish standardized training recipes and ablation-matched comparisons.
- Breadth of evaluation: Tasks focus on language and translation reminiscent of early Transformer benchmarks; test modern suites (e.g., WMT’20+, GLUE/SuperGLUE, BIG-bench, MATH/GSM8K, code-generation, retrieval-heavy QA, multilingual and domain-shift) to assess generality.
- Inference and training efficiency: No benchmark of throughput/latency, memory footprint, wall-clock training time, energy usage, and hardware utilization versus optimized Transformers or SSMs; measure end-to-end efficiency and scalability at 1B–10B+ parameters.
- Limits of linear attention and low-rank ReLU FFN: The architecture’s expressiveness relative to multi-head softmax attention and deep nonlinearity stacks is not characterized; prove expressivity bounds and empirically test tasks known to need richer attention (e.g., nested dependencies, algorithmic reasoning, combinatorial tasks).
- Positive-only sparse activations: The design enforces non-negative activations via ReLU; quantify representational trade-offs (e.g., handling negation, signed features, interference) and test whether inhibitory circuits sufficiently compensate in practice.
- Biological plausibility validation: The BDH brain mapping (excitatory/inhibitory circuits, integrate-and-fire, Hebbian plasticity) is conceptual; perform neuroscientific validation (e.g., spike-train analogs, oscillations, STDP timescales) and compare to recorded cortical dynamics.
- Stability of fast-weight Hebbian updates: No analysis of stability, interference, catastrophic forgetting, or accumulation of spurious associations during long inference; characterize stability regions, design decay/regulation mechanisms, and quantify error propagation over time.
- Memory capacity and retention: Claims of “hundreds of tokens” working memory are not measured; derive capacity scaling laws with n and d, empirically measure retention curves, interference with overlapping concepts, and the effect of noise/adversarial prompts.
- Synaptic-state interpretability: “Monosynapse” claims show localized state on specific edges but lack a general methodology, metrics, or robustness analysis; develop standardized probes, statistical significance tests, and cross-prompt/state mapping procedures.
- Emergent network modularity: The emergence of high Newman modularity is asserted, but methods for extraction, statistical validation, seed-to-seed stability, and task correlates are missing; provide replication studies and link clusters to semantic/functional units.
- Safety and foreseeability claims: The proposal to reduce “paperclip factory” risks via limit behavior is not substantiated by formal guarantees or empirical stress tests; design adversarial autonomy scenarios, measure failure rates, and implement guardrails informed by the limit theory.
- Data transparency and reproducibility: Training corpora, preprocessing, tokenization, data filters, and contamination controls are unspecified; provide detailed data pipelines, licenses, random-seed management, and reproducible training scripts.
- Parameter-to-state ratio rationale: The 1–1 ratio between trainable parameters and state size is posited as important but not justified with theory or ablations; test alternative ratios, measure effects on generalization, memory, and interpretability.
- BDH (wire) scalability: The explicit graph with heavy-tailed degree implies O(m) memory and potential communication bottlenecks; quantify scaling limits for n≈109 neurons, sparse m, and practical update scheduling on heterogeneous hardware.
- Mean-field vs. local interaction trade-offs: The radio broadcast abstraction may erase locality-dependent phenomena (e.g., recurrence, path-dependent reasoning); test tasks requiring spatial locality and compare BDH-GPU vs. BDH wire-mode.
- Negative edge weights and inhibition: The distributed interpretation relies on positive-weight edges; articulate how inhibitory effects are implemented without negative weights and the consequences for modeling antagonistic relationships.
- Attention-as-edge-state mapping: The asserted convergence of attention to synaptic edge updates (“equations of reasoning”) needs precise derivations connecting token-level attention to edge-level Hebbian adjustments; present a step-by-step mapping and validate with controlled synthetic tasks.
- Integration with slow learning/consolidation: The path from fast synaptic updates (minutes/tokens) to long-term memory (103–104 tokens and beyond) is deferred; design consolidation mechanisms, meta-learning or feedback pathways, and evaluate retention under realistic timescales.
- Robustness under distribution shift: No tests for domain shift, noise, multilingual variance, or adversarial prompts; conduct robustness suites and characterize how synaptic fast-weights respond to unexpected inputs.
- Ablations to isolate component contributions: The architecture combines linear attention, low-rank FFN, positive activations, and Hebbian-like state; perform ablations to quantify the necessity and sufficiency of each component for scaling-law parity and interpretability.
- Code–theory alignment: The code listing is referenced but the exact implementation of synaptic state, update rules, and the mapping to the theoretical kernels is unclear; document the alignment, include unit tests that verify theoretical properties.
- Expressiveness relative to RASP/C-RASP: While macro-expressiveness analogies are drawn, there are no formal theorems placing BDH-GPU within or beyond these frameworks; state expressiveness results (upper/lower bounds, completeness/incompleteness) and provide constructive examples.
- Practical memory management of synaptic state: For large n, storing and updating edge-level state is expensive; propose compressed representations, sparsity-inducing schemes, eviction/decay strategies, and quantify accuracy-efficiency trade-offs.
- Security and privacy of fast weights: In-context synaptic updates may memorize sensitive data; paper retention risks, design privacy-preserving fast-weight mechanisms, and measure leakage under probing.
- Oscillatory and temporal phenomena: The paper mentions brain oscillations but does not model or test their role in BDH/BDH-GPU; incorporate oscillatory dynamics and evaluate their impact on timing, gating, and reasoning.
- Multi-modal extension: The biological speech claim is not evaluated; extend BDH/BDH-GPU to speech/audio/vision and test whether the brain-inspired mapping holds across modalities.
- Large-scale generalization: Results span 10M–1B parameters; assess whether claims hold at 7B–70B+ scales, and whether emergent properties (monosemanticity, modularity) strengthen or degrade.
- Failure mode taxonomy: Provide a catalog of typical errors (e.g., spurious associations, overconsolidation, forgetting), detectable signals in synaptic state, and practical diagnostics for end-users.
- Scheduling and synchronization: The kernel sequence (K1–K4) requires synchronous rounds; test asynchronous schedulers, clock drift, and resilience to communication delays/noise.
- Hardware–model co-design: The mean-field radio abstraction may benefit from specialized hardware; explore custom accelerators, memory hierarchies, and sparsity-aware kernels tailored to BDH-GPU.
Practical Applications
Immediate Applications
These applications can be piloted now using the BDH and BDH-GPU codebase, standard GPU training stacks, and existing evaluation workflows.
- BDH-GPU as a drop-in alternative to GPT-2-class Transformers for language modeling and translation (software/AI)
- Use case: Train BDH-GPU models (10M–1B params) for next-token prediction, document summarization, machine translation, and command-following with mid-length contexts.
- Tools/products/workflows: Use the provided code to build training pipelines; integrate linear attention and ReLU low-rank feed-forward blocks; evaluate against existing GPT-2 baselines; deploy on commodity GPUs.
- Assumptions/dependencies: Reported parity is for GPT-2-class tasks; SOTA parity on broader tasks needs validation; performance depends on high-dim activation size n and well-tuned training.
- Synapse-level interpretability dashboards for in-context state monitoring (software/AI; safety; compliance)
- Use case: Real-time introspection of “fast weights” (dynamic synaptic state) to see which neuron–neuron links strengthen as concepts appear, enabling audits of reasoning chains, detection of prompt-induced state shifts, and debugging of chain-of-thought failures.
- Tools/products/workflows: Build a UI layer that visualizes synapse activity and sparse positive activations; log synapse-level changes per token; integrate with MLOps for audit trails and safety reviews.
- Assumptions/dependencies: Mapping synapse dynamics to human-interpretable concepts requires feature discovery; audit value depends on monosemanticity stability across datasets and versions.
- Feature-level safety filters and clamps leveraging monosemanticity (software/AI; policy/compliance)
- Use case: Identify and selectively damp or block specific concept features at inference time (e.g., sensitive topics, jailbreak cues) using positive sparse activations and consistent synapse localization.
- Tools/products/workflows: Build a “feature control” API to clamp activation dimensions or synapse pathways; connect with policy rules for content moderation.
- Assumptions/dependencies: Monosemantic features must be reliably discoverable; interventions should not degrade overall model utility; requires careful evaluation to avoid unintended shifts.
- Ephemeral context memory for agent workflows (software/AI; enterprise)
- Use case: Exploit Hebbian fast weights to maintain session-specific state across hundreds of tokens (minutes-scale reasoning), improving task-following over multi-step workflows (e.g., CRM assistants, coding agents).
- Tools/products/workflows: Implement “scratchpad” memory that resets between sessions; measure benefit for multi-turn tasks; combine with standard retrieval augmentation.
- Assumptions/dependencies: Demonstrated minutes-scale potentiation generalizes across tasks; requires careful reset strategies to avoid state bleed between sessions.
- Modular model composition by concatenation (software/AI; enterprise)
- Use case: Merge BDH-GPU modules (e.g., domain-specific translation engines) by increasing n and concatenating parameter blocks to build composite models without architectural mismatch.
- Tools/products/workflows: Create a “lego-models” toolchain that merges trained submodels; benchmark on domain mixtures; manage routing and specialization via emergent modularity.
- Assumptions/dependencies: Composition benefits depend on emergent modular structure and specialization; additional fine-tuning may be necessary post-merge.
- Sparse-activation inference optimization (software/AI; energy/efficiency)
- Use case: Exploit positive sparsity (~5%) of activation vectors to implement compute skipping and memory-aware kernels for faster inference at lower cost.
- Tools/products/workflows: Build sparse-aware GPU kernels; integrate activation masking into serving pipelines; quantify energy/time savings relative to dense baselines.
- Assumptions/dependencies: Gains depend on effective sparse kernel implementations and actual sparsity levels under target workloads.
- Neuroscience-informed simulation of language circuits (academia; neuroscience)
- Use case: Use BDH’s excitatory/inhibitory circuits, spiking-like Hebbian plasticity, and local edge-reweighting to test hypotheses about working memory and speech production.
- Tools/products/workflows: Run controlled simulations (e.g., lesion studies, oscillation manipulations); compare synapse-level patterns with neuroimaging/EEG data; publish replication protocols.
- Assumptions/dependencies: Biological plausibility is suggestive, not definitive; requires careful alignment to empirical brain data and timescales.
- Transparent educational assistants showing concept graphs (education; daily life)
- Use case: Provide learners with visible reasoning steps: concept activations and synapse strengthening when solving problems or interpreting texts.
- Tools/products/workflows: Integrate interpretability flows into tutoring UIs; show per-step concept maps; allow users to inspect “why” the assistant made a choice.
- Assumptions/dependencies: Concept-feature mapping must be robust; ensure cognitive load is manageable and explanations are pedagogically sound.
- Compliance-oriented AI reporting (finance; healthcare; enterprise)
- Use case: Generate per-output trace reports showing which features/synapses influenced decisions (e.g., clinical note summaries, KYC triage), aiding audits and post-hoc reviews.
- Tools/products/workflows: Wrap BDH inference with logging and explanation generation; integrate with GRC systems; align with internal review policies.
- Assumptions/dependencies: Domain fine-tuning required; regulatory acceptance depends on validation of interpretability metrics; ensure privacy-preserving logging.
- Research benchmarking of length generalization and fast-weights dynamics (academia; ML theory)
- Use case: Empirically test length generalization, fast-weights stability, and scaling laws across tasks; compare BDH with RASP-like macro-expressiveness frameworks.
- Tools/products/workflows: Set up controlled datasets varying length and structure; measure failure modes; publish open benchmarks and leaderboards.
- Assumptions/dependencies: Requires standardized protocols; results need replication across labs and hardware stacks.
Long-Term Applications
These applications require further theory, scaling, hardware maturation, or regulatory development before broad deployment.
- Neuromorphic implementations of BDH’s edge-reweighting kernel (hardware; robotics; energy)
- Use case: Map BDH’s local synapse updates and spiking-like interactions onto neuromorphic chips for low-power, real-time reasoning (e.g., on-device assistants, autonomous robots).
- Tools/products/workflows: Develop SNN-compatible BDH variants; co-design hardware-software; create compilers from BDH graphs to spiking substrates.
- Assumptions/dependencies: Hardware availability and maturity; efficient mapping of edge-level state; verification of performance vs. GPU tensor forms.
- PAC-like bounds and “thermodynamic limit” safety guarantees (policy; ML theory; safety)
- Use case: Establish probabilistic generalization guarantees over long horizons for scale-free reasoning systems; inform standards for autonomous agent deployments.
- Tools/products/workflows: Formalize limit behavior and validation protocols; create certifiable test suites; integrate guarantees into governance frameworks.
- Assumptions/dependencies: Requires rigorous theoretical results and empirical validation; policy uptake depends on consensus and external review.
- Lifelong learning with multi-timescale memory consolidation (software/AI; neuroscience)
- Use case: Transfer ephemeral fast weights (minutes scale) into long-term memory (103–104 tokens and beyond) with feedback signals; enable continual learning without catastrophic forgetting.
- Tools/products/workflows: Design consolidation pipelines; develop safe update policies; monitor concept drift and stability.
- Assumptions/dependencies: Mechanisms are not specified in the paper; needs new training regimes, signals, and safety controls.
- Foreseeable AI for autonomous multi-agent systems (software/AI; safety; enterprise)
- Use case: Build agent systems from scale-free BDH modules with predictable limit behavior; validate small-scale tasks to extrapolate to long time scales.
- Tools/products/workflows: Agent orchestration frameworks with length-generalization tests; runtime monitors for state drift; formal incident response procedures.
- Assumptions/dependencies: Requires validated limit theory; robust compositionality under interaction; organizational readiness for governance.
- Brain–computer interfaces inspired by BDH’s speech mechanism (healthcare; neurotechnology)
- Use case: Inform BCI designs for speech decoding/production using excitatory/inhibitory circuit models and synaptic plasticity principles.
- Tools/products/workflows: Translate BDH insights into signal processing pipelines; collaborate with clinical trials; iteratively refine with neural data.
- Assumptions/dependencies: Strong clinical validation needed; ethical and regulatory approvals; alignment with patient safety requirements.
- Regulatory frameworks for interpretable micro-foundational AI (policy; compliance)
- Use case: Define standards that recognize synapse-level interpretability, feature clamps, and state audits as compliance artifacts for high-stakes AI.
- Tools/products/workflows: Draft guidance with industry and academia; pilot regulatory sandboxes; build certification programs.
- Assumptions/dependencies: Depends on evidence that micro-foundational interpretability improves safety and accountability; requires cross-sector consensus.
- Domain-specialized “Lego LLMs” with emergent modularity (enterprise; software/AI)
- Use case: Assemble large composite models from specialized BDH modules (legal, medical, coding), leveraging high Newman modularity for targeted specialization and routing.
- Tools/products/workflows: Build module registries; automatic routing based on activation patterns; fine-tune post-assembly for harmonization.
- Assumptions/dependencies: Emergent modularity must be consistent and exploitable at scale; cross-module interference needs mitigation.
- Standardized interpretability metrics for sparse positive activations (academia; tooling; policy)
- Use case: Create benchmarks and metrics for monosemanticity, synapse localization stability, and sparsity–utility trade-offs; support reproducible interpretability science.
- Tools/products/workflows: Community datasets; metric libraries; reporting templates; integration with peer-review platforms.
- Assumptions/dependencies: Requires broad participation and robust measurement methodology; must prove utility beyond BDH.
- Real-time planning and control with local graph dynamics (robotics; industrial automation)
- Use case: Exploit BDH’s neuron–synapse local computations for predictable, low-latency decision-making in control loops (e.g., drones, manufacturing).
- Tools/products/workflows: Embedded implementations; verification tools for safety-critical loops; simulators for edge-reweighting behavior.
- Assumptions/dependencies: Strong guarantees on latency and stability needed; hardware acceleration and formal verification are preconditions.
- Finance and healthcare decision support with feature-level governance (finance; healthcare; compliance)
- Use case: Implement “feature safety switches” that enforce policy constraints (e.g., risk appetite, clinical guidelines) within the model’s reasoning state.
- Tools/products/workflows: Policy-to-feature mapping frameworks; runtime compliance monitors; human-in-the-loop override mechanisms.
- Assumptions/dependencies: Reliable mapping from policy constructs to model features; comprehensive validation to avoid bias amplification or decision errors.
Glossary
- Attention mechanism: A neural network component that lets models focus on relevant parts of input sequences by weighting interactions between tokens. "and the Attention mechanism~\cite{bahdanau2014neural,vaswani2017attention}"
- Autoregressive inference: An inference mode where a model generates or updates its state step-by-step using its own previous outputs without new external input. "During inference without external input, usually autoregressive inference, we will shorten this to ."
- BDH-GPU: A GPU-efficient specialization of the BDH architecture that reformulates local graph dynamics into tensor-friendly operations for training and inference. "we restrict it, making this restriction the core of a GPU-friendly architecture called BDH-GPU."
- Chain-of-Thought (CoT): A prompting and reasoning format where models produce intermediate steps to solve problems; used to assess and improve multi-step reasoning. "do not systematically generalize chain-of-thought (CoT) reasoning to scenarios longer than the ones seen during training"
- C-RASP: A formal framework that characterizes Transformer expressiveness via counting logic formulas over sequences. "or C-RASP~\cite{yang2024countingliketransformerscompiling,huang2025a}"
- Distributed Computing: The paper and design of algorithms and systems where computation is performed across multiple interacting nodes or agents. "computational Complexity Theory and Distributed Computing,"
- Edge-reweighting kernel: A local graph interaction rule where state variables on edges are updated using node-edge-node interactions, enabling synapse-like dynamics. "The resulting restriction will be called the edge-reweighting kernel."
- Excitatory circuit: A network of neurons whose connections increase the likelihood of downstream neurons firing. "organized as an excitatory circuit and an inhibitory circuit with integrate-and-fire thresholding of input signals at neurons."
- Fast weights: Temporally updated parameters (state) that change during inference to encode short-term memory or context. "sometimes called “fast weights” \cite{hinton1987using, schmidhuber1993reducing, ba2016using}"
- Gaussian Processes: A probabilistic model over functions used to describe limits of infinitely wide neural networks. "a link has been established between infinitely wide feedforward networks and Gaussian Processes~\cite{neal2012bayesian,lee2017deep,yang2019wide}."
- Hebbian learning: A local synaptic update rule where connections strengthen when pre- and post-synaptic neurons co-activate. "synaptic plasticity with Hebbian learning using spiking neurons"
- Inhibitory circuit: A network of neurons that decrease the likelihood of downstream neurons firing to regulate activity. "organized as an excitatory circuit and an inhibitory circuit with integrate-and-fire thresholding of input signals at neurons."
- Integrate-and-fire thresholding: A neuron model where inputs accumulate until a threshold is reached, triggering a spike. "integrate-and-fire thresholding of input signals at neurons."
- Interaction kernel: The formal set of local rules governing computation and communication between particles (neurons) in the model. "We start by presenting the more general form of this interaction kernel."
- Layer Norms: Normalization operations applied within neural network layers to stabilize training and scale activations. "with the same inference behavior and the same size of trainable parameters, with the two models being formally equivalent up to placement of Layer Norms (cf.~Claims~\ref{claim:graphs}~and~\ref{claim:att_equiv})."
- Linear attention: An attention variant with computational cost linear in sequence length, often using kernelized or factorized forms. "reliance on linear attention in high dimension"
- Lotka–Volterra dynamics: Classical equations modeling predator-prey interactions; here, a non-normalized analogue relates to replicator dynamics on graphs. "also equivalently known as a non-normalized form of the fundamental Lotka-Volterra predator-prey dynamics."
- Markov chain: A stochastic process where the next state depends only on the current state, represented here by stochastic matrix transitions. "then is a Markov chain transition, with ."
- Mean-field: An approximation where interactions are replaced by an average effect of all particles, enabling radio-like broadcast communication. "treating the communication of the particles as proceeding through a mean-field (
radio network''), rather than a graph (communication by wire''), cf.~Fig. {fig:ss}" - Monosemanticity: A property where individual features or neurons consistently represent a single concept. "We demonstrate monosemanticity in BDH on language tasks, including representation of concept abstractions, which happens even for small models, below 100M-parameter scale."
- Newman modularity: A measure of community structure in graphs indicating the strength of division into modules. "spontaneous emergence of graph structure with high Newman modularity in the neuron-neuron communication network"
- PAC-like bounds: Probably Approximately Correct-style theoretical guarantees about generalization performance. "with the ultimate goal of Probably Approximately Correct (PAC)-like bounds for generalization of reasoning over time."
- Replicator dynamics: Equations modeling frequency changes of competing types based on relative fitness; a graph-based node-reweighting process. "Equation {eq:chemistry} describes the class of evolutionary systems following the equations of replicator dynamics~\cite{HofbauerSigmund1998}"
- RASP-L: A Transformer expressiveness framework that models sequence algorithms through restricted vector operations. "RASP-L provides a very convenient heuristic for estimating Transformer expressiveness at the rather coarse level of vector operations"
- Scale-free: A network property where node degree follows a heavy-tailed distribution, lacking a characteristic scale. "Uniform, scale-free biological networks, such as the brain, have powerful properties,"
- Spiking Neural Network: A neural model where information is transmitted via discrete spikes, enabling biologically plausible timing dynamics. "a graph-based Spiking Neural Network system capable of Hebbian learning dynamics"
- State-space system: A formal model separating fixed parameters from a time-varying state updated by an architecture function. "we will use state-space notation, and consider a state-space system composed of two parts: a set of model parameters ... and a state "
- Synaptic plasticity: The capacity of synapses to strengthen or weaken over time, forming the basis of working memory and learning. "The working memory of BDH during inference entirely relies on synaptic plasticity with Hebbian learning using spiking neurons"
- Thermodynamic Limit: The behavior of models as size and time go to infinity, yielding uniform asymptotic properties. "a new theory of “Thermodynamic Limit” behavior for language and reasoning models"
- Turing-complete: Capable of performing any computation given enough time and memory; a property of model limit objects at criticality. "Most reasoning models and AI agentic systems admit limit objects (i.e., extensions to infinite time and infinite size) which are Turing-complete"
Collections
Sign up for free to add this paper to one or more collections.

