- The paper introduces a full duplex Listening-while-Speaking Language Model (LSLM) that fuses a decoder-only TTS model with a streaming SSL encoder to enable simultaneous listening and speaking.
- The Middle Fusion strategy outperforms Early and Late Fusion, achieving a 4.05% word error rate and 98% F1 score in real-time interactive settings.
- The model demonstrates robust performance in handling interruptions and adapting to new speakers, setting the groundwork for advanced real-time human-computer interaction.
LLM Can Listen While Speaking
Introduction
The paper "LLM Can Listen While Speaking" (2408.02622) introduces a novel approach to interactive speech LLMs (iSLM) by incorporating full duplex modeling (FDM), a crucial feature enabling simultaneous listening and speaking. Traditional speech LLMs are often constrained to turn-based interactions, limiting their applicability in real-time human-computer interaction (HCI) scenarios. This research addresses these limitations by proposing the Listening-while-Speaking LLM (LSLM), which integrates both a decoder-only TTS model for speech generation and a streaming SSL encoder for real-time audio processing.
Model Architecture
The proposed LSLM architecture comprises two main components: a token-based decoder-only Transformer for generating speaking tokens and a streaming SSL encoder for processing listening tokens. This configuration allows the model to engage in full duplex communication, enhancing its capability to detect and respond to turn-taking in real-time interactions.
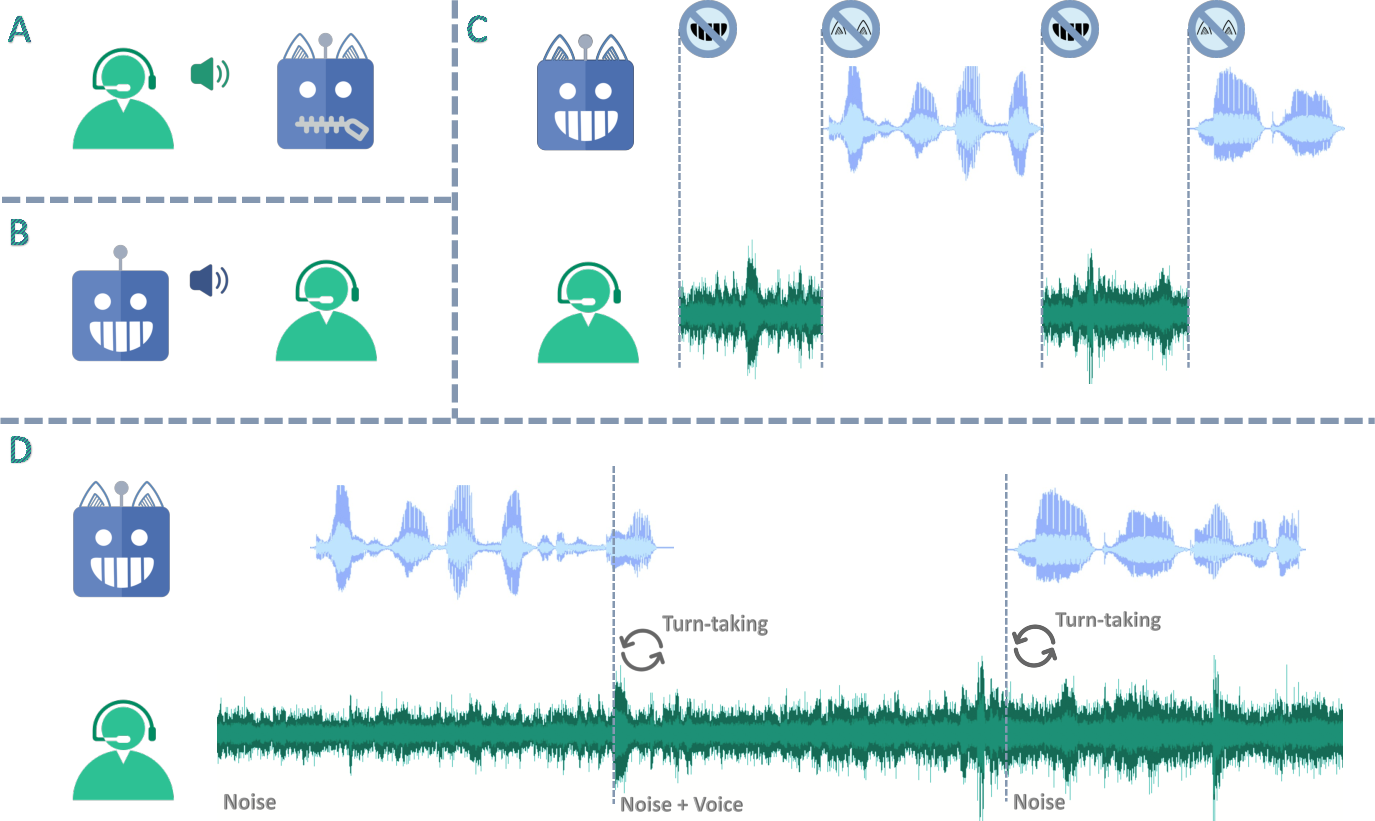
Figure 1: Illustration of simplex, half duplex, and full duplex speech LLMs. (A): Simplex speech LLM with listening ability. (B): Simplex speech LLM with speaking ability. (C): Half duplex speech LLM with both listening and speaking abilities. (D): Full duplex speech LLM can listen while speaking.
To achieve effective integration of speaking and listening channels, the authors explore three fusion strategies: Early Fusion, Middle Fusion, and Late Fusion. Among these, Middle Fusion demonstrates superior performance, striking an optimal balance between speech generation and real-time interaction capabilities.
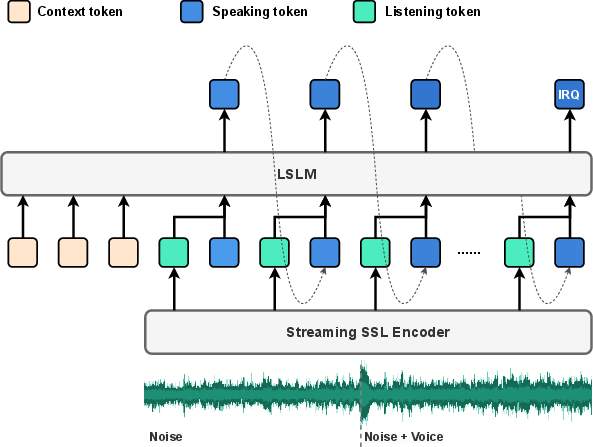
Figure 2: Proposed LSLM. The model contains a decoder-only Transformer to generate speaking tokens and a streaming SSL encoder to process listening tokens. An interruption token (IRQ) is added to allow the model to terminate early if a turn-taking occurs.
Experimental Evaluation
The study evaluates LSLM's performance in two experimental settings: command-based FDM and voice-based FDM. The results reveal that Middle Fusion outperforms other strategies in both TTS capability and interactive functionality. The model achieves a word error rate (WER) of 4.05% in clean conditions and maintains robust interaction performance with a Precision of 97.80%, Recall of 98.19%, and an F1 score of 98.00%.
Moreover, the model exhibits enhanced robustness to noise and sensitivity to previously unseen speakers, demonstrating its effectiveness in real-world scenarios. For instance, voice-based FDM tests highlight the model's ability to handle diverse interruption commands and adapt to new speakers without significant performance degradation.
Visualization and Analysis
To further understand the model's turn-taking mechanism, the researchers visualize the probability distribution of interruption tokens (IRQ) over time. This analysis reveals that IRQ probabilities increase sharply when real-time turn-taking signals are detected, allowing for effective interruption management.
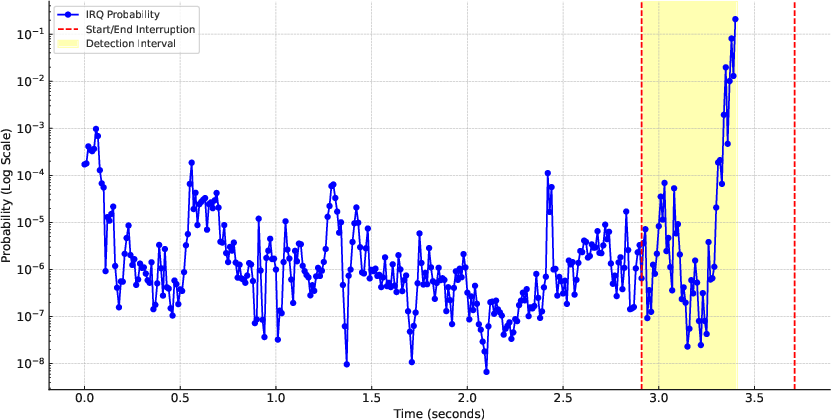
Figure 3: Illustration of the probability distribution of IRQ tokens (being interrupted) over time. The logarithmic scale probability is used for clear visualization.
Future Directions
This research paves the way for future developments in duplex communication within speech LLMs. Potential avenues for exploration include integrating audiovisual co-guidance to enhance turn-taking, developing fully duplex speech-in speech-out dialogue systems, and refining models to accommodate a wider array of environmental conditions and speaker variations.
Conclusion
The introduction of the LSLM marks a significant advancement in interactive speech LLMs by enabling full duplex communication. This capability facilitates more natural and flexible HCI, with implications for a wide range of applications, from virtual assistants to more sophisticated conversational agents. The research highlights that integrating middle fusion strategies significantly enhances both speech generation and interactive capabilities, setting a foundation for future innovations in interactive AI systems.

