- The paper presents a novel DiT framework integrating trajectory extraction and adaptive fusion, achieving 3–5x improvement in trajectory adherence over U-Net models.
- It leverages a 3D VAE for encoding motion patches and uses adaptive normalization to enhance motion consistency in long, high-resolution videos.
- The two-stage training strategy with dense-to-sparse flow and rigorous evaluation across FVD, CLIPSIM, and TrajError benchmarks demonstrates robust scalability and fidelity.
Introduction and Motivation
The paper introduces Tora, a trajectory-oriented Diffusion Transformer (DiT) framework for video generation, designed to address the limitations of prior video diffusion models in motion controllability, scalability, and fidelity. While previous approaches—primarily based on U-Net architectures—have demonstrated competence in short, low-resolution video synthesis, they exhibit significant degradation in motion consistency and visual quality as video length and resolution increase. Tora leverages the scalability of DiT architectures and introduces explicit trajectory conditioning, enabling precise, long-range, and physically plausible motion control in generated videos.
Architectural Innovations
Tora is built upon the OpenSora DiT backbone and introduces two key modules: the Trajectory Extractor (TE) and the Motion-guidance Fuser (MGF). The TE encodes user-specified trajectories into hierarchical spacetime motion patches using a 3D VAE, ensuring that motion information is embedded in the same latent space as video patches. The MGF injects these motion conditions into the DiT blocks via adaptive normalization, facilitating seamless integration of trajectory guidance at multiple abstraction levels.
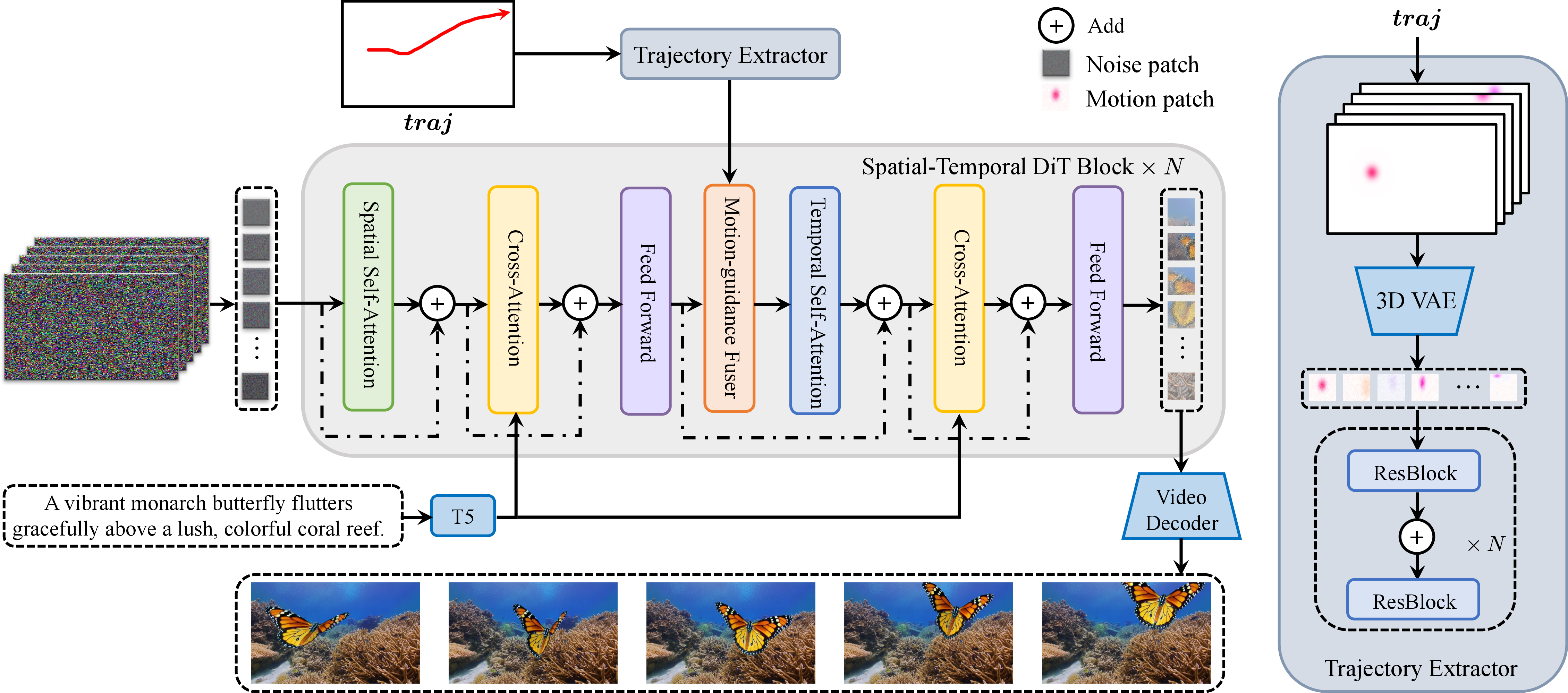
Figure 1: Overview of the Tora architecture, highlighting the Trajectory Extractor and Motion-guidance Fuser for trajectory-controlled video generation.
The TE first transforms trajectory vectors into dense trajectory maps, applies Gaussian filtering, and visualizes them in the RGB domain. These are then compressed by a 3D VAE—initialized with SDXL weights for spatial compression—yielding motion latents that are patchified and processed through stacked convolutional layers with skip connections to extract multi-level motion features. The MGF explores several fusion strategies (extra channel, cross-attention, adaptive norm), with adaptive normalization empirically demonstrating the best trade-off between performance and computational efficiency.
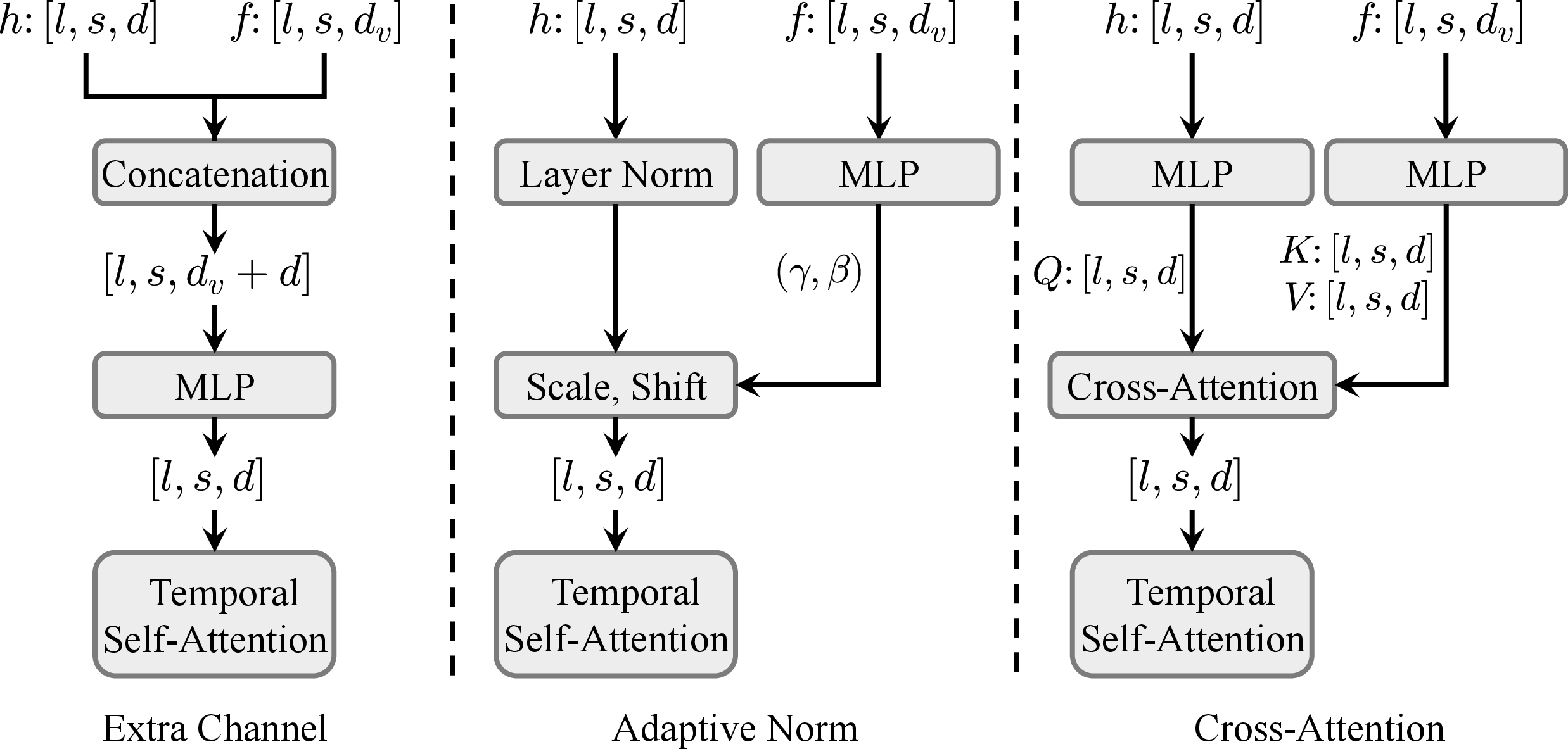
Figure 2: Comparison of different MGF designs; adaptive normalization yields the best performance for trajectory conditioning.
Training Pipeline and Data Processing
Tora's training pipeline is designed for robust motion controllability across diverse conditions. The model is trained on a curated dataset of 630k video clips, each annotated with captions and dense/sparse motion trajectories. The training employs a two-stage strategy: initial training with dense optical flow to accelerate motion learning, followed by fine-tuning with sparse, user-friendly trajectories. This hybrid approach improves adaptability to various motion patterns and enhances the model's ability to generalize to arbitrary trajectory inputs.
The data processing pipeline includes scene segmentation, aesthetic scoring, optical flow-based filtering, and motion segmentation to ensure high-quality, object-centric motion annotations. Captioning is performed using PLLaVA-13B, and static or camera-motion-dominated clips are filtered out to focus on object motion.
Quantitative and Qualitative Evaluation
Tora is evaluated against state-of-the-art motion-controllable video generation models (e.g., VideoComposer, DragNUWA, AnimateAnything, TrailBlazer, MotionCtrl) on standard metrics: Fréchet Video Distance (FVD), CLIP Similarity (CLIPSIM), and Trajectory Error (TrajError). Tora consistently outperforms baselines, especially as video length increases. For 128-frame sequences, Tora achieves a TrajError of 11.72, compared to 38.39–58.76 for U-Net-based methods, representing a 3–5x improvement in trajectory adherence. FVD and CLIPSIM metrics also indicate superior visual quality and semantic alignment.
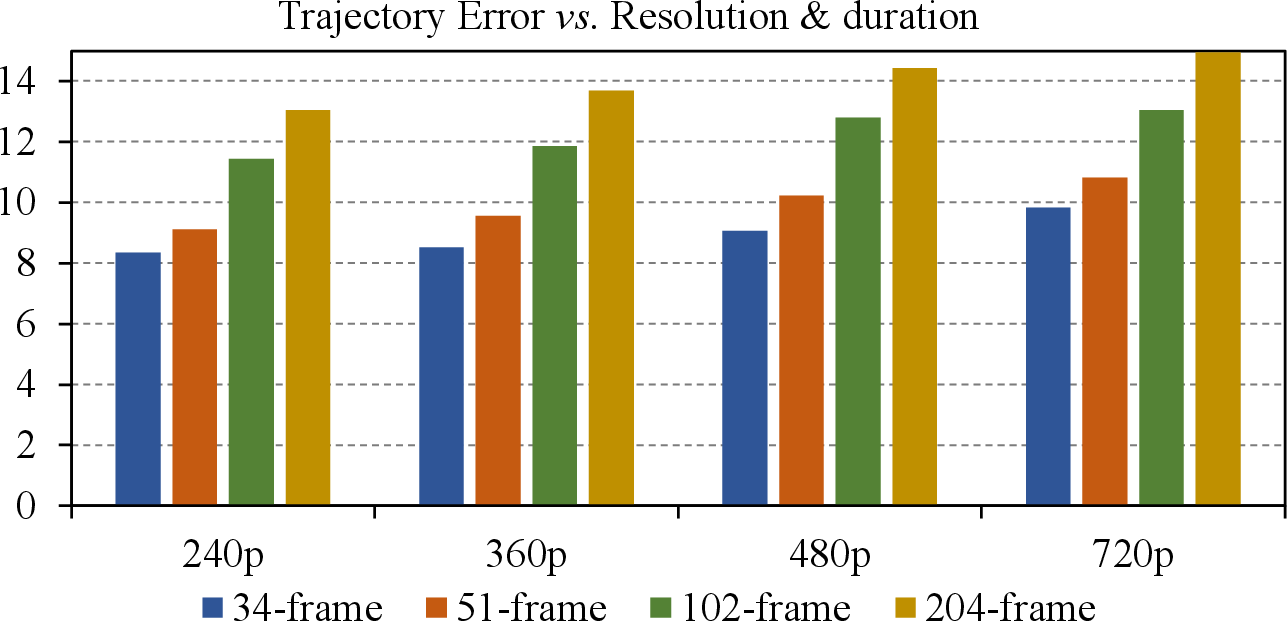
Figure 3: Trajectory Error across resolutions and durations; Tora maintains gradual error increase, unlike U-Net models which degrade rapidly.
Qualitative results further demonstrate that Tora generates smoother, more physically plausible motion, with reduced artifacts such as motion blur, object deformation, and unintended camera movement. The model is capable of handling multiple objects, diverse aspect ratios, and long durations (up to 204 frames at 720p), with robust trajectory following.

Figure 4: Tora-generated samples under various visual and trajectory conditions, including multi-object and multi-condition scenarios.

Figure 5: Qualitative comparison of trajectory control; Tora produces smoother, more realistic motion than competing methods.
Ablation Studies
Ablation experiments validate the design choices in trajectory compression and motion fusion. The 3D VAE-based trajectory encoding outperforms frame sampling and average pooling, preserving global motion context and yielding lower FVD and TrajError. Among fusion strategies, adaptive normalization in the MGF module achieves the best results, attributed to its dynamic feature adaptation and temporal consistency. Integrating MGF within the Temporal DiT block further enhances motion fidelity. The two-stage training strategy (dense-to-sparse flow) is shown to be critical for effective learning of both detailed and user-friendly trajectory conditions.
Implications and Future Directions
Tora establishes a new baseline for trajectory-conditioned video generation, demonstrating that transformer-based diffusion models, when equipped with explicit motion conditioning and scalable architectures, can achieve high-fidelity, long-duration, and physically consistent video synthesis. The explicit separation of motion encoding and fusion enables flexible integration of diverse control signals (text, image, trajectory), paving the way for more interactive and user-driven video generation systems.
Practically, Tora's approach is well-suited for applications in animation, simulation, robotics, and content creation, where precise motion control and high visual fidelity are required. Theoretically, the work highlights the importance of hierarchical motion representation and adaptive conditioning in generative video models. Future research may explore more efficient trajectory encoding schemes, improved temporal consistency mechanisms, and integration with reinforcement learning or physics-based priors for even more realistic world modeling.
Conclusion
Tora advances the state of motion-controllable video generation by introducing a trajectory-oriented DiT framework with hierarchical motion encoding and adaptive fusion. The model achieves strong numerical results in both trajectory adherence and visual quality, particularly for long, high-resolution videos. The architectural and training innovations presented in Tora provide a robust foundation for future research in controllable, scalable, and physically grounded video generation.

