- The paper introduces GenRec, a generative sequential recommendation method that reframes prediction as a sequence-to-sequence task using LLMs and Transformers.
- It employs an encoder-decoder architecture with token, positional, and ID embeddings alongside a masking mechanism to capture user-item interaction patterns.
- The model outperforms baselines on datasets like Amazon and Yelp, achieving superior Hit Ratios and NDCG scores even under low-resource conditions.
Generative Sequential Recommendation Using GenRec
The paper "GenRec: Generative Sequential Recommendation with LLMs" proposes a model, GenRec, which frames sequential recommendation as a sequence-to-sequence generation task using LLMs. This approach is designed to capture user preferences by modeling interactions with Transformer-based architectures, thus enhancing sequential recommendation systems.
Model Architecture
GenRec is built on an encoder-decoder framework utilizing the power of Transformers. The architecture consists of an encoder that processes input sequences containing user-item interactions and a decoder that predicts subsequent items in the sequence. The model employs various embeddings, including token embeddings, positional embeddings, and user/item identifier embeddings, to capture cross-modal features and sequence information.
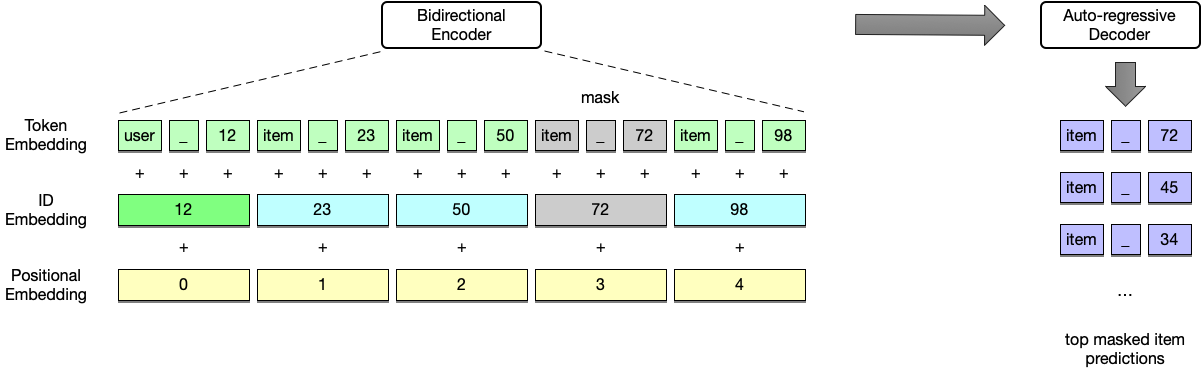
Figure 1: An illustration of the architecture of GenRec. The input textual user item interaction sequence is first tokenized into a sequence of tokens. Token embedding, ID embedding and positional embedding are summed up to produce the bidirectional encoder input. In pretraining and finetuning, a random item is masked and the auto-regressive decoder generates the masked item. In inference, the decoder generates top 20 masked item predictions to calculate the evaluation metrics.
Masking Mechanism and Task Objectives
GenRec’s training paradigm incorporates a masked item prediction objective, aligning the pretraining and fine-tuning phases to maximize sequential context learning. During pretraining, a random item from the user sequence is masked, and GenRec predicts this masked item, using cross-entropy as the optimization criterion.
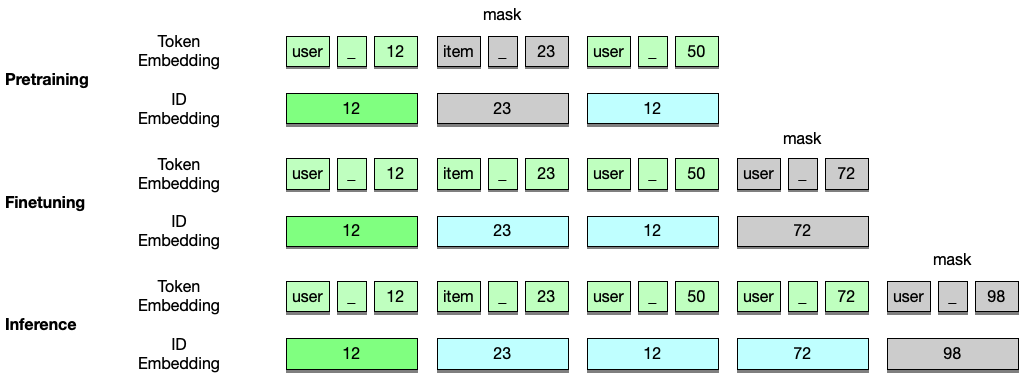
Figure 2: An illustration of different masking mechanisms in pretraining, finetuning and inference. In pretraining, a random item in the sequence is masked while in finetuning and inference, masked items are appended to the end of the sequence. Note, the last two items in the user item interaction sequence are excluded in pretraining to avoid data leakage. Similarly, the last one item in the sequence is excluded in finetuning.
The model ensures that the context learned during pretraining on masked sequences translates effectively to the fine-tuning stage, where the task is to predict the next item in the user interaction sequence by appending a [MASK] token at the end.
Experimental Evaluation
GenRec was evaluated on multiple real-world datasets including Amazon Sports, Amazon Beauty, and Yelp datasets. The model achieved state-of-the-art results on several metrics, such as top-5 and top-10 Hit Ratios (HR) and NDCGs, indicating its effective modeling of sequential patterns within user-item interaction data.
The paper emphasizes that even under low-resource settings, GenRec maintains competitive performance compared to classification-based methods and complex generative ones, highlighting its efficiency and broad applicability.
In comparing GenRec with baselines such as Caser, HGN, and P5, GenRec demonstrated superior performance, particularly on datasets with extensive user-item interaction histories. The flexibility in modality-specific embedding and the use of the cloze style objectives bolstered this performance by incorporating both personalization and efficacy.
Conclusion
GenRec advances the application of LLMs in sequential recommendation by leveraging a generative framework that fuses model simplicity with robust performance. The direct application of Transformer-based models caters to personalized and efficient recommendation generation without relying on complex prompt engineering. Ongoing research can explore adaptations of this framework in other recommendation domains, driven by the same generative architecture principles.
This paper presents a promising adaptation of LLMs, indicating the heightened capability of sequence models to inform personalization through generative methods aligned with pretraining and fine-tuning consistency. These considerations highlight a trajectory toward more adaptable and efficient recommendation systems built on foundational natural LLMs.