- The paper introduces OfficeBench to standardize multi-application evaluation of LLM agents in realistic office workflows.
- It deploys a Docker environment simulating applications like Word, Excel, and email to assess performance on 300 varied tasks.
- Experimental results reveal GPT-4 Omni’s 47% success rate versus 93.33% human performance, highlighting key areas for improvement.
OfficeBench: Evaluating Language Agents for Office Automation
The paper "OfficeBench: Benchmarking Language Agents across Multiple Applications for Office Automation" (2407.19056) introduces OfficeBench, a benchmark designed to evaluate the capability of LLMs in performing office automation tasks. This benchmark addresses the need for automation systems that integrate multiple applications to execute complex office workflows, setting a challenge for existing LLM agents.
Introduction to OfficeBench
OfficeBench represents one of the first attempts to standardize the evaluation of LLM agents within realistic office environments. Previous benchmarks have typically focused on individual tasks or applications, while OfficeBench requires the simultaneous integration of information from multiple sources. This necessitates proficient long-horizon planning and timely application-switching by agents.
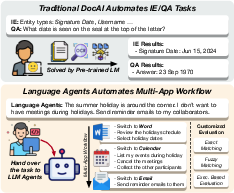
Figure 1: OfficeBench assesses the ability of language agents to perform complex office workflows across multiple applications using customized evaluation methods.
The benchmark uses a Docker environment pre-loaded with various office applications like Word, Excel, PDFs, and email systems. This setup simulates real-world office tasks such as email communication and document editing, providing a challenging context for testing LLM capabilities.
Workflow and Operations in OfficeBench
OfficeBench models office tasks using a transition system where applications represent states and operations signify transitions. This formulation allows agents to construct operation chains efficiently, facilitating complex task resolution.
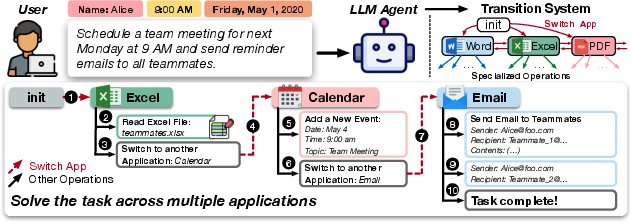
Figure 2: Workflow in OfficeBench where the LLM agent constructs an operation chain across multiple applications effectively.
Applications have specific operations, for instance, Excel supports reading and writing cell data, while the email client facilitates sending and retrieving messages. The ability to switch between these applications via operations like switch_app is crucial for handling comprehensive workflows. The benchmark evaluates LLMs on their proficiency in utilizing operations relevant to each application context.
Evaluation Framework
OfficeBench encompasses a suite of 300 tasks categorized into Single-App, Two-App, and Three-App scenarios, reflecting varying complexities. Customized evaluation methods, including exact and fuzzy matching as well as execution-based assessments, ensure rigorous analysis of agent performance.
Tasks demand agents to switch applications seamlessly, process data accurately and ultimately culminate with intended outcomes. This multifaceted evaluation framework is pivotal for identifying the strengths and shortcomings of current LLM agents in complex work settings.
Experimental Findings
Experiments reveal that GPT-4 Omni outperforms other models, achieving a 47% pass rate overall, but it still falls short of human-level performance, which registers at 93.33%. This discrepancy highlights the existing limitations of LLM agents in accurately simulating human workflows within office environments.

Figure 3: Failure cases include redundant operations, hallucinated actions, and planning failures in LLM agents.
Implications and Future Directions
OfficeBench presents significant implications for the future development of LLM agents in office automation. The benchmark underscores the necessity for enhanced cross-application reasoning and improved action space management. The analyses of failure cases, such as operational redundancies and hallucinations, offer insights into areas requiring innovation.
The authors anticipate that continued development in instruction tuning and expansion of supported applications will push LLM capabilities closer to human task execution efficiency. OfficeBench sets a foundation for future benchmarks aimed at even more complex multi-application task integration.
Conclusion
OfficeBench serves as a pivotal benchmark for assessing the real-world applicability of LLM agents in office automation. By simulating realistic workflows, it provides a comprehensive evaluation framework that identifies current limitations and paves the way for future advancements in intelligent agent design. This benchmark is integral to advancing the robustness and effectiveness of LLMs in handling intricate, multi-application office tasks.