- The paper introduces the VSSD model, which uses Non-Causal State Space Duality to address computational challenges in vision transformers.
- It integrates overlapping convolutions, NC-SSD blocks, and hybrid attention to achieve linear complexity and enhanced global context extraction.
- Experimental results on ImageNet-1K, MS COCO, and ADE20K confirm VSSD's superior efficiency and competitive accuracy compared to traditional models.
VSSD: Vision Mamba with Non-Causal State Space Duality
Introduction
The "VSSD: Vision Mamba with Non-Causal State Space Duality" paper presents an innovative approach to overcoming the computational challenges associated with vision transformers (ViTs) by introducing a novel Visual State Space Duality (VSSD) model. By leveraging linear computational complexity features of state space models (SSMs) and transforming them into a non-causal state through the proposed NC-SSD, the paper aims to enhance efficiency and performance in processing image data, compared to traditional ViT and CNN models. This work is positioned within the context of reducing the computational overhead seen in traditional transformers, particularly when handling non-causal vision tasks.
Vision State Space Duality Model
The core contribution of the paper is the introduction of a new model architecture: VSSD. The proposed model starts with a series of overlapping convolutions leading into four progressive stages of processing, prominently featuring the Non-Causal State Space Duality (NC-SSD) and hybrid attention mechanisms.
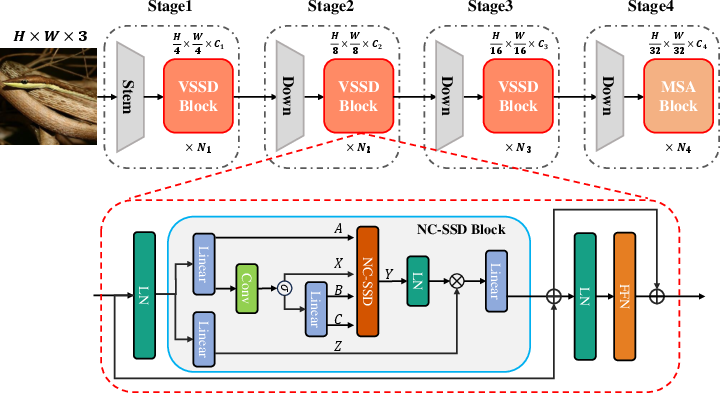
Figure 1: Overall Architecture of the Proposed VSSD Model.
The NC-SSD framework variably allows for non-causal treatment of image sequences by modifying the role of the state space matrix A from a scalar determining hidden state retention to a determinant for the contribution of current tokens. This transformation enables comprehensive global information acquisition crucial in vision tasks while maintaining the efficiency associated with linear computational complexity. By discarding the causal mask and adopting a scalar-based approach, VSSD enhances the efficiency of both training and inference.
Methods and Technologies
Non-Causal State Space Duality
Central to the VSSD model is its NC-SSD block. This technology departs from traditional SSMs by adjusting how tokens influence state contributions, enabling a seamless transition from causal to non-causal processing. The NC-SSD dismisses previous dependency limitations, promoting a global context formation through inherent non-causality.
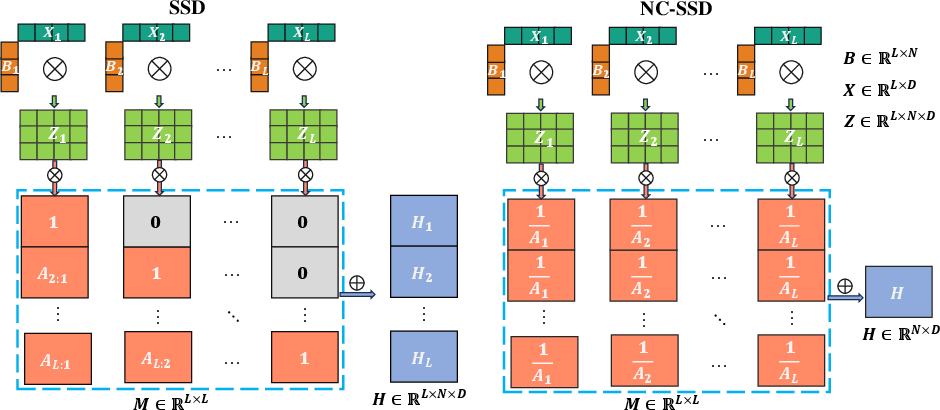
Figure 2: Illustration of the Hidden State Generation Process for SSD and NC-SSD.
This block contrasts sharply with existing SSM techniques, which often rely on multi-scan strategies for 1D token sequences. Rather, the NC-SSD allows tokens to share a singular hidden state, simplifying processing and expanding applicability to complex, non-causal datasets such as images.
Hybrid and Overlapped Architectures
Integration of select ViT components with the NC-SSD results in the hybrid architecture found in VSSD. During the final stage, self-attention layers replace NC-SSD, capitalizing on deep features' processing capabilities. Furthermore, using overlapped downsampling layers aligns with best practices in ViT design, retaining vital data during resolution reductions.
Experimental Results
VSSD displayed robust performance against both benchmark models on the ImageNet-1K dataset and in downstream tasks such as object detection on MS COCO and segmentation on ADE20K. The VSSD-Micro model outperformed traditional CNNs and ViTs on image classification tasks while maintaining comparable computation costs.
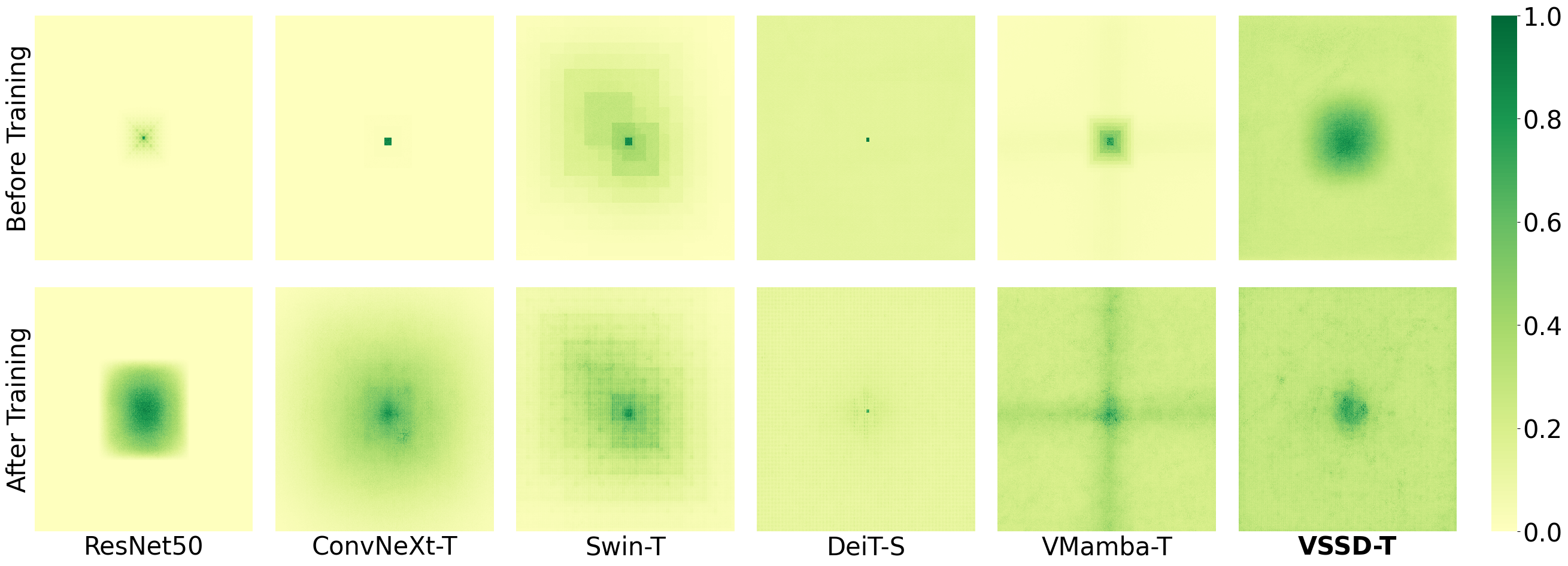
Figure 3: Comparison of the Effective Receptive Field (ERF) among our VSSD, CNN-based models (ResNet and ConvNeXt), and others.
In detailed ablation studies, NC-SSD demonstrated clear advantages over its SSD predecessor in training throughput and computational efficiency. This further validates the non-causal approach in terms of both performance gains and practical computation efficiency.
Conclusion
The VSSD model makes substantial improvements in transforming vision models by leveraging non-causal state space representations, marking a significant advancement in computational efficiency and model accuracy. While practical implementation of NC-SSD shows promise across several tasks, ongoing work could explore its application in large-scale deployments and complex, high-resolution datasets. Consequently, the scalability and nuances of broader integration warrant further investigation.

