- The paper's main contribution is formulating a principal-agent MDP framework where contracts guide AI agents to align with the principal's goals.
- It introduces a meta-algorithm leveraging Subgame Perfect Equilibrium and contraction mapping, ensuring policy convergence in a finite number of iterations.
- The deep RL implementation, validated in multi-agent sequential social dilemmas, shows effective AI coordination with minimal intervention and improved social welfare.
Contracting AI Agents Through Principal-Agent Reinforcement Learning
The paper "Principal-Agent Reinforcement Learning: Orchestrating AI Agents with Contracts" (2407.18074) introduces a framework for aligning the incentives of a principal and an agent in a reinforcement learning setting, using contracts to guide the agent's behavior towards the principal's goals. The approach formulates a principal-agent game within an MDP, where the principal designs contracts and the agent learns a policy in response.
Principal-Agent MDP Framework
The paper extends the classical contract theory to MDPs, defining a principal-agent MDP as a tuple M=(S,s0,A,B,O,O,R,Rp,T,γ). This framework includes states (S), actions (A), outcomes (O), contracts (B), outcome function (O), reward functions for the agent (R) and the principal (Rp), a transition function (T), and a discount factor (γ). The principal offers contracts to incentivize the agent, who then acts based on these incentives. The model distinguishes between observed-action and hidden-action scenarios, where the principal may or may not directly observe the agent's actions.
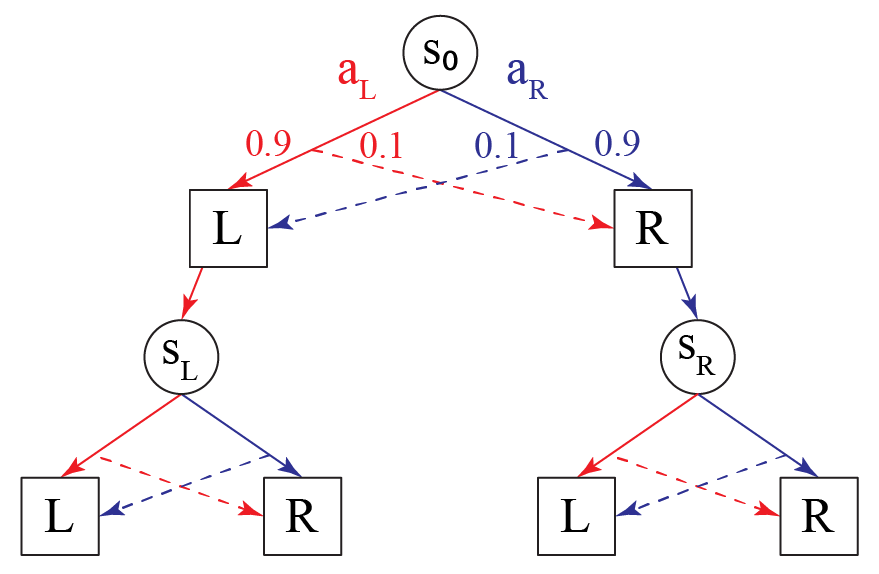
Figure 1: Example of a principal-agent MDP with three states S={s0,sL,sR}, illustrating the agent's actions and the principal's rewards.
Subgame Perfect Equilibrium
The paper adopts the solution concept of Subgame Perfect Equilibrium (SPE), which is computed using a meta-algorithm. SPE requires that the strategies of both principal and agent form a Nash equilibrium in every subgame of the overall game. The meta-algorithm iteratively optimizes the principal's and agent's policies in their respective MDPs, converging to SPE in a finite number of iterations for finite-horizon games. This is summarized by:
Theorem 1: Given a principal-agent stochastic game G with a finite horizon T, the meta-algorithm finds SPE in at most T+1 iterations.
The paper also provides a contraction mapping theorem that helps explain why each iteration of the meta-algorithm monotonically improves the principal's policy, which is described as:
Theorem 2: Given a principal-agent finite-horizon stochastic game G, each iteration of the meta-algorithm applies to the principal's Q-function an operator that is a contraction in the sup-norm.
Learning-Based Implementation
To handle large MDPs with unknown transition dynamics, the paper presents a deep RL implementation of the meta-algorithm. This implementation involves training the principal's and agent's policies using Q-learning. The approach includes a two-phase setup:
- The principal's policy is trained with access to the agent's optimization problem.
- The learned principal's policy is validated against black-box agents trained from scratch.
The principal's learning problem is divided into learning the agent's policy that the principal wants to implement and computing the optimal contracts that implement it using Linear Programming (LP). The contractual Q-function q∗(s,ap∣π∗(ρ)) is defined as the maximal principal's Q-value that can be achieved by implementing ap∈A. The paper formulates an LP to solve for the optimal contracts. The LP is:
b∈BmaxEo∼O(s,ap)[−b(o)] s.t.∀a∈A:Eo∼O(s,ap)[b(o)]+Q∗(s,ap∣ρ)≥Eo∼O(s,a)[b(o)]+Q∗(s,a∣ρ).
Extension to Multi-Agent RL and SSDs
The paper extends the principal-agent framework to multi-agent RL, addressing sequential social dilemmas (SSDs). The principal aims to maximize agents' social welfare through minimal payments. The Coin Game is used as a benchmark SSD environment to empirically validate the approach.
(Figure 2)
Figure 2: Learning curves in the Coin Game showing social welfare, the proportion of social welfare paid, and accuracy of the principal's recommendations.
Experimental results show that the algorithm can find a joint policy that matches optimal performance with minimal intervention, suggesting an approximate convergence to SPE. The results also demonstrate that the constant proportion baseline is much less effective than the algorithm when given the same amount of budget.
Conclusions
The paper provides a solid contribution to contract design and multi-agent RL, demonstrating a practical approach to orchestrating AI agents with contracts. The application to SSDs highlights the potential for maximizing social welfare with minimal intervention, addressing a gap in the existing literature. This work has the potential to influence future developments in areas such as mechanism design, MARL, and governance of AI systems. Future research directions include scaling the algorithms to more complex environments, considering partially observable settings, and allowing the principal to randomize contracts.

