- The paper introduces Latent MIM, a novel self-supervised method that models latent representations instead of raw pixels to capture high-level semantics.
- It employs an online-target encoder architecture with a cross-attention decoder to mitigate representation collapse and enhance semantic feature learning.
- Experimental results demonstrate significant improvements, notably 50.1% nearest neighbor classification accuracy, and effective performance in segmentation and few-shot learning tasks.
Towards Latent Masked Image Modeling for Self-Supervised Visual Representation Learning
Self-supervised learning has emerged as a powerful paradigm for visual representation learning, particularly due to its ability to leverage vast quantities of unlabeled data. Masked Image Modeling (MIM) is one such approach that reconstructs pixels of masked image regions, capturing local representations and spatial structures. However, MIM has limitations in capturing high-level semantics as it predominantly focuses on low-level features. The paper proposes Latent MIM, a variant that models latent representations instead of raw pixels, thereby potentially enhancing the semantic richness of learned representations.
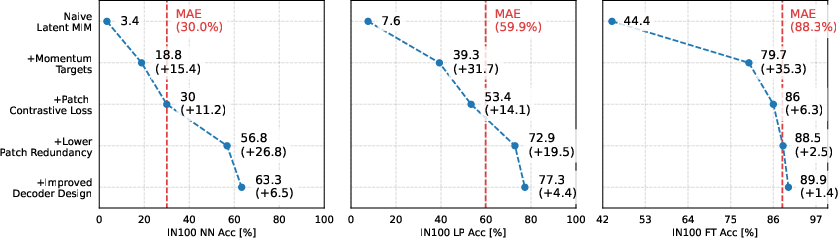
Figure 1: Challenges of Latent MIM. The representations learned by MIM approaches fail to capture high-level semantics, as shown by the poor performance in nearest neighbor and linear probe evaluation.
Implementation Approach
Latent MIM aims to overcome the limitations of pixel-level reconstruction by focusing on latent space modeling. The architecture comprises an online encoder (f(⋅)), a target encoder (fT(⋅)), and a decoder (g(⋅)). The online encoder processes visible patches to generate latent embeddings, whereas the decoder reconstructs masked regions' representations conditioned on visible contexts. The target encoder generates reconstruction targets. These targets are learned jointly with the model, which poses significant training challenges due to possible trivial solutions and high semantic correlations between adjacent patches.
Key Challenges and Strategies
- Representation Collapse: Similar to BYOL, joint optimization of visible and masked region representations can lead to degenerate solutions where representations collapse to identical outputs. Asymmetrical architecture or momentum-based weight averaging (e.g., EMA) for the target encoder can mitigate this.
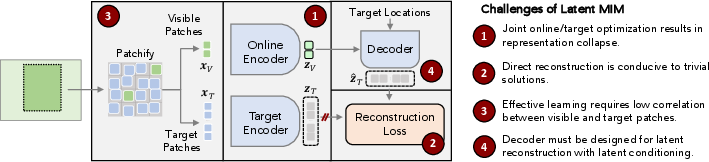
Figure 2: Overview of Latent MIM method displaying model components and patch generation strategies, including key challenges related to joint optimization and decoder design.
- Reconstruction Objectives: Direct losses like MSE may not incentivize rich feature learning due to lack of contrastive cues. Alternative objectives like patch discrimination using InfoNCE loss encourage diversity and richer representation across patches.
- Semantic Correlations: Nearest patches exhibit high correlation in latent space. Employing higher mask ratios and non-contiguous grid patching reduces spatial redundancy and helps mitigating trivial predictions based on spatial proximity.
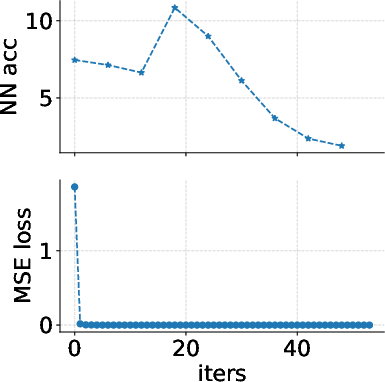
Figure 3: Training Collapse of the Naive Latent MIM; zero reconstruction loss achieved but lacking meaningful representation indicating random structure.
- Decoder Design: Traditional pixel-based MIM uses self-attention decoders; however, for Latent MIM, cross-attention decoders allow layerwise conditioning on visible latents, effectively integrating spatial cues. Low-depth, capacity-controlled decoders prevent them from dominating encoder function and optimize high-level representation reconstruction.
The paper experimentally validates Latent MIM by demonstrating superior semantic feature learning over pixel-based methods across various downstream tasks. For instance, Latent MIM achieves 50.1% nearest neighbor classification accuracy, marking significant improvements. This variant requires no supervised fine-tuning and shows enhanced performance in unsupervised scene segmentation, video object segmentation, and few-shot learning scenarios.
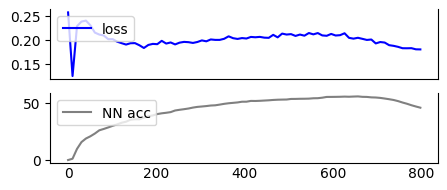
Figure 4: Training progress indicating remarkable improvements over latent reconstruction objectives and semantic correlation mitigation strategies.
Real-World Implications and Future Directions
Latent MIM holds promise for semantically potent and locally informative visual representations which are imperative for real-world applications such as object detection, scene understanding, and video analytics without extensive labeled datasets. Going forward, exploring hybrid models that combine latent MIM with other self-supervised and contrastive objectives can enable robust frameworks tailored for specific domains.


Figure 5: Comparison of visual semantics capture ability, highlighting the efficacy of Latent MIM over traditional pixel-based approaches, demonstrated through unsupervised segmentation task.
Conclusion
By navigating complex challenges in latent modeling of masked representations, Latent MIM exemplifies advancements towards capturing high-level semantics in a self-supervised framework. The paper underscores the importance of addressing intrinsic optimization hurdles to unleash latent MIM's potential without relying on fine-tuning, indicating a promising direction for future research in efficient and effective self-supervised visual representation learning.

