- The paper presents a comprehensive survey that evaluates LLM advancements for translating natural language queries into SQL commands.
- It details methodologies including prompt engineering, fine-tuning techniques, and schema linking to improve SQL generation.
- The survey outlines future directions focused on privacy, autonomous agents, and handling complex schemas in real-world applications.
A Survey on Employing LLMs for Text-to-SQL Tasks
This paper presents a comprehensive survey of employing LLMs for Text-to-SQL tasks, addressing the challenges of converting natural language queries into SQL queries, which facilitates easier database access for non-expert users. The survey examines the various strategies associated with the application of LLMs, focusing on the advancements, challenges, and future directions within the context of Text-to-SQL.
Background
LLMs
LLMs have gained prominence due to their large-scale parameterization and pre-training on extensive datasets, resulting in exceptional performance in a variety of NLP tasks. These models, such as GPT-4 and LLaMA, are built on transformer architectures and leverage scaling laws, which correlate model performance to the size of the parameters, dataset, and training duration. The emergent capabilities of LLMs, including few-shot learning and instruction-following, are pivotal to their success.
Text-to-SQL Challenges
The task of generating SQL queries from natural language involves converting linguistic inputs to structured queries that can interact with databases. The complexity arises from the need to understand the database schema and translate it into a valid SQL command. Initial methods included template-based approaches, followed by the adoption of Seq2Seq models which offered an end-to-end solution, eliminating intermediate steps like rule-based systems.
Benchmark
The paper discusses benchmark datasets used to evaluate Text-to-SQL models. Traditional datasets like Spider have significantly advanced text-to-SQL research. However, with the evolution of LLMs, there is a need for more challenging datasets, such as BIRD, which introduces complexities like noisy data and domain-specific concepts, and Dr.Spider, which adds adversarial perturbations to test model robustness.
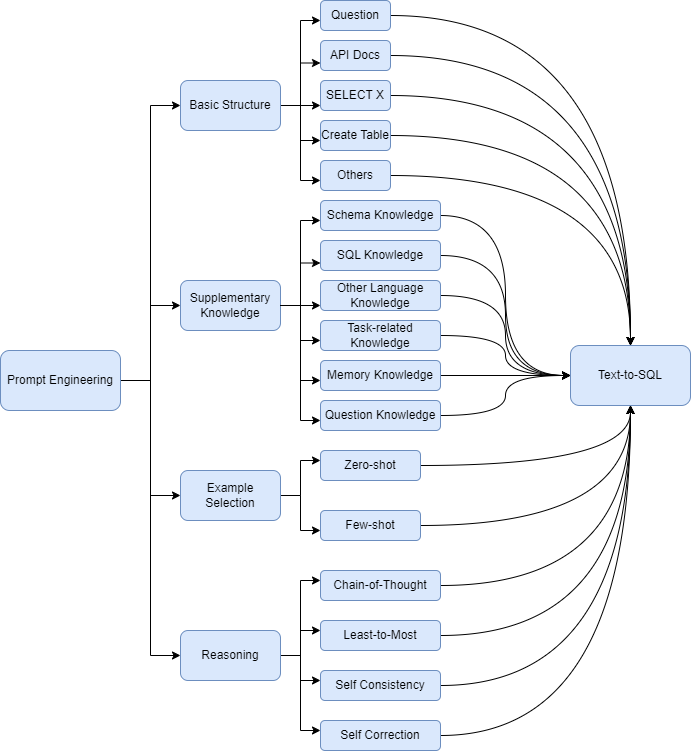
Prompt Engineering
Prompt engineering involves crafting input prompts that enhance LLM performance on specific tasks. The paper categorizes prompt engineering into several approaches:
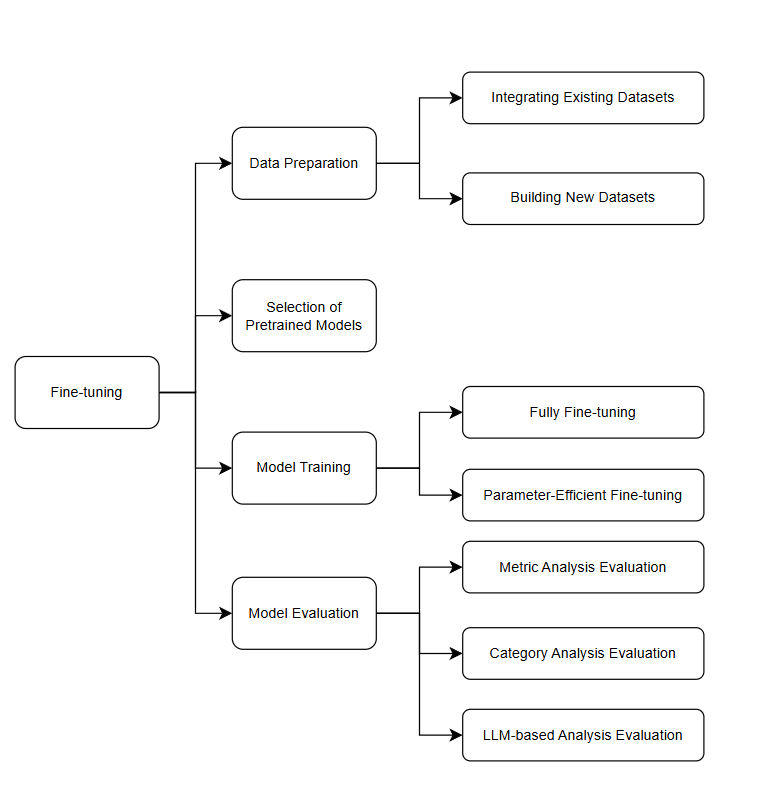
Fine-tuning
Fine-tuning LLMs for Text-to-SQL involves several stages, ensuring the models are well-adapted to the task:
Future Directions
The survey identifies several avenues for future research:
- Privacy Concerns: Addressing the confidentiality issues of API-driven models by exploring private deployment and fine-tuning options.
- Autonomous Agents: Leveraging LLMs as autonomous agents in adaptive systems for more dynamic SQL generation and problem-solving in real-world applications.
- Complex Schema Handling: Developing methods for efficient schema linking and handling large-scale, complex schema in real-world databases to enhance SQL generation accuracy.
- Benchmarking and Real-world Application: Constructing more representative and challenging benchmarks that mimic real-world database environments.
- Integration of Domain Knowledge: Enhancing LLM capabilities with specific domain knowledge using both data-driven tuning and advanced prompt engineering techniques.
Conclusion
The paper provides a detailed exploration of LLMs in the field of Text-to-SQL tasks, covering advancements in prompt engineering and fine-tuning methodologies. It lays the groundwork for enhancing text-to-SQL systems by proposing future research directions and emphasizing the continued evolution of models to meet real-world challenges.