- The paper introduces an adaptive serving strategy that deploys partial expert quantization to tune performance and reduce memory usage.
- It demonstrates a balance between token generation throughput and minimal perplexity increases using the Mixtral 8x7B MoE model.
- The proposed method efficiently partitions inference tasks between GPU and CPU for dynamic resource adaptation in constrained environments.
Mixture of Experts with Mixture of Precisions for Tuning Quality of Service
Introduction
Mixture-of-Experts (MoE) architectures have become a critical component in improving performance for NLP tasks. These models harness multiple parallel feed-forward (FF) layers, known as experts, allowing them to scale significantly in size and outperform dense models through increased specialization. However, deploying these models for inference presents challenges due to their massive memory and computational demands. This paper addresses these issues by introducing an adaptive serving approach for deploying MoE models in resource-constrained environments. This method leverages partial quantization of experts and adapts to varying user-defined constraints and fluctuating resources. The approach is demonstrated using a Mixtral 8x7B MoE model, showcasing adjustable token generation throughput and minimal increases in perplexity across several language modeling datasets.
Adaptive Inference Partitioner and Planner
The adaptive serving approach introduces a novel partitioning and planning system that adjusts the deployment of MoE models in multi-tenant environments, characterized by dynamic resource allocation and fluctuating constraints. The system targets the effective management of GPU memory by leveraging partial expert quantization and dynamic allocation between GPU and CPU. This method enables a balance between computational throughput and output quality, as evidenced by the ability to fine-tune token generation rates from 0.63 to 13.00 tokens per second, depending on available memory and user preferences.
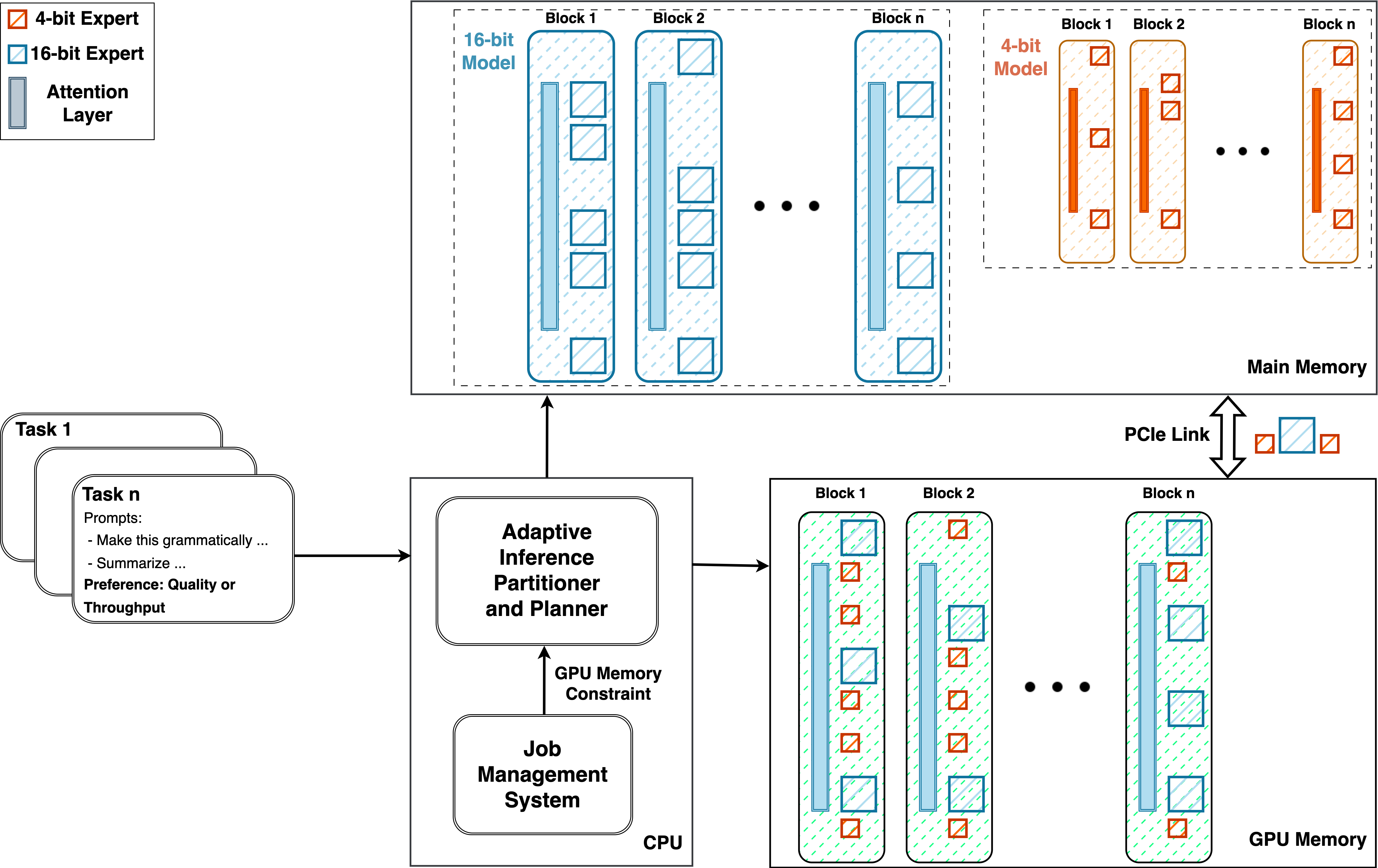
Figure 1: An adaptive inference partitioner and planner for deployment of MoE models.
Evaluation
Experimental Setup
Evaluation is performed using the Mixtral 8x7B MoE model and benchmarks on three datasets: WikiText2, PTB, and C4. Tests are executed on an NVIDIA A100 GPU with specific emphasis on memory management and expert quantization to assess the approach's efficiency in maintaining output quality with minimal memory usage.
Results
The results, demonstrated across various configurations, illustrate the trade-offs between memory usage and model output quality. Partial quantization offers significant memory footprint reduction with negligible decreases in performance, as seen in perplexity metrics. The experiment demonstrates that perplexity slightly increases with the number of 4-bit experts, revealing the limitations of partial expert quantization and its impact on model effectiveness.
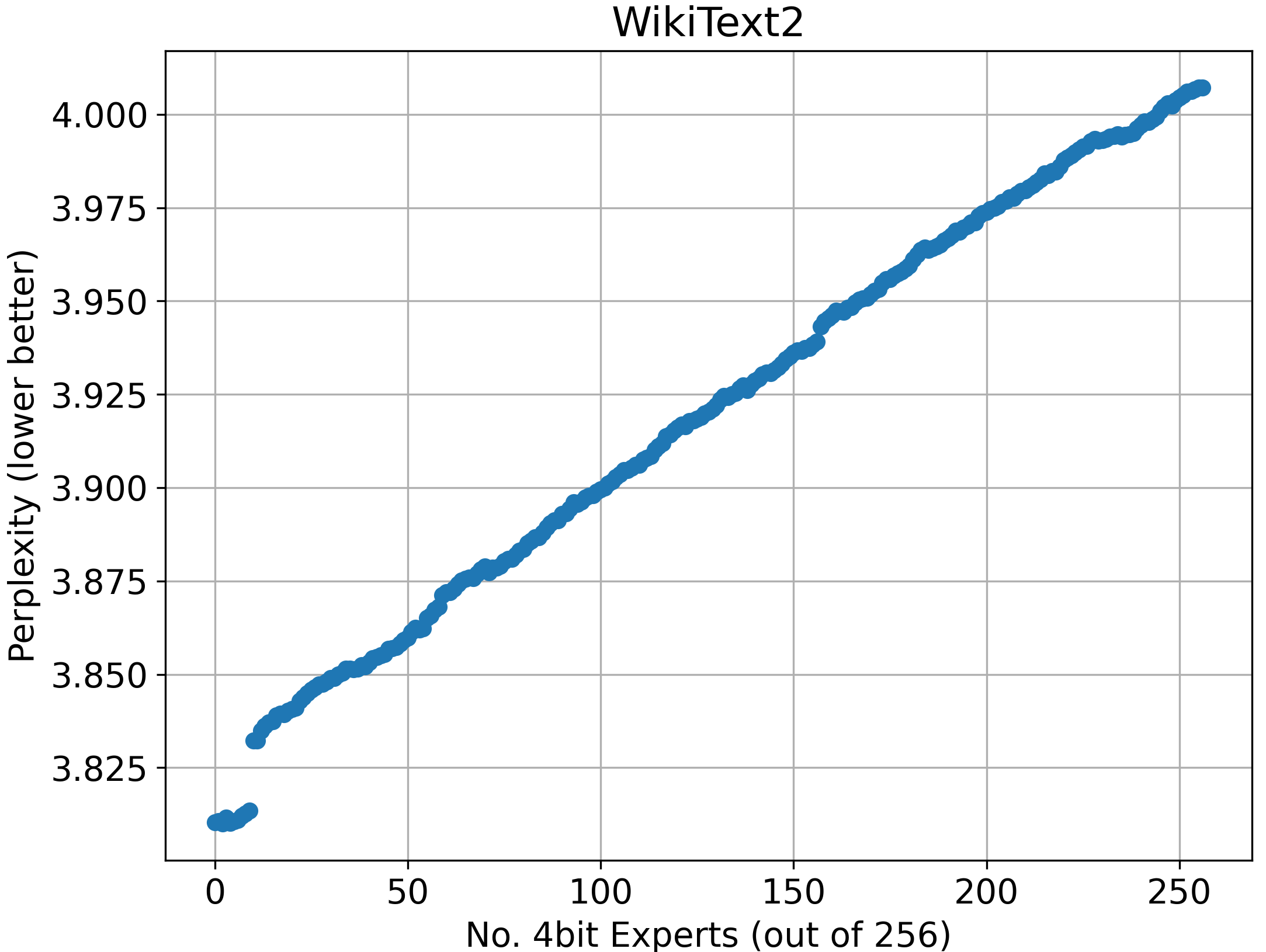
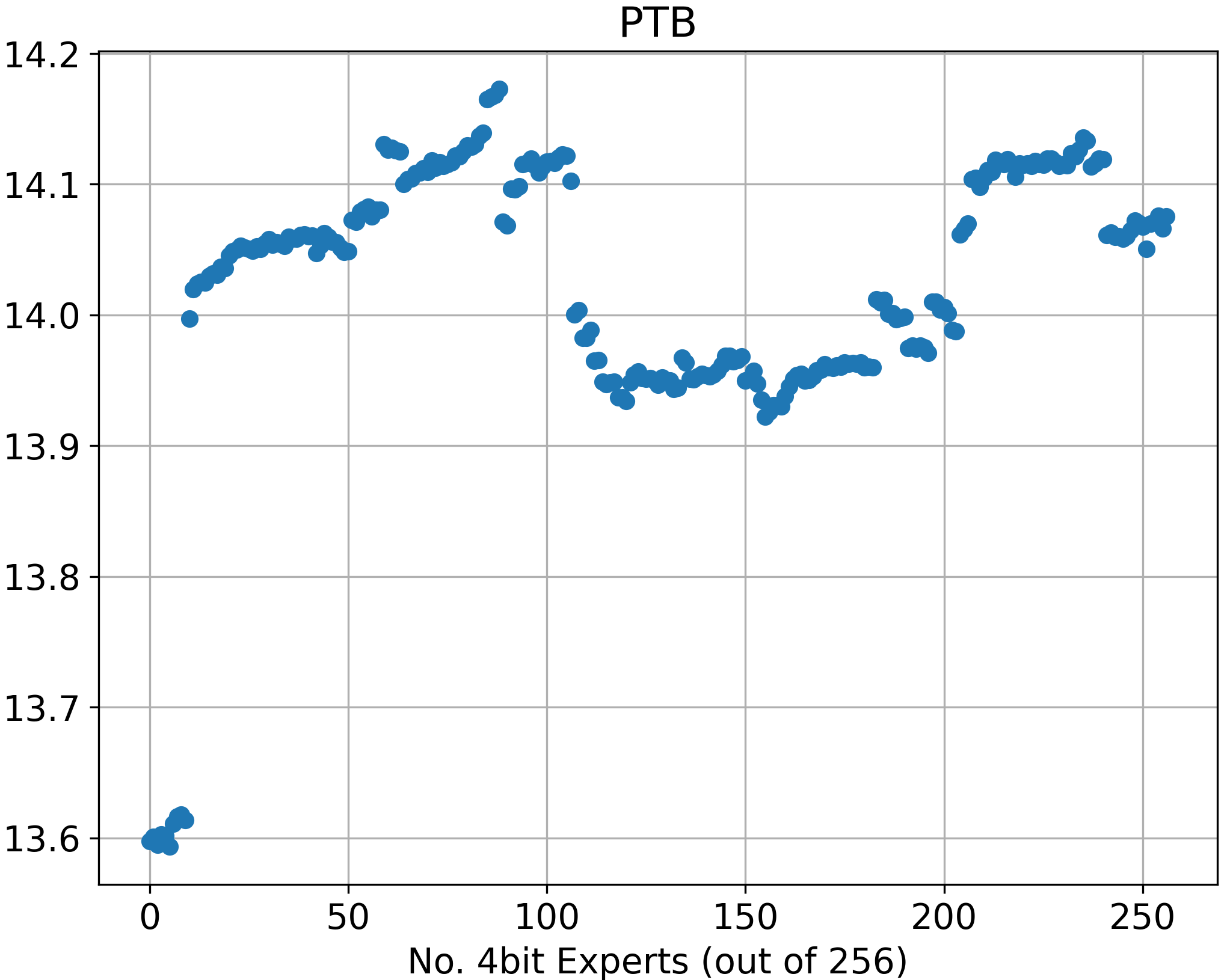
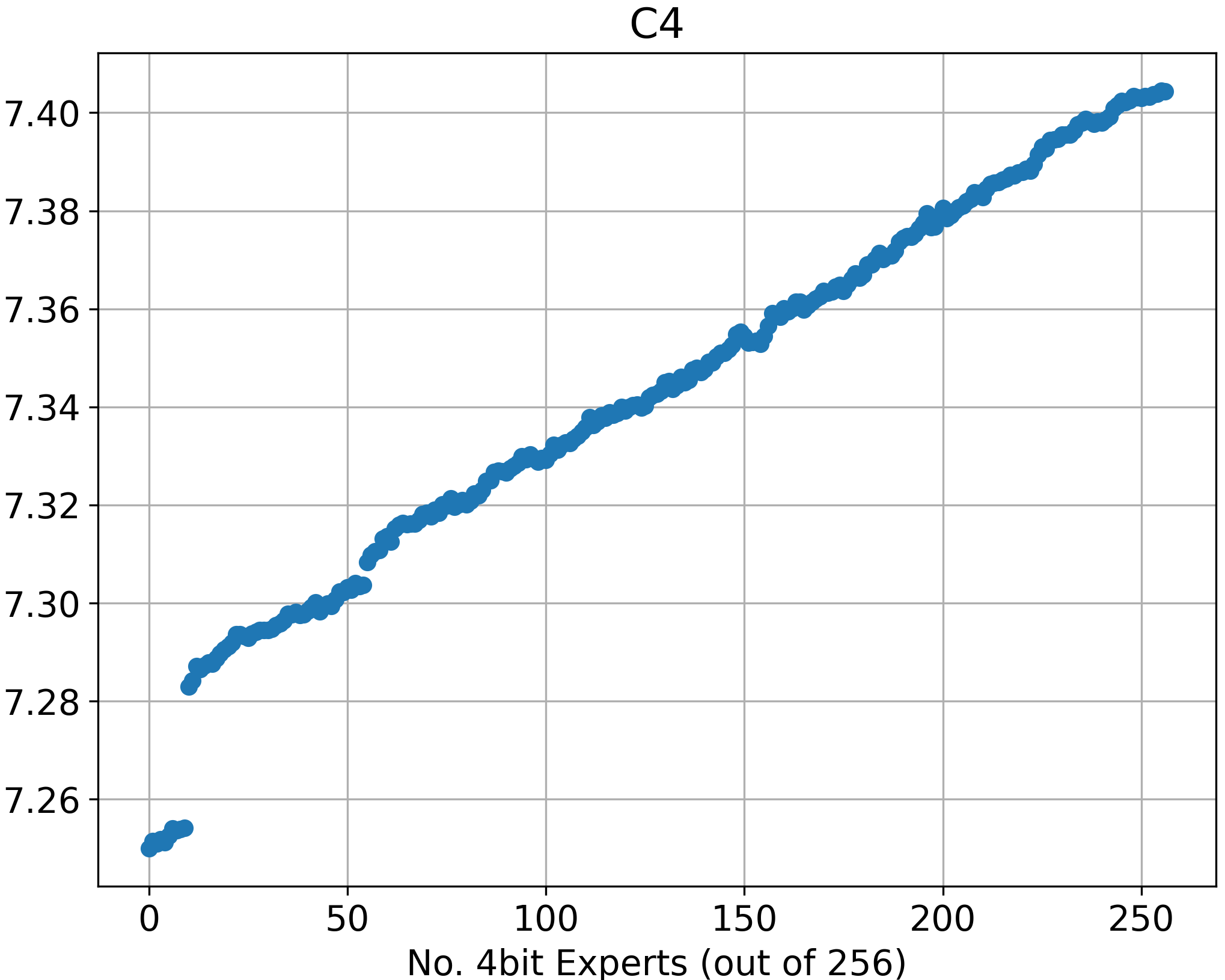
Figure 2: Perplexity of the expert-only partially quantized model across varying numbers of 4-bit experts (out of a total of 256 experts).
Moreover, the throughput analysis shows how efficient expert offloading can drastically improve performance under constrained GPU memory scenarios. The tested configurations confirm hyperbolic growth in throughput with increased memory and quantization.
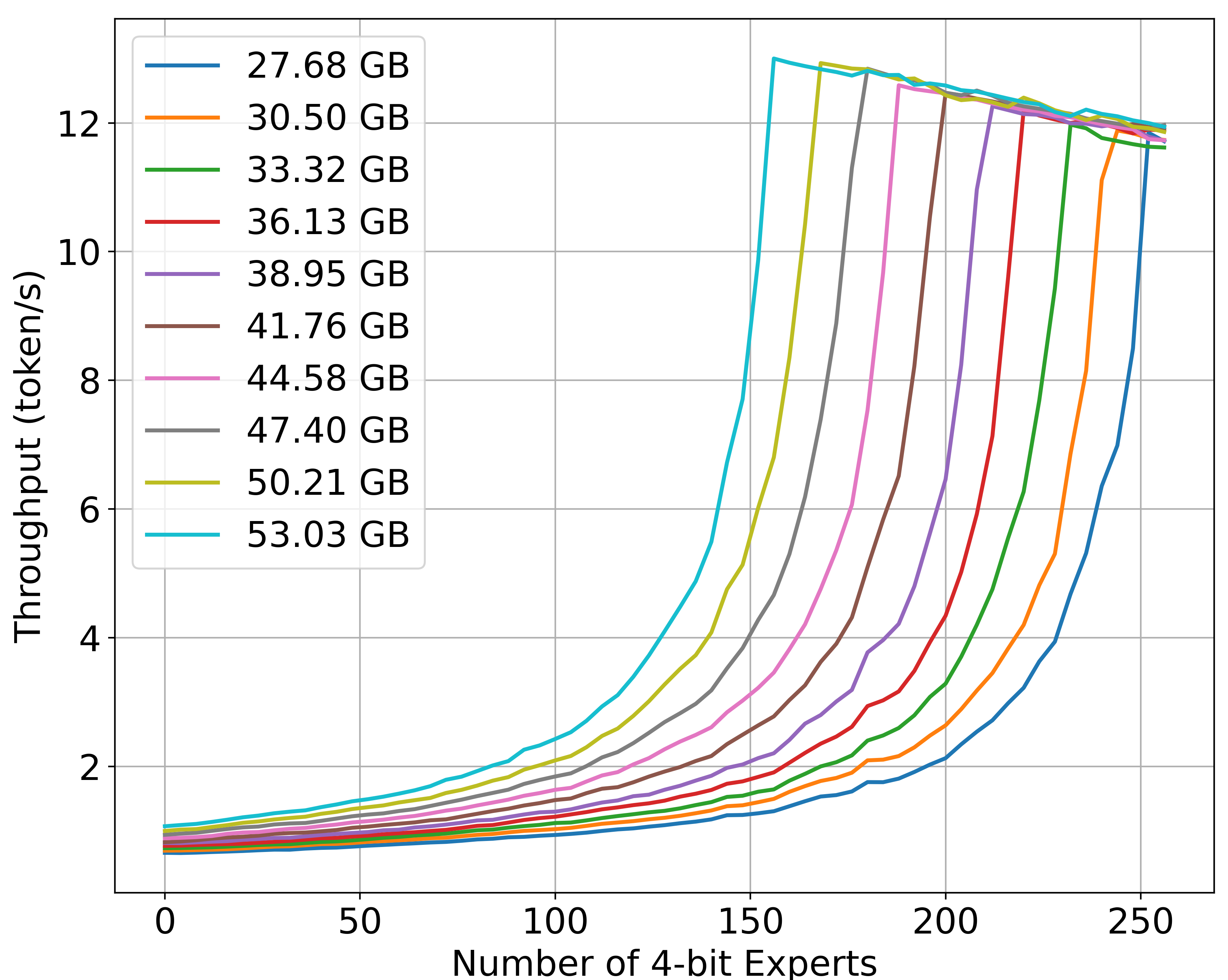
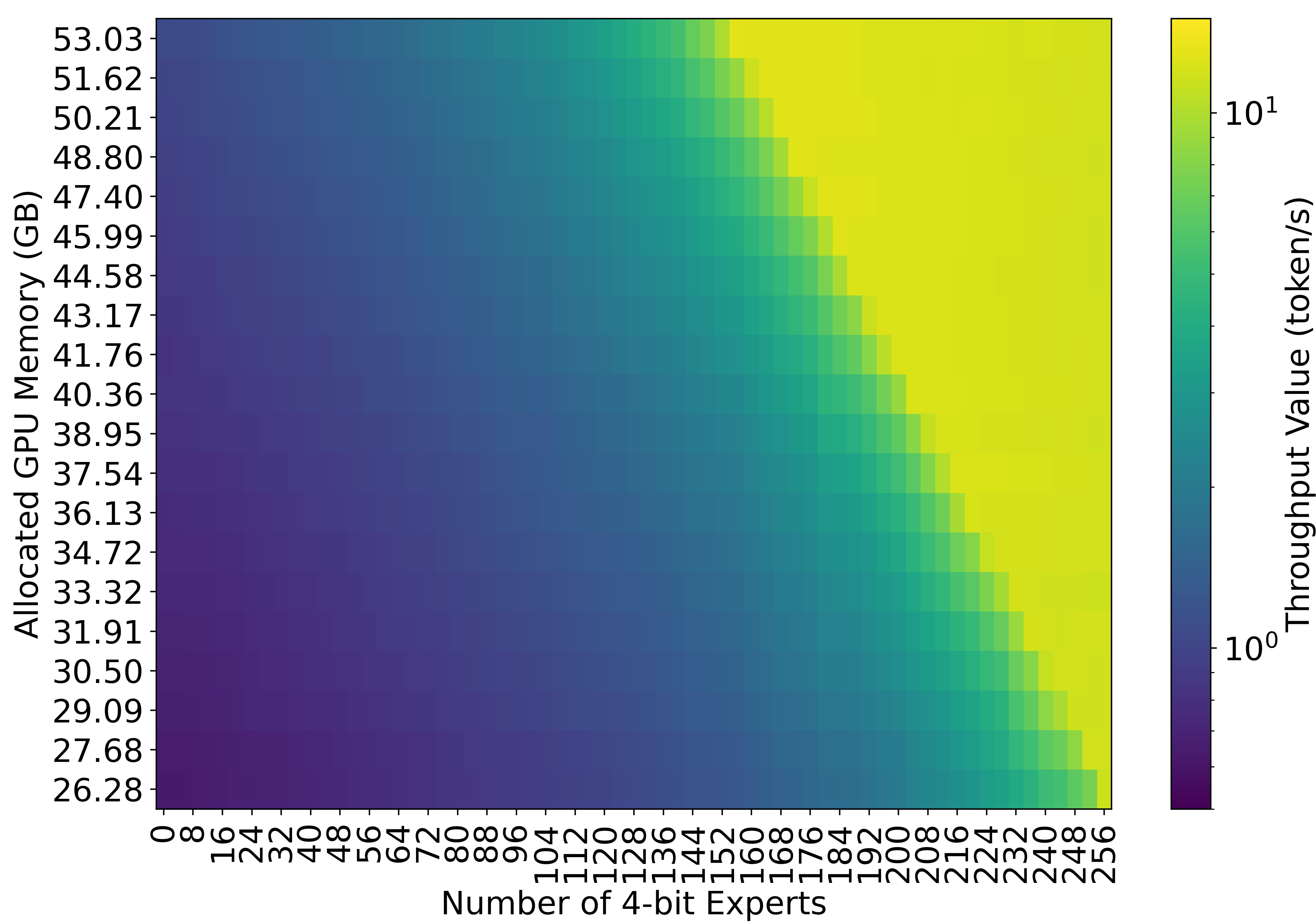
Figure 3: Throughput of an expert-only partially quantized Mixtral 8x7B MoE model running on an NVIDIA A100 GPU under different amounts of available memory.
Conclusion
This paper presents an adaptive serving strategy that addresses critical deployment challenges for MoE models in constrained environments. By employing a mixture of precisions through partial expert quantization, it enables nuanced control over performance metrics like throughput and perplexity, appropriate in dynamic settings with shifting resource constraints. These findings are pivotal for practical applications in settings with limited computational resources, illustrating the potential for continued research and refinement in model deployment methodologies for large-scale NLP systems.

