- The paper demonstrates that mixed training regimes effectively balance early exit performance and computational efficiency compared to disjoint and joint methods.
- The study employs loss landscape visualization, numerical rank, and mutual information analysis to assess training dynamics and feature representation.
- Empirical evaluations on CIFAR-10, CIFAR-100, and Imagenet confirm that optimizing internal classifier placement and backbone training enhances overall accuracy.
How to Train Your Multi-Exit Model? Analyzing the Impact of Training Strategies
Introduction
The efficiency of deep neural networks (DNNs) has been significantly enhanced through the incorporation of early-exit mechanisms. Such architectures utilize trainable @@@@2@@@@ (ICs) at various network depths, allowing for earlier terminations in the forward pass when inputs are classified with high confidence. This study evaluates various training regimes to optimize early-exit architectures by examining their theoretical and empirical performances, particularly focusing on the implications of disjoint, joint, and mixed training approaches.
Training Regimes for Early-Exit Models
The paper systematically categorizes the training regimes of early-exit models into three primary approaches, each with varying implications on model performance and computational efficiency:
- Disjoint Training (Phase 1+3): This regimen trains the backbone network first and then the ICs separately. While it provides a rapid evaluation of early-exit methods without retraining the backbone, the underutilization of joint training limits its effectiveness in leveraging model potential.
- Joint Training (Phase 2): Simultaneously trains both the backbone network and ICs, aligning with conventional approaches. This method integrates learning across all layers but can be less effective if not preemptively optimizing the backbone in isolation.
- Mixed Training (Phase 1+2): Involves initial dedicated training of the backbone, followed by joint training with ICs. This approach capitalizes on a pre-optimized backbone, ensuring all layers are equally refined.
Theoretical Analysis of Training Regimes
Loss Landscape
The study employs visualizations of the loss landscape to understand parameter optimization stability. Mixed and joint regimes exhibit smoother, more optimal convergence patterns relative to disjoint training (Figure 1).
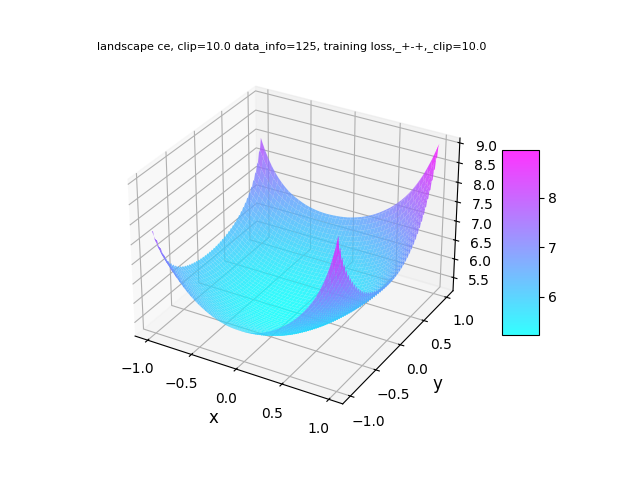
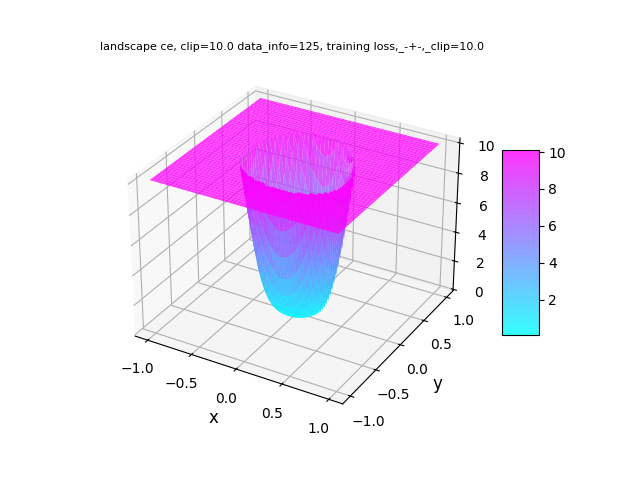
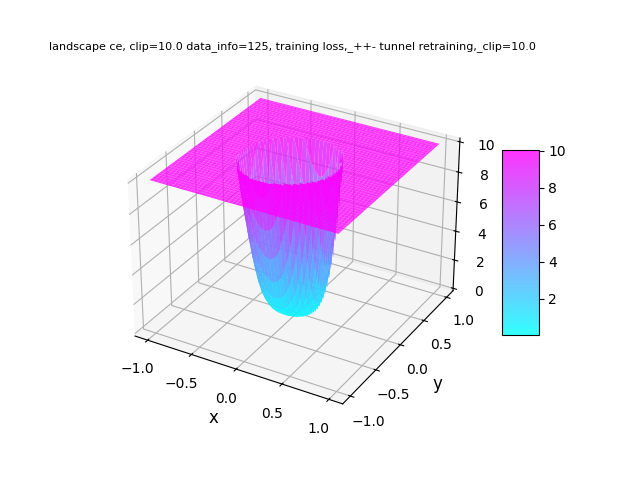
Figure 1: Training loss landscapes: comparison for Disjoint, Joint, and Mixed regimes (left to right).
Numerical Rank
Through numerical rank analysis of intermediate representations, the research provides insights into the expressiveness of network layers, with mixed training yielding a balanced distribution of feature representation strength across layers (Figure 2).
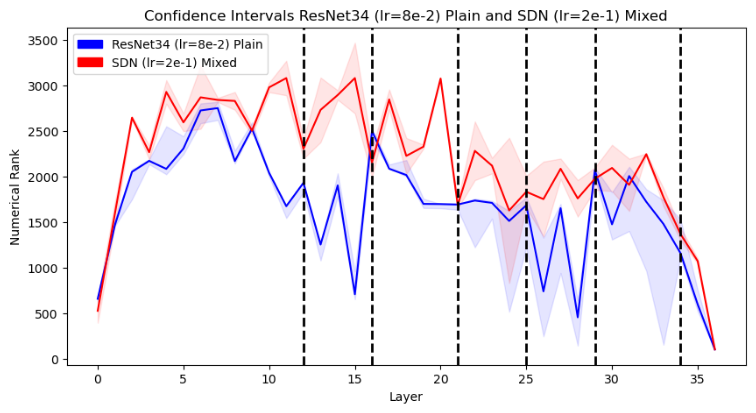
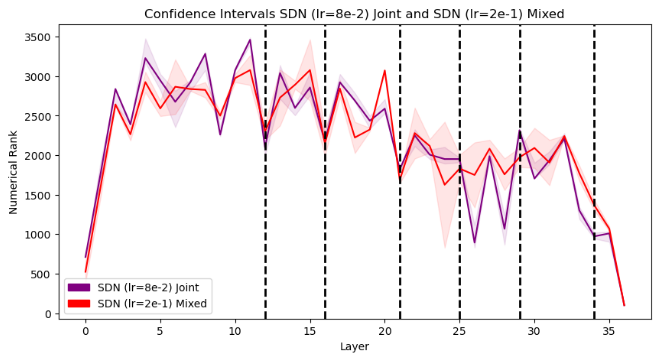
Figure 2: The change in expressiveness of the network from Phase 1 (backbone) to Phase 2 (backbone+ICs).
By analyzing mutual information between inputs and hidden representations, the study reveals that joint regimes might be more appropriate for datasets necessitating early exits, whereas mixed regimes offer a balanced, robust approach for varied input complexities.
Empirical Evaluation
The empirical studies span several datasets including CIFAR-10, CIFAR-100, and Imagenet across prominent early-exit methods like Shallow-Deep Networks (SDN) and Global Past-Future (GPF). Performance metrics demonstrate the superiority of the mixed regime in leveraging computational resources effectively and maintaining high accuracy, particularly when used within transformers like ViT.
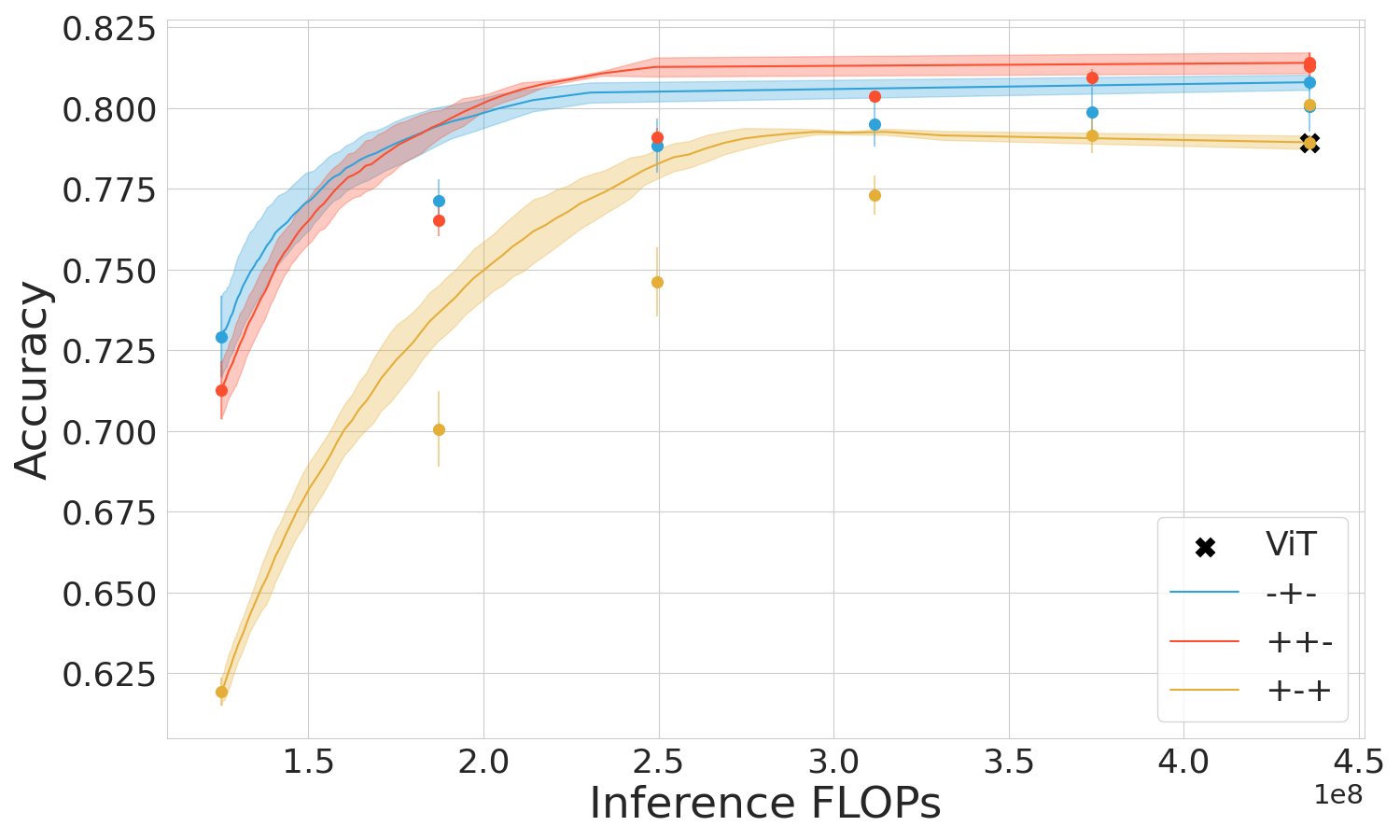
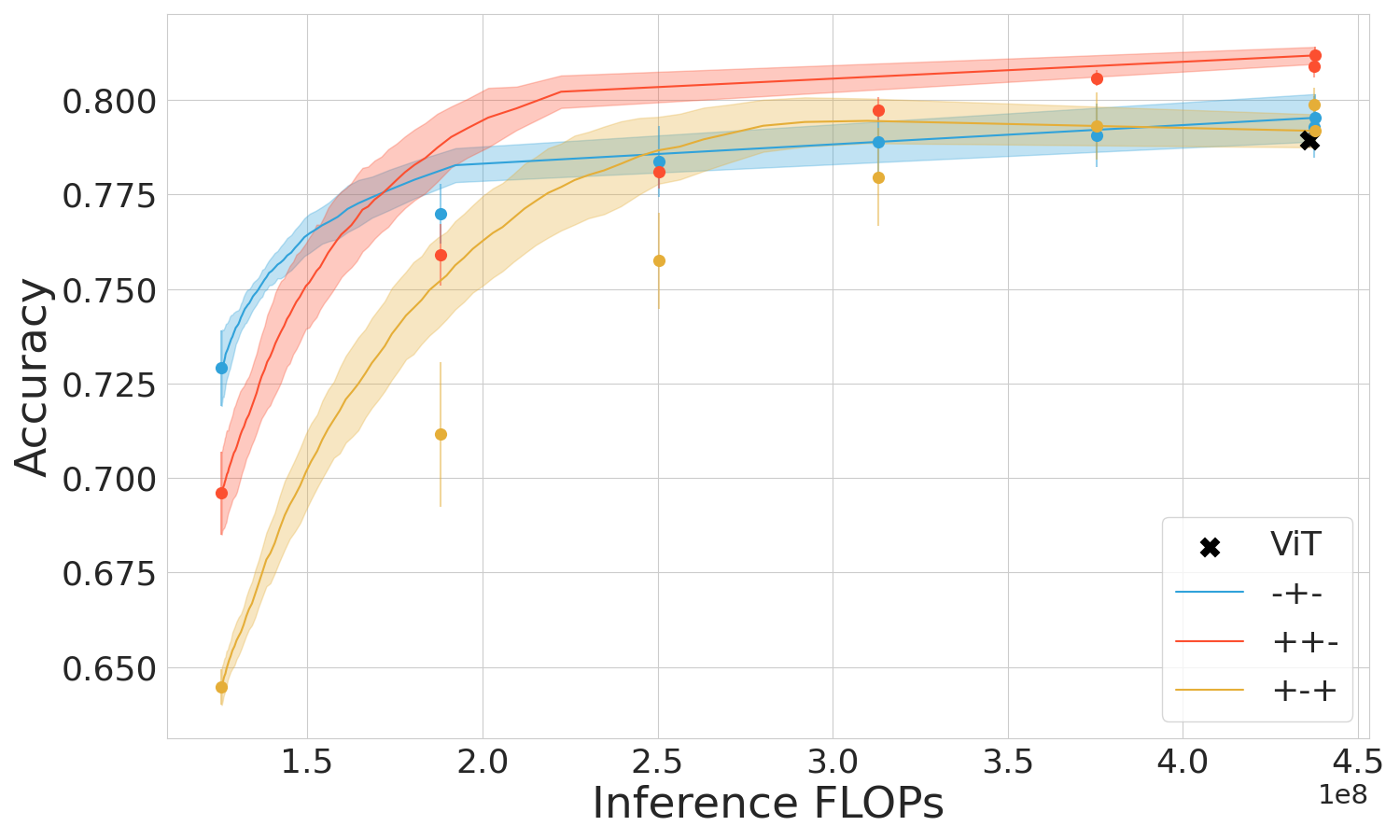
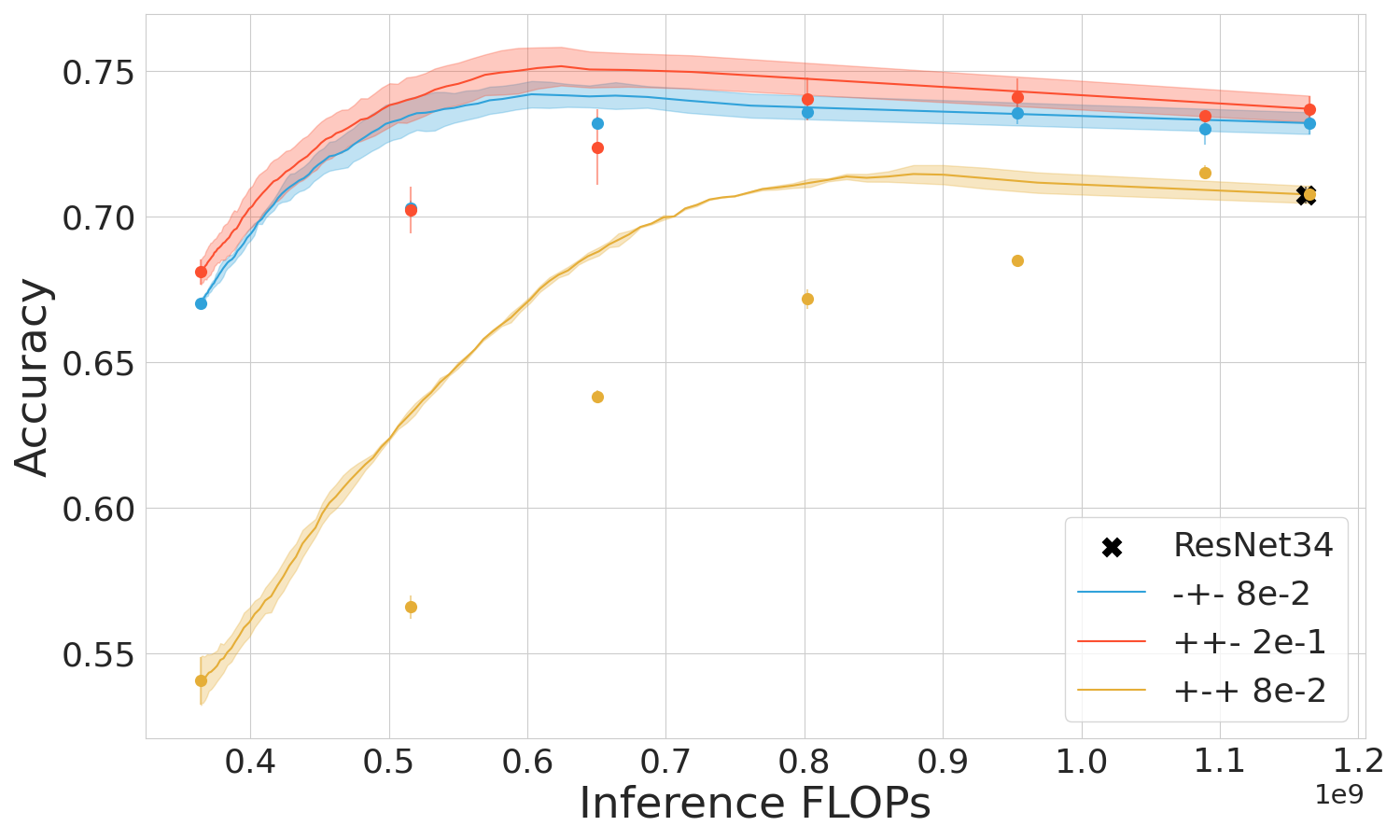
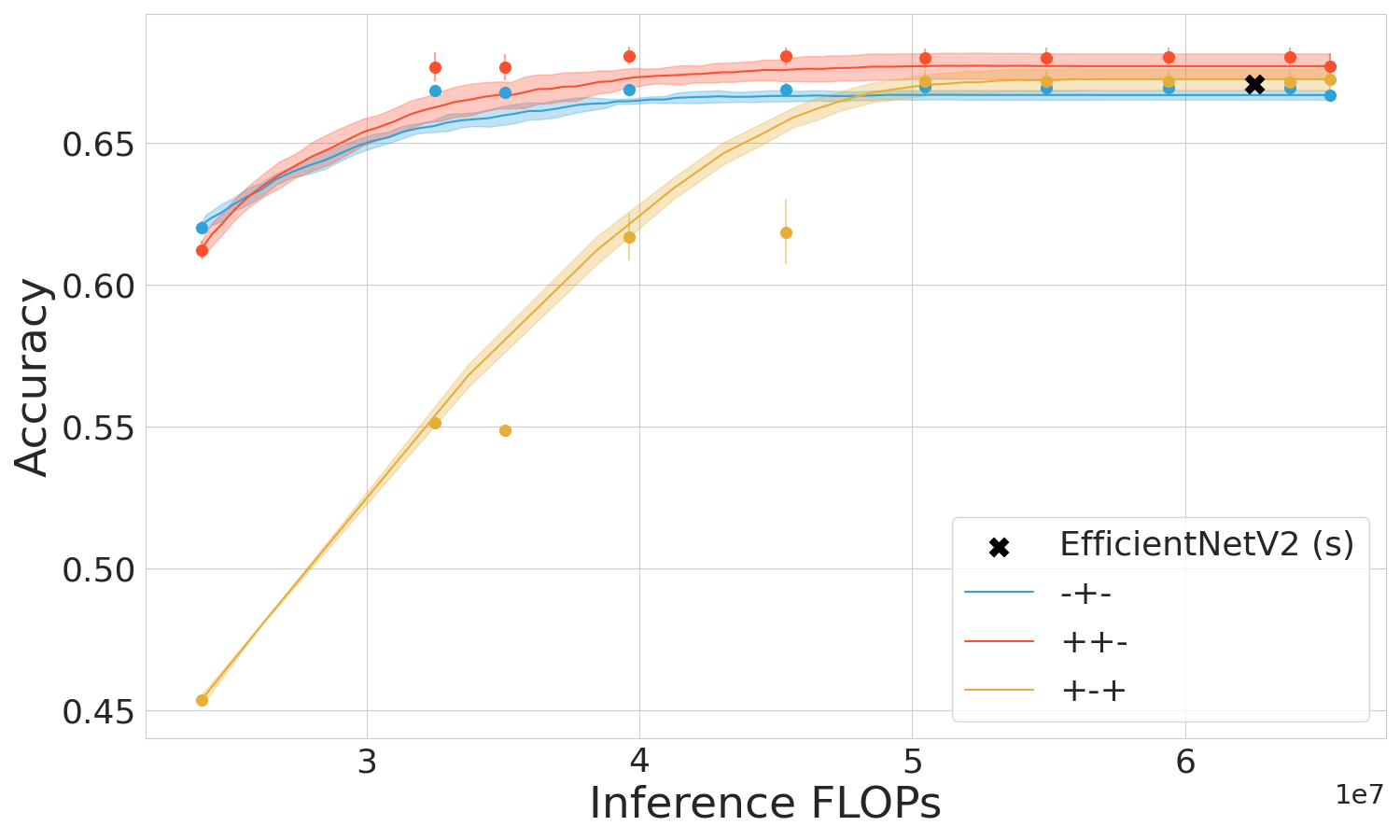
Figure 3: ViT and SDN performance in three training regimes.
Evaluation of IC Placement and Size
IC positioning frequency and classifier size significantly influence performance. More frequent placements benefit from mixed training, optimizing early-exit effectiveness without compromising accuracy due to classifier redundancy or excess.
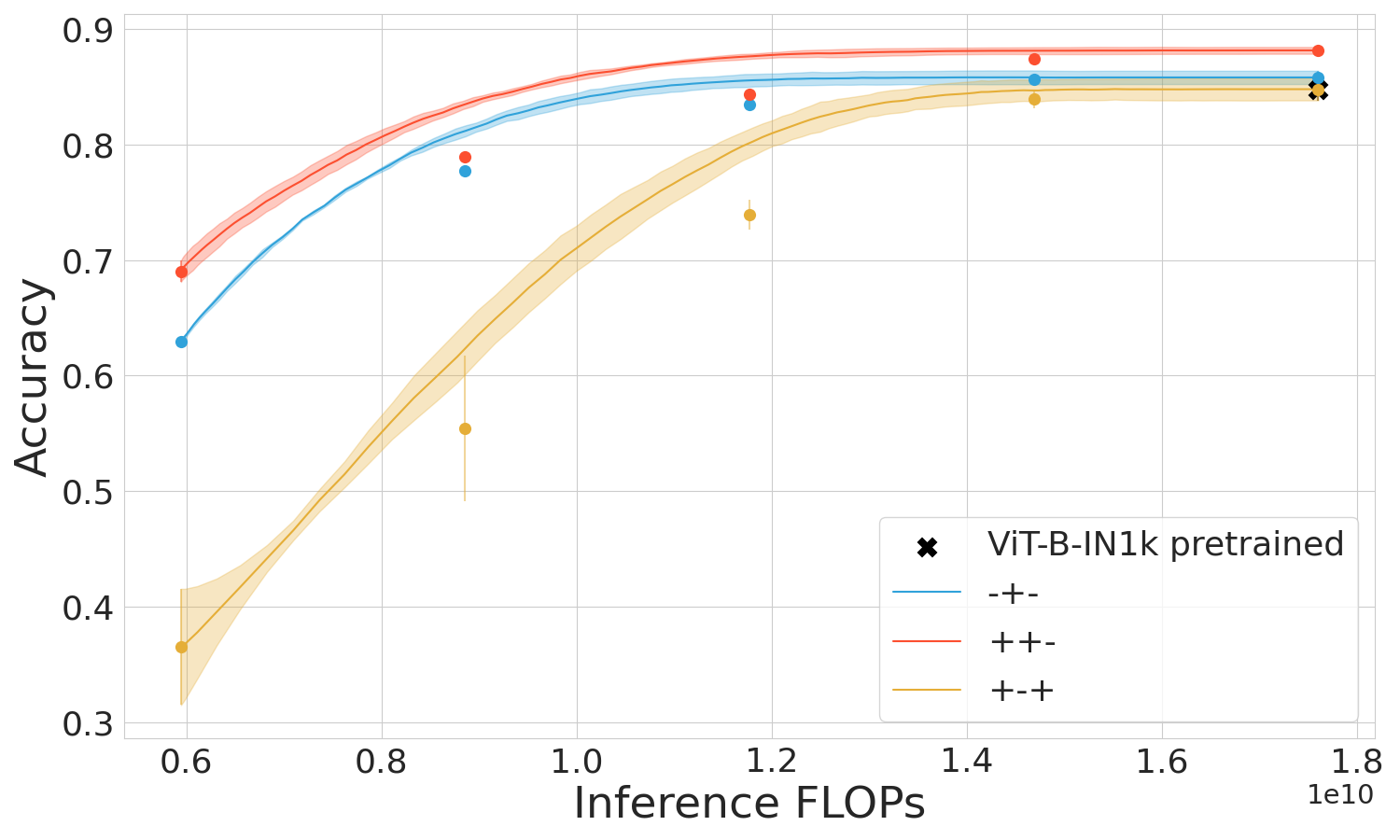
Figure 4: Performance when ICs are placed after each of the first 4 layers.
Gradient Rescaling and Learning Rate
Gradient rescaling was tested to evaluate its effects across training regimes. Standard mixed training finished without scaling enhancements showed robustness in general applications. Ensuring a well-trained backbone phase proves central for maximizing mixed training efficacy without excessive detriment in computationally constrained scenarios (Figure 5).
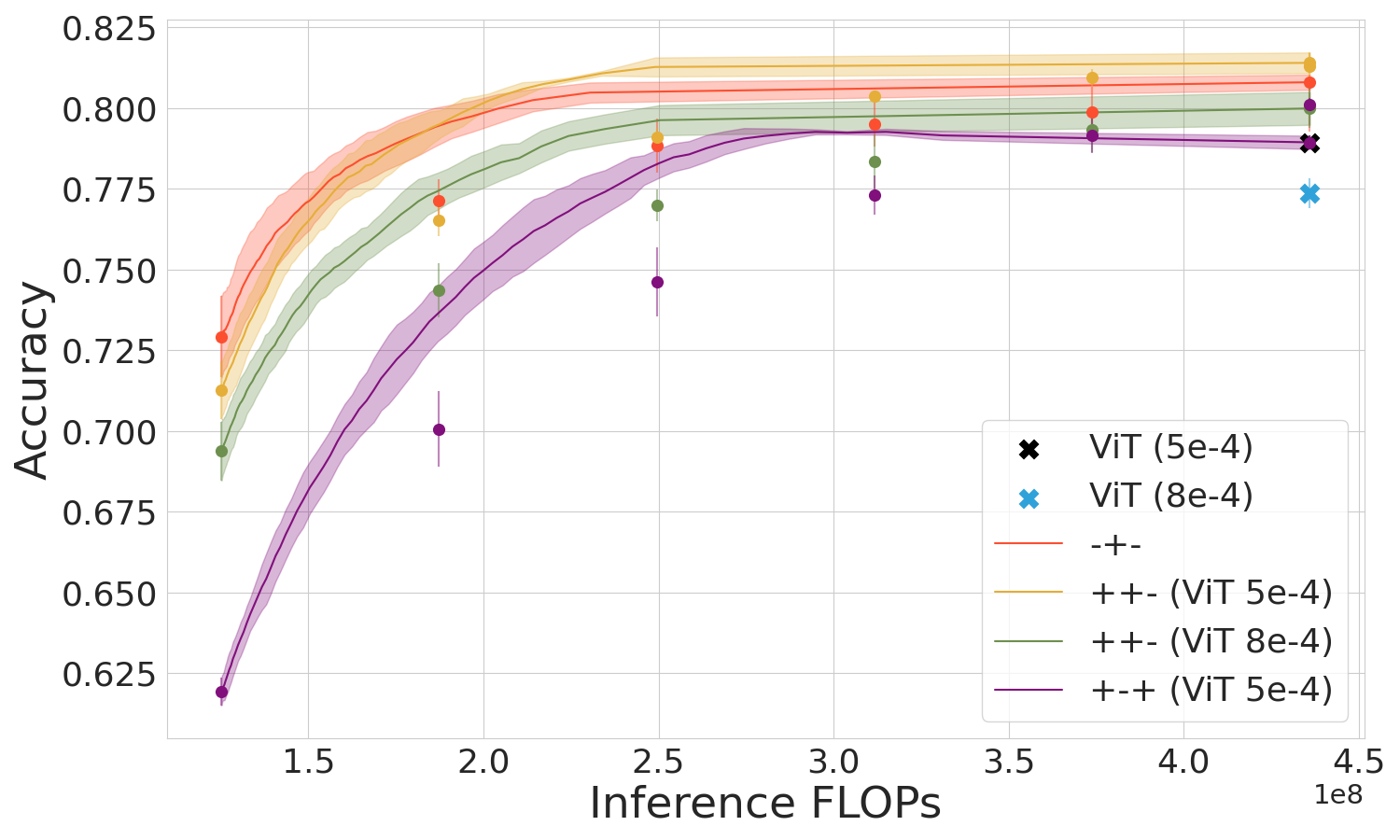
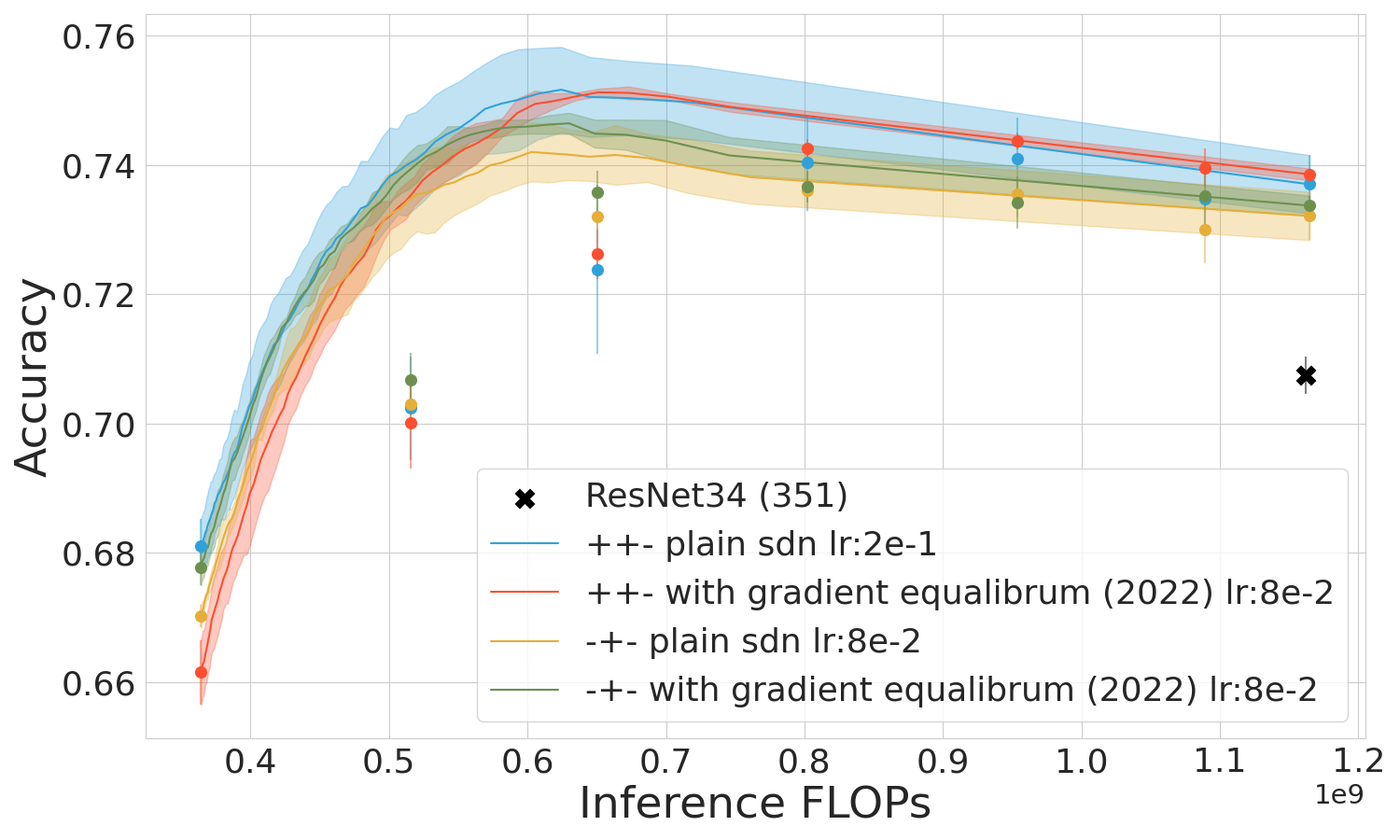
Figure 5: Mixed training performance drops with undertrained backbone (SDN, ViT).
Conclusion
The study establishes the mixed training regime as the superior approach for optimizing early-exit architectures, maximizing the potential of internal classifiers and reducing computational burdens in diverse datasets and architectures. Future investigations could explore adaptive strategies tailored to optimize for particular early-exit implementations, fostering a broader adoption of efficient deep learning systems.
