- The paper introduces LazyLLM which dynamically selects and prunes tokens based on attention scores to reduce computational overhead during LLM inference.
- It employs an Auxiliary Cache to efficiently revive pruned tokens, ensuring the model maintains comparable accuracy without extra fine-tuning.
- Experimental results demonstrate a TTFT speedup of 2.34× on Llama 2 in multi-document QA tasks by reducing unnecessary token computations.
LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM Inference
Introduction
The paper "LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM Inference" explores methods to address the inefficiencies inherent in transformer-based LLMs, specifically targeting the prefilling stage during inference. Traditionally, this stage involves computing key-value (KV) pairs for all tokens in long prompts, a process that can slow down the generation of the first token. The authors propose LazyLLM, a technique that dynamically chooses influential tokens in different generation steps, selectively computing their KV pairs and deferring less important tokens to minimize computational overhead without compromising accuracy.
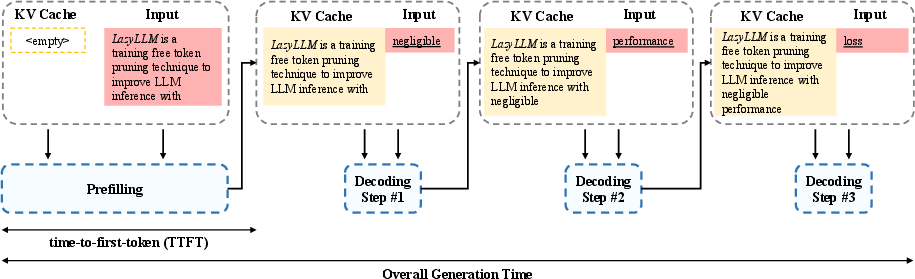
Figure 1: Prompt-based LLM inference can be divided into two sequential stages: prefilling and decoding. For long prompts, the first token generation during prefilling stage could be slow.
LazyLLM Framework
LazyLLM introduces an innovative approach to token pruning during both prefilling and decoding stages. Unlike static methods that compress prompts in one step, LazyLLM dynamically adjusts token subsets depending on their relevance throughout various stages of generation. This is achieved by leveraging attention scores to ascertain token importance, progressively pruning less critical tokens at each transformer layer.
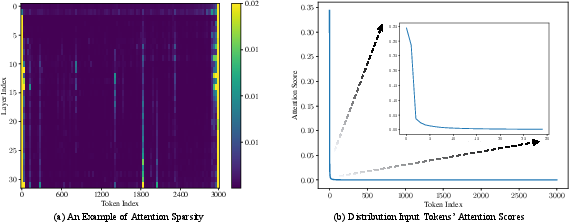
Figure 2: We visualize the attention scores of input tokens in the prompt w.r.t to the next token for each layer of Llama 2 7B.
LazyLLM employs a layer-wise pruning strategy, using the attention maps to calculate confidence scores for each token, facilitating an adaptive pruning decision based on the percentile selection strategy.
Token Pruning and Aux Cache
The method uses token pruning to streamline computations: unimportant tokens are deferred, and essential tokens are prioritized. During prefilling, LazyLLM identifies tokens critical for immediate token prediction. The paper introduces an Auxiliary Cache (Aux Cache) to store the hidden states of pruned tokens, ensuring these tokens can be revived efficiently in later steps without redundant recomputation.

Figure 3: Comparison between standard LLM and LazyLLM, showcasing its efficiency in token prediction.
LazyLLM's progressive pruning across transformer layers helps balance between computational savings and maintaining model accuracy. The integration of Aux Cache guarantees that LazyLLM's runtime never exceeds that of the baseline model while optimizing computational resources.
Experimental Results and Analysis
The implementation of LazyLLM on models like Llama 2 and XGen demonstrated notable improvements in Time-to-First-Token (TTFT) speedup across various tasks without requiring model fine-tuning. For example, in multi-document question-answering tasks, LazyLLM achieved a TTFT speedup of 2.34× on the Llama 2 model, while maintaining performance levels comparable to or slightly reduced compared to baseline methods.
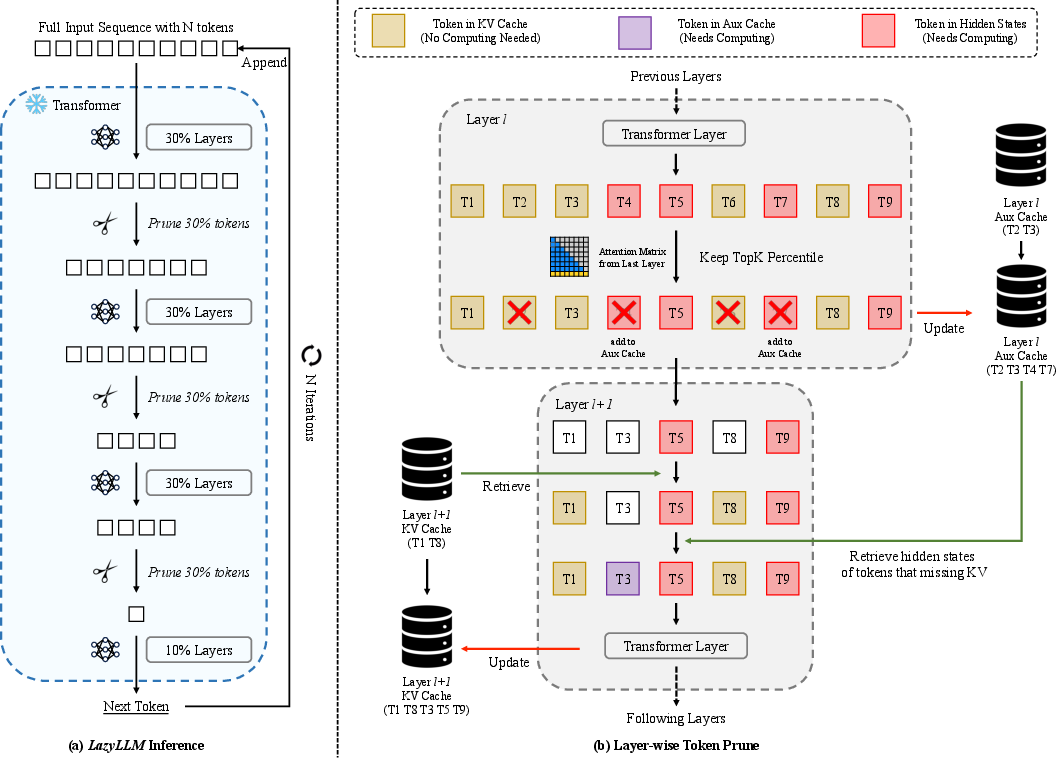
Figure 4: Overview of the LazyLLM framework showing how the model prunes and selects different token subsets.
Importantly, LazyLLM's integration does not necessitate any alterations to model parameters, ensuring broad applicability across different LLM architectures.
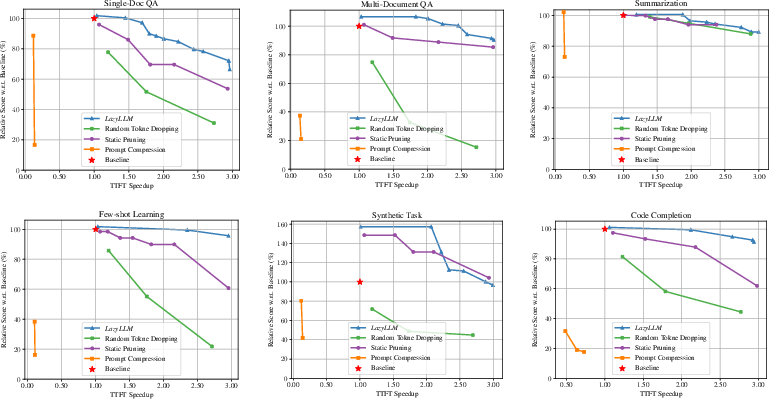
Figure 5: TTFT speedup accuracy comparison for Llama 2 7B across different tasks.
The results demonstrate LazyLLM's effectiveness in reducing the percentage of computed prompt tokens, leading to faster generation times and decreased overall computation.
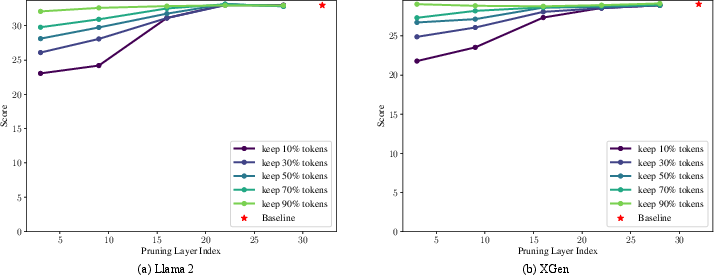
Figure 6: Effect of the locations of pruning layers, and the number of tokens pruned.
Drop Rate Analysis
The paper provides an analysis of token pruning effects, concluding that later transformer layers exhibit less sensitivity to pruning, and allowing more aggressive token reduction at these stages can enhance speed without significant performance deterioration.
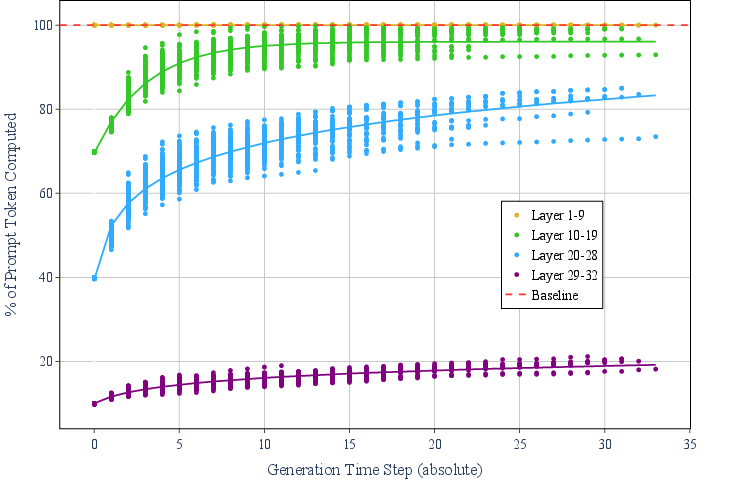
Figure 7: Statistics on number of tokens processed during generation using our LazyLLM technique with Llama 2 7B.
Conclusion
LazyLLM offers a promising solution to optimize LLM inference for long contexts, by dynamically pruning tokens and selectively computing KV pairs. It ensures reduced computational costs and improved TTFT, promising to be seamlessly integrated into existing models without a need for tuning, broadening its scope of application. Future work could explore extending these techniques to other architectures and further refining dynamic pruning strategies to enhance efficiency and performance.