- The paper introduces REMALIS, a novel framework for multi-agent coordination that propagates intentions and employs recursive reasoning for dynamic planning.
- It employs modular planning, grounding, and cooperative execution modules, using techniques like graph neural networks and cross-attention to convert abstract plans into actions.
- Empirical evaluations on traffic flow and web activities datasets demonstrate improved coordination and reduced errors relative to state-of-the-art models.
Intention Propagation and Recursive Agent Learning in Multi-Agent Systems
Recent advances propose novel methods to address collaboration challenges in Multi-Agent Reinforcement Learning (MARL) by integrating LLMs into the frameworks. The paper "Towards Collaborative Intelligence: Propagating Intentions and Reasoning for Multi-Agent Coordination with LLMs" introduces REMALIS, an innovative multi-agent system that emphasizes intention sharing, recursive learning, and adaptability.
Framework Overview
The REMALIS framework is distinguished by its focus on intention propagation and recursive multi-agent learning. The agents, propelled by LLMs, communicate their intentions to each other to facilitate shared understanding and coordination. Key to this framework are the planning, grounding, and execution modules, each with distinct responsibilities that enhance multi-agent cooperation through dynamic interactions and feedback loops.
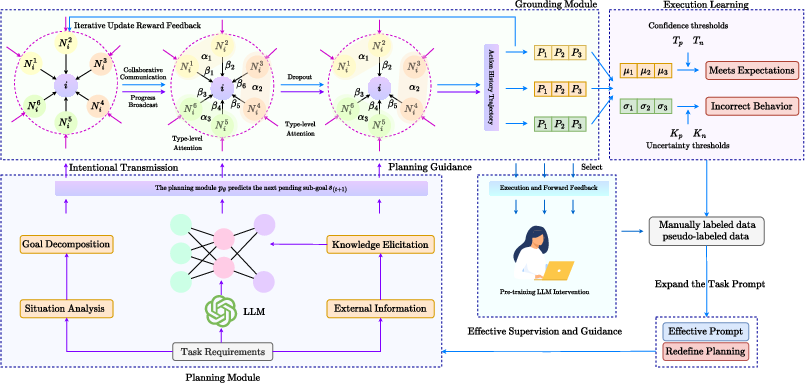
Figure 1: This framework introduces a multi-agent learning strategy designed to enhance the capabilities of LLMs through cooperative coordination. It enables agents to collaborate and share intentions for effective coordination, and utilizes recursive reasoning to model and adapt to each other's strategies.
Planning Module
The planning module is responsible for predicting future goals and sub-tasks based on current intentions, states, and environmental feedback. It operates using a graph neural network (GNN) architecture for encoding and predicting subsequent actions, which aids in adapting plans dynamically to align sub-task dependencies.
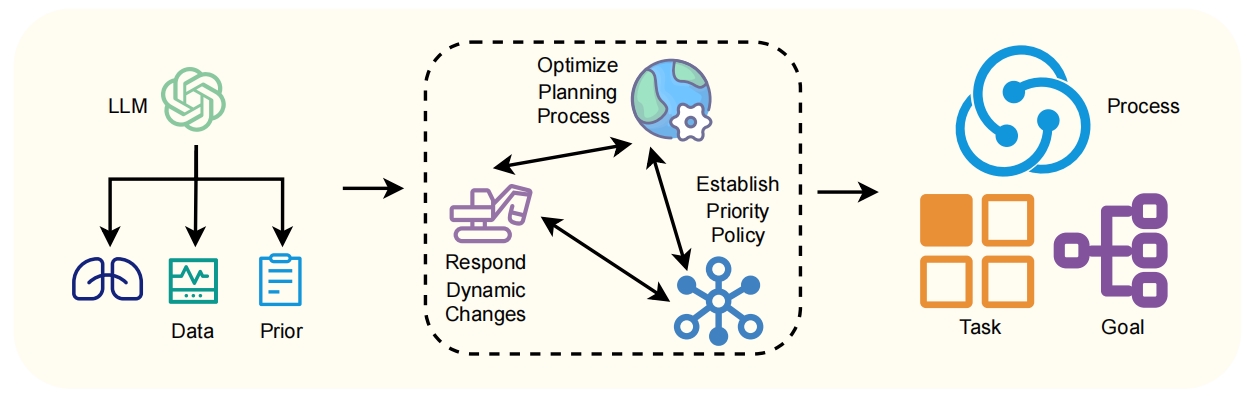
Figure 2: Overview of the proposed REMALIS Planning Module for predicting sub-goals based on current goals, intentions, grounded embeddings, and agent feedback.
Grounding Module
This module contextualizes symbolic embeddings into actionable items by considering the state, intentions, and feedback patterns. Through this process, the grounding module converts abstract plans into concrete, executable actions by employing convolutional feature extractors enhanced with cross-attention mechanisms.
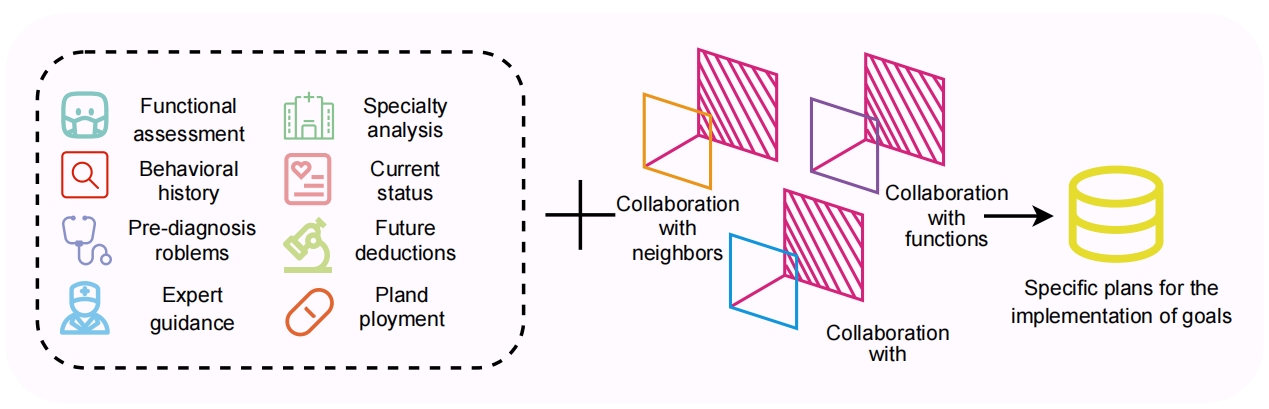
Figure 3: Framework of the proposed REMALIS Grounding Module that contextualizes symbol embeddings using the current state, intentions, and feedback signals.
Cooperative Execution Module
Specialized agents are assigned to specific semantic domains, such as arithmetic or query processing, thus promoting efficiency and reducing overlap. The module emphasizes coordinated action execution by ensuring agents are aware of their peers' intentions and capabilities, informing adjusted actions dynamically based on the evolving context.
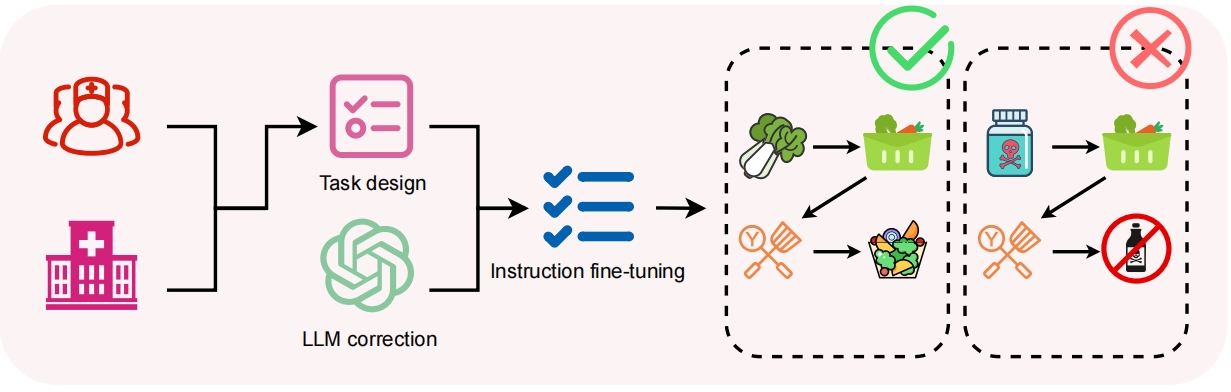
Figure 4: Overview of our REMALIS Cooperative Execution Module consisting of specialized agents that collaboratively execute actions and propagate intentions.
Empirical Evaluation
REMALIS was evaluated on the Traffic Flow Prediction (TFP) and web-based activities datasets, outperforming single-agent and other state-of-the-art frameworks across task difficulty levels.
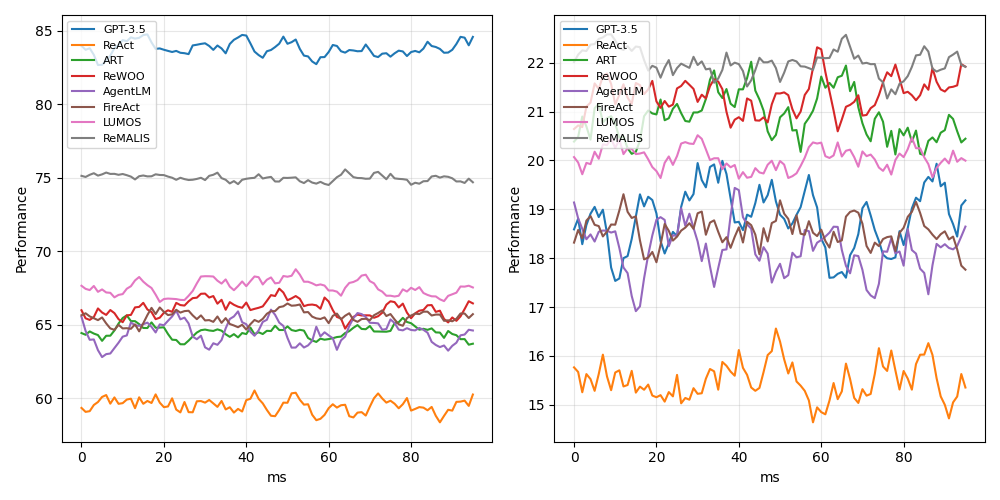
Figure 5: Comparative performance evaluation across varying task difficulty levels for the web activities dataset, which indicates the accuracy scores achieved by REMALIS and several state-of-the-art baselines.
Key findings indicate that REMALIS's designs—integrating intention propagation and bidirectional feedback—substantially improve coordination and reduce errors in task alignment. The framework benefits primarily from its recursive reasoning, enabling enhanced scene comprehension and dynamic re-planning when agent interactions require recalibration.
Limitations and Future Directions
While REMALIS effectively demonstrates the potential for enhanced multi-agent collaboration, it faces challenges in scalability for fully decentralized environments, where agent dynamics such as team composition changes remain unaddressed. Future research could focus on extending decentralized training methods to maintain scalability, exploring mechanisms for adaptive team structure management, and further enhancing recursive reasoning for longer planning horizons.
Conclusion
The REMALIS framework offers a substantial advance in the field of collaborative multi-agent learning systems. By integrating LLM-driven intention propagation, grounded contextual reasoning, and strategic re-planning, it presents a robust approach to dealing with complex, multi-step tasks. This work underscores the importance of synchronized multi-agent systems for tackling tasks that traditional single-agent models struggle with, revealing pathways for further innovations in distributed AI frameworks.

