- The paper introduces a novel GAN architecture that integrates depth maps and a Depth Aware Loss (DAL) to accurately delineate occlusion boundaries.
- It employs a U-Net generator with a Spatial Transformer and a PatchGAN discriminator, achieving superior compositional realism as measured by SSIM and MAE.
- Experiments on both real-world and synthetic datasets show that using depth information significantly improves rendering of transparency and occlusion compared to traditional 2D approaches.
DepGAN: Leveraging Depth Maps for Handling Occlusions and Transparency in Image Composition
Introduction
"DepGAN: Leveraging Depth Maps for Handling Occlusions and Transparency in Image Composition" explores the application of Generative Adversarial Networks (GANs) to perform image composition tasks using 3D scene data. Image composition is a complex undertaking, requiring attention to occlusions, transparency, lighting, and geometry to produce realistic images. While traditional methods primarily use 2D information, the paper proposes using depth maps alongside alpha channels to enhance compositional realism. A novel loss function, Depth Aware Loss (DAL), is introduced to delineate occlusion boundaries with improved accuracy.
Methodologies
DepGAN Architecture
The architecture of DepGAN utilizes depth maps to improve image composition outcomes. The generator in DepGAN adopts a U-Net style architecture, which is effective in tasks requiring precise spatial manipulation. It performs transformations on foreground images using a Spatial Transformer Network (STN) to align them with background images. The PatchGAN architecture is employed as a discriminator to provide pixel-level assessments, ensuring generated images maintain realistic features.
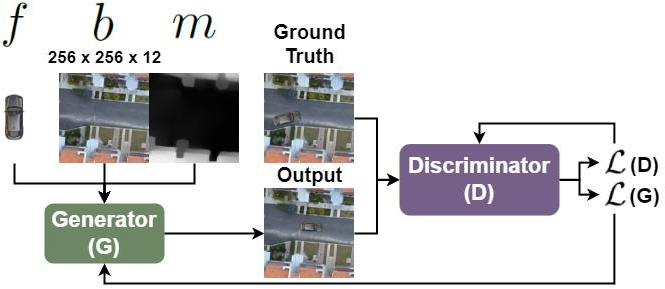
Figure 1: Overall architecture of DepGAN.
Depth Aware Loss
Depth Aware Loss (DAL) quantifies the pixel-wise depth difference, focusing penalty on rendering foreground objects in areas of lighter depth values where occlusion should be present. This facilitates accurate alignment between generated and ground-truth images by maintaining depth consistency across scenes. DAL effectively supports rendering transparency, utilizing alpha channels to refine semi-transparent object compositing.

Figure 2: The depth mask applied distinguishes foreground areas to control occlusion and transparency.
Experiments
Real-World Evaluation
DepGAN was tested on STRAT's face-glasses dataset. It emerged as the superior model in managing occlusion and ensuring realistic transparency effects, outperforming existing GAN-based methods quantitatively, as indicated by metrics like SSIM and MAE.

Figure 3: Evaluation on STRAT's dataset reveals DepGAN's capability to handle transparency and occlusion.
Synthetic Dataset Evaluation
On synthetic datasets derived from Shapenet, DepGAN effectively placed foreground objects within spatial contexts, enhancing semantic placement behavioral accuracy. Figures showcase DepGAN's clear delineation of occlusion boundaries compared to other models' efforts.

Figure 4: DepGAN's results demonstrate precise occlusion handling in complex synthetic scenarios.
The study found a batch size of one yielded optimal image compositions, preserving unique image features with sharper delineation. Various learning rates were explored to mitigate mode collapse, resulting in a generator rate of 0.0002 and a discriminator rate of 0.0001 delivering stable outputs.

Figure 5: Using small batch sizes improves image composition quality.
Ablation Studies
An ablation on DAL showed its crucial role in enhancing depth awareness, with the variant lacking DAL failing in rendering accurate occlusion boundaries. Quantitative metrics consistently favored the inclusion of DAL for improved image accuracy and depth consistency.
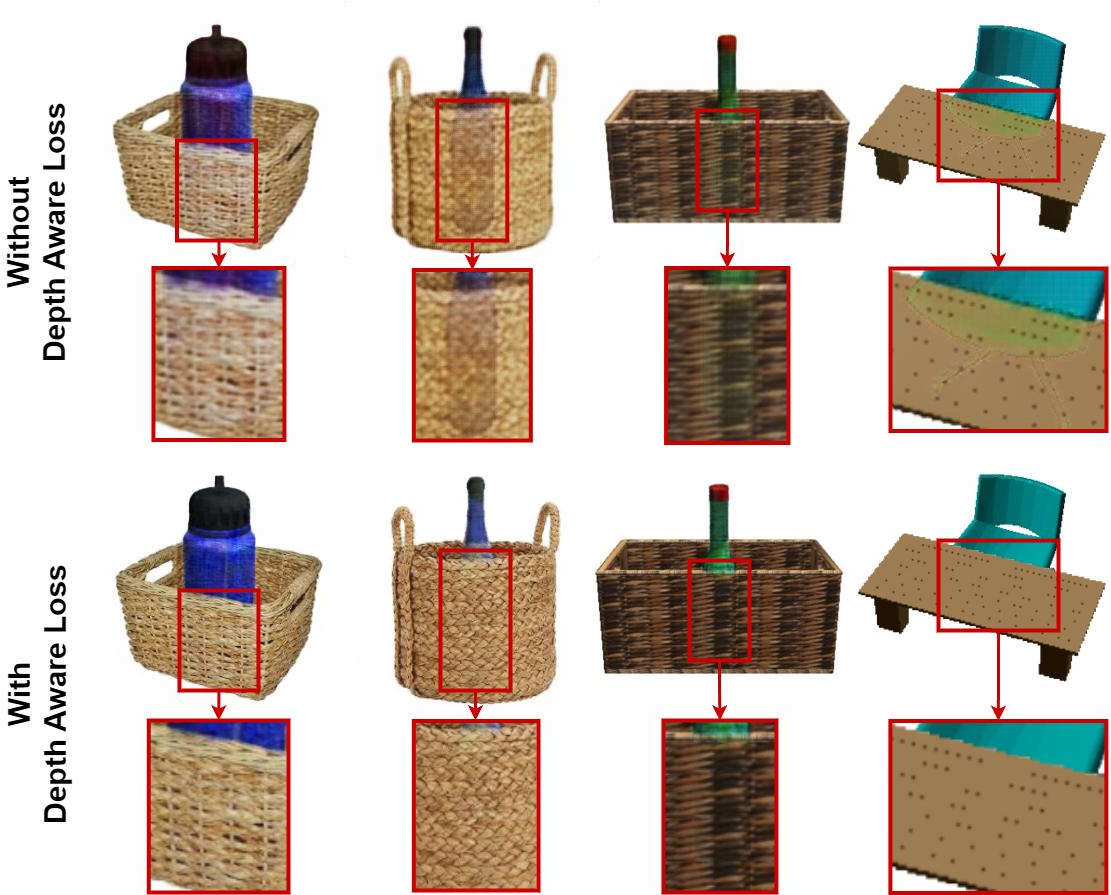
Figure 6: DAL inclusion results in superior occlusion boundary delineation.
Conclusion
DepGAN represents an advancement in leveraging 3D spatial information for image composition tasks, improving handling of occlusions and transparency. By integrating DAL, DepGAN achieves a high standard of realism. Future directions may include refining loss functions and incorporating more sophisticated multi-modal inputs to further enhance compositional outputs.

Figure 7: DepGAN's potential artifacts highlight areas for improvement in texture rendering.

