- The paper introduces a self-supervised audio masked autoencoder integrated with ResUNet and STFT features to achieve robust universal sound separation.
- The methodology leverages concatenated SSL embeddings and FiLM-based latent source embeddings to guide the source separator effectively.
- The approach improves separation performance, achieving a 5.62 dB SDR increase on AudioSet with significant gains in classes like dial tones and smoke detectors.
Universal Sound Separation with Self-Supervised Audio Masked Autoencoder
Introduction
The task of Universal Sound Separation (USS) entails the segregation of arbitrary sound sources from a mixture. Traditional approaches primarily rely on supervised learning with labeled datasets. However, the emerging Self-Supervised Learning (SSL) paradigm, which utilizes unlabeled data to derive task-independent representations, offers compelling advantages for various downstream tasks. This research introduces a novel integration of SSL with USS, employing a pre-trained Audio Masked Autoencoder (A-MAE) to enhance separation capabilities. By leveraging SSL embeddings that are concatenated with short-time Fourier transform (STFT) features, the study evaluates the performance on the AudioSet dataset, demonstrating improvements in separation efficiency over a ResUNet-based baseline.
Methodology
The proposed system is structured around the integration of A-MAE, a self-supervised model designed to learn audio representations from Mel-spectrograms. During USS training, the study explores two strategies: freezing and selectively updating the A-MAE parameters. The objective is to optimize the ResUNet-based USS model by concatenating SSL-derived representations with STFT features.
The framework advocates using a query-based system employing weakly labeled data from AudioSet. This involves three major components: a Sound Event Detection (SED) system for localizing event occurrences, a source separator, and a Latent Source Embedding (LSE) processor. The SED system is instrumental in identifying clean target sound events, facilitating the construction of training mixtures. Meanwhile, LSE embeddings are integrated using Feature-wise Linear Modulation (FiLM) to guide the source separator in discerning specific audio sources.
Results
The experimental setup extensively evaluates the proposed methods on the AudioSet evaluation dataset, considering both oracle and average embedding conditions. Notably, the integration of A-MAE enhances the separation performance, achieving an SDR improvement (SDRi) of 5.62 dB using average embeddings, surpassing the previous state-of-the-art by 0.44 dB.
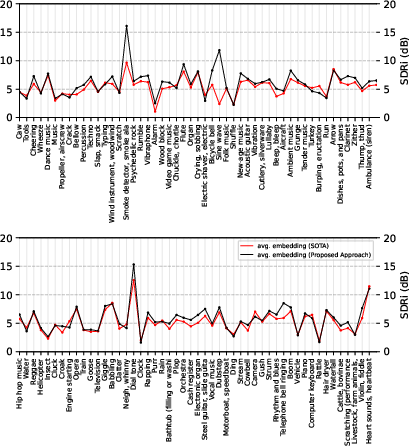
Figure 1: Class-wise USS results on some AudioSet sound classes.
Class-wise analysis reveals substantial improvements in SDRi for distinct sound categories such as dial tones and smoke detectors, which are characterized by line spectrum features. Interestingly, while the proposed method generally enhances performance across most classes, a few exhibit negligible or adverse changes, suggesting avenues for further refinement.
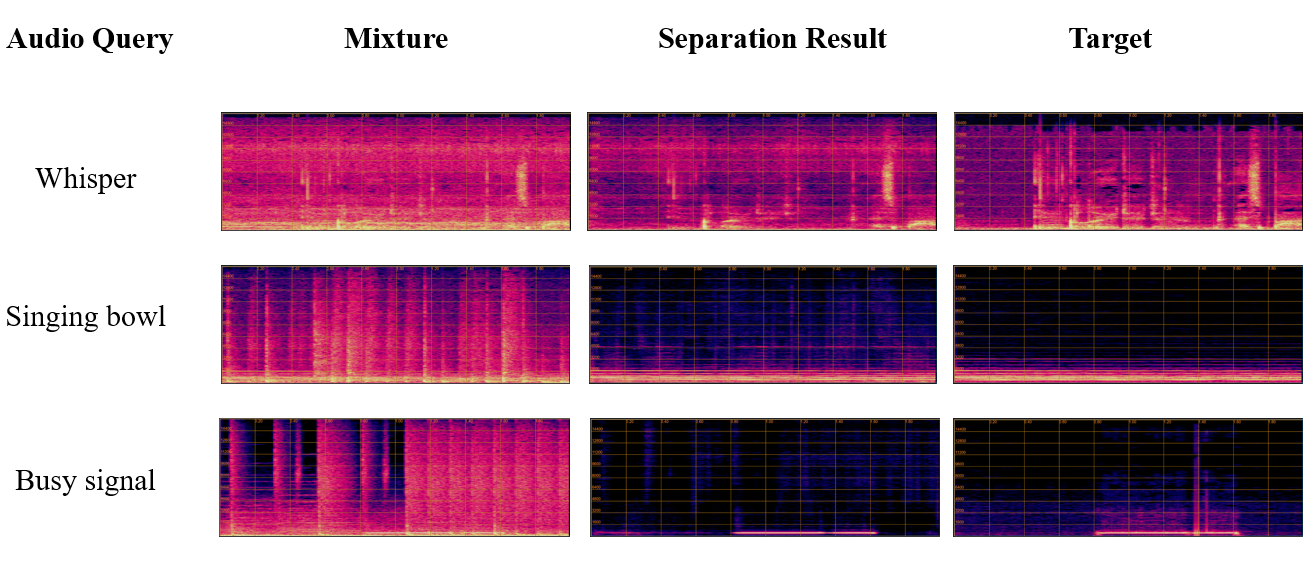
Figure 2: Visualization of separation results obtained by our model.
A visual inspection of separation results demonstrates the efficacy of the proposed method, as the extracted source closely aligns with its ground truth counterpart. The robust A-MAE-based features significantly aid in preserving the fidelity of separated sources.
Conclusion
This research marks a pioneering effort in deploying self-supervised pre-trained audio models like A-MAE for universal sound separation. By enriching the feature space with SSL embeddings, the separation performance across various sound classes in AudioSet is significantly advanced. Future work will focus on enhancing the system's adaptability to unseen sound categories and exploring additional modalities for sound separation enhancement. These directions promise to further optimize USS systems for practical, real-world applications.