- The paper demonstrates that LLM-based imputation significantly improves recommendation accuracy compared to traditional methods.
- It employs a multi-step framework by fine-tuning GPT-2 with LoRA to predict missing values in datasets like AdClick and MovieLens.
- Results show enhanced performance in multi-class tasks, with superior R@K and N@K metrics over conventional imputation techniques.
Data Imputation using LLM to Accelerate Recommendation System
The paper presents a methodology for improving recommendation systems by utilizing LLMs for data imputation, addressing the persistent issue of missing data. This approach is significant given the substantial impact of sparse data on the effectiveness of recommendation systems.
Background on Missing Data and Recommender Systems
Missing data is a well-recognized issue in statistical analyses and machine learning applications, resulting in biased and unreliable models if not appropriately handled. Traditional imputation methods, including mean, median, and kNN imputation, often fail to capture underlying complex relationships. In contrast, LLMs provide a promising alternative due to their capacity to understand semantic contexts and intricate relationships inherent in vast text corpora. This potential is leveraged in the domain of recommender systems, which rely on comprehensive datasets to produce personalized suggestions.
Proposed Framework
The authors propose a multi-step process to integrate LLM-based data imputation within recommendation systems. The framework, thoroughly depicted in Figure 1, initiates with the fine-tuning of an LLM on datasets with complete entries to learn domain-specific patterns. The meticulously fine-tuned LLM subsequently imputes missing values by predicting these values through a constructed prompt encompassing relevant attributes and missing data points. This process allows for filling voids in data with values that are semantically and statistically coherent.
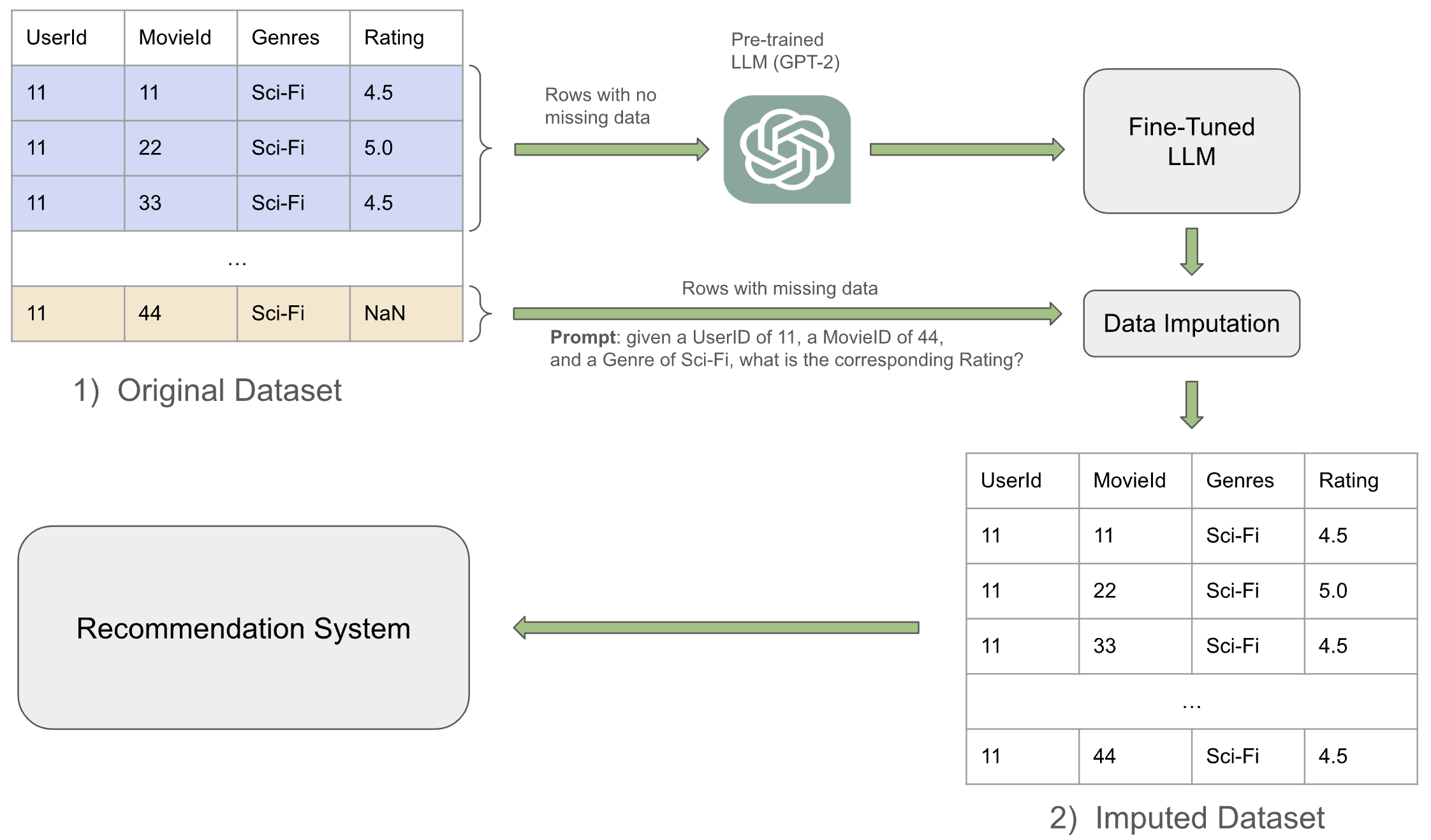
Figure 1: Framework of our proposed method. Original dataset contains missing data. Using complete data to fine-tune LLM which can be further utilized to impute the missing data. After that, complete tabular data are used to feed into Recommender System.
Implementation and Evaluation
For practical implementation, the distilled version of GPT-2 was utilized given its proven effectiveness and accessibility. The LLM was fine-tuned using Low-Rank Adaptation (LoRA) strategies to accommodate task-specific nuances without computational expense associated with large-scale parameter tuning. This allows efficient model adaptation by focusing on low-rank updates to pre-trained weights, yielding a model tailored for imputation tasks.
The authors conducted extensive experiments across multiple datasets including AdClick and MovieLens, simulating various recommendation tasks—such as single classification, multi-class classification, and regression. Various performance metrics were employed to validate the efficacy of LLM-based imputation against traditional approaches. Results demonstrated notable improvements, particularly in multi-class classification tasks, where LLM imputation outshone other methods on metrics such as Recall at K (R@K) and Normalized Discounted Cumulative Gain (N@K).
Results and Discussion
In multiple classification tasks, the LLM imputation demonstrated a significant advantage over statistical methods with metrics indicating improved recommendation accuracy (Table shows superiority with metrics such as R@10 reaching 0.653 for LLM versus 0.642 for kNN). The ability of LLMs to generate and incorporate nuanced data imputation offers a robust tool for enhancing recommendation systems' functionality. By filling data gaps more accurately, these systems can provide more meaningful, accurate user recommendations.
Conclusion
The integration of LLM-based data imputation into recommendation systems marks a promising advancement in addressing the challenge of data sparsity. The methodological application not only highlights the potential of LLMs in data understanding and generation tasks but also underscores their applicability in enhancing machine learning systems' performance. This research paves the way for future exploration of LLM applications in other data-intensive domains, promoting resilience and sophistication in data-driven decision processes.
Overall, the proposed framework provides a scalable solution that fits seamlessly into existing recommendation architectures, bolstering their efficacy in the face of incomplete data and offering valuable prospects for further academic and industrial adoption.