- The paper introduces SPIQA, a novel dataset with 270K questions from 26K scientific papers, addressing the limitations of earlier QA datasets.
- It employs three distinct tasks—direct QA with figures and tables, full paper QA, and CoT QA—to enhance model comprehension and reasoning.
- A new LLMLogScore metric is proposed to evaluate free-form answers, demonstrating promising improvements over traditional evaluation methods.
SPIQA: A Dataset for Multimodal Question Answering on Scientific Papers
The paper introduces SPIQA (Scientific Paper Image Question Answering), a novel large-scale QA dataset designed to evaluate MLLMs' ability to interpret figures and tables within scientific research articles. The dataset addresses the limitations of existing QA datasets, which often focus solely on textual content or are limited in scale. SPIQA comprises 270K questions generated from 26K papers across various computer science domains. The dataset is designed to assess the long-context capabilities of MLLMs through three distinct tasks: direct QA with figures and tables, direct QA with the full paper, and a CoT QA approach.
Dataset Construction and Tasks
The SPIQA dataset was constructed using a combination of automatic and manual curation techniques. The process involved collecting PDFs and TeX sources from 19 top-tier computer science conferences published between 2018 and 2023 (Figure 1). Gemini 1.5 Pro was used to automatically generate question-answer pairs, which were then manually filtered to ensure quality and relevance. The collection guidelines emphasized the need for questions that require a robust understanding of figures, tables, and their captions.
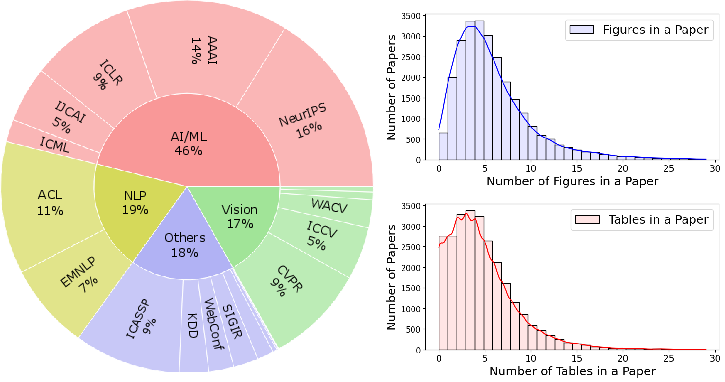
Figure 1: Source of the collected papers and distribution of figures and tables per paper, highlighting the breadth of computer science domains covered.
The three tasks defined for SPIQA are:
- Direct QA with Figures and Tables: Models are presented with all figures and tables from a paper and must answer questions based on them.
- Direct QA with Full Paper: Models are given the entire paper, including text, figures, and tables, and must answer questions.
- CoT QA: Models must first identify the most relevant figures and tables and then answer the question, allowing for a fine-grained evaluation of reasoning and grounding capabilities (Figure 2).

Figure 2: Illustration of the SPIQA tasks, showcasing the integration of information across figures, tables, and paper text for question answering.
LLMLogScore (L3Score): A Novel Evaluation Metric
The paper introduces LLMLogScore (L3Score), a new LLM-based evaluation metric for free-form QA. L3Score leverages the log-likelihood probabilities generated by an LLM to assess the semantic equivalence of answers with the ground truths. This approach addresses the limitations of traditional metrics such as BLEU and ROUGE, which often fail to capture the nuances of descriptive answers generated by LLMs. The L3Score is calculated as:
L3Score=softmax(x)yes=exp(lyes)+exp(lno)exp(lyes)
where lyes and lno are the log probabilities for the tokens 'yes' and 'no', respectively. The metric effectively renormalizes the probabilities to sum to 1, providing a confidence-based assessment of answer equivalence.
Experimental Evaluation and Results
Extensive experiments were conducted using 12 foundational models, including closed-source models such as Gemini, GPT-4, and Claude-3, as well as open-source models like LLaVA 1.5, InstructBLIP, and CogVLM. The models were evaluated across the three SPIQA tasks using metrics such as METEOR, ROUGE-L, CIDEr, BERTScore F1, and L3Score. Fine-tuning InstructBLIP and LLaVA 1.5 on the SPIQA training set resulted in significant performance improvements compared to zero-shot evaluation. The experiments highlighted the importance of captions for figure and table comprehension (Figure 3).
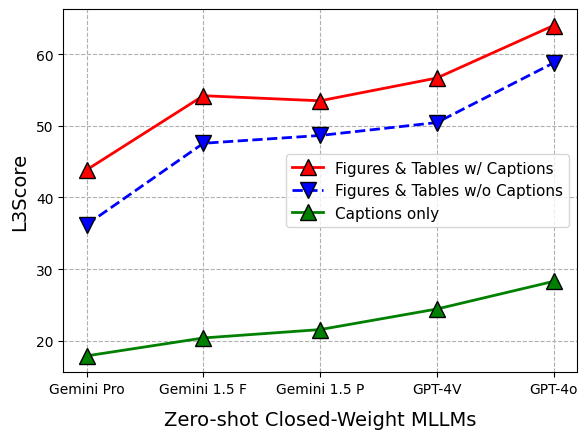
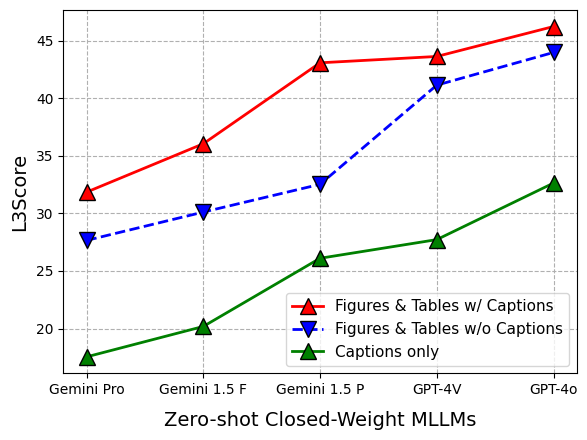
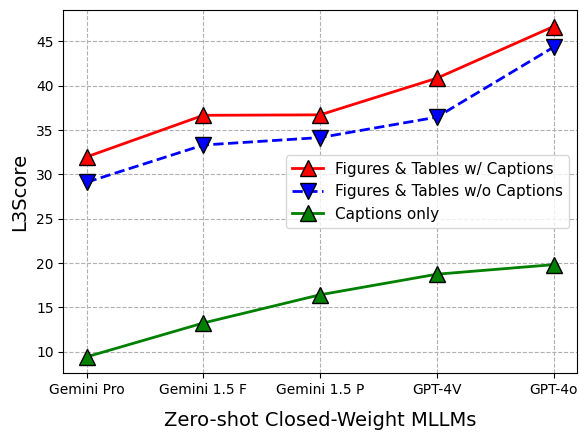
Figure 3: Results on test-A, demonstrating the performance of various models in answering questions directly from figures and tables.
GPT-4o achieved state-of-the-art results on test-A and test-C, while Claude-3 performed well on test-B. The use of full paper text and CoT strategies generally improved model performance. The effectiveness of L3Score was demonstrated through its ability to accurately evaluate free-form answers, outperforming other LLM-based scores.
Implications and Future Directions
The SPIQA dataset and the L3Score metric provide valuable resources for advancing research in multimodal QA and long-context understanding. The dataset's focus on scientific papers and complex figures and tables presents a unique challenge for MLLMs, driving the development of more sophisticated reasoning and grounding capabilities. The introduction of L3Score offers an improved method for evaluating free-form QA, addressing the limitations of traditional metrics. Future research directions include expanding SPIQA to other scientific domains, exploring different CoT strategies, and developing specialized systems for scientific QA.
Conclusion
The paper presents SPIQA, a novel dataset for multimodal question answering on scientific papers, along with the L3Score metric for evaluating free-form answers. The extensive experiments and analyses provide insights into the capabilities of current MLLMs and highlight areas for future research. The SPIQA dataset is expected to contribute to the development of more advanced QA systems that can effectively understand and analyze scientific documents.