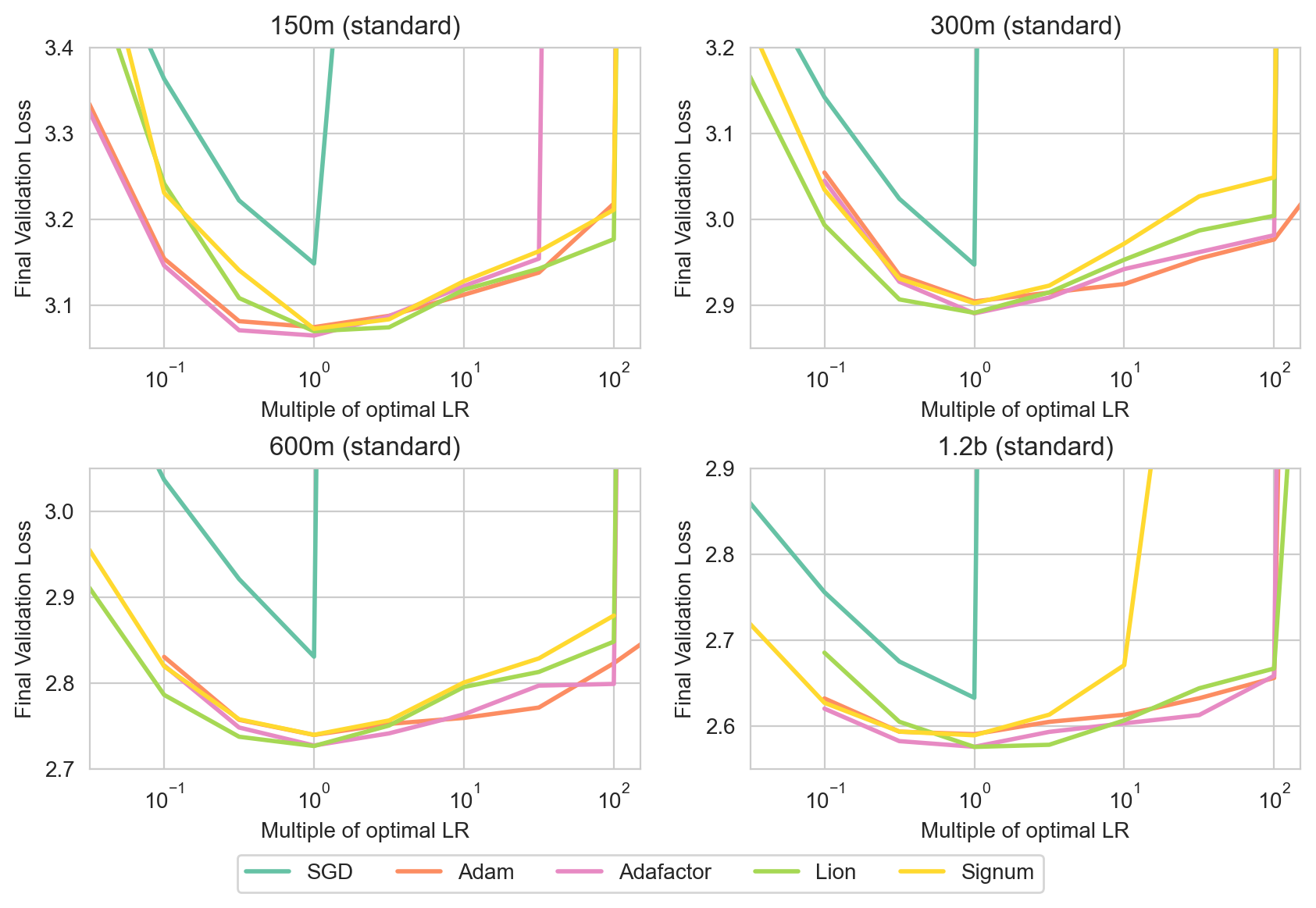
- The paper demonstrates that, except for SGD, optimizers such as Adam, Adafactor, Lion, and Signum achieve comparable performance through extensive hyperparameter sweeps.
- It employs large-scale experiments with varied model sizes and setups, emphasizing the critical role of momentum tuning and layer-wise adaptations.
- Hybrid methods combining SGD with adaptive techniques for specific layers show potential for maintaining stability while optimizing memory and performance.
Deconstructing What Makes a Good Optimizer for LLMs
The paper "Deconstructing What Makes a Good Optimizer for LLMs" (2407.07972) examines the effectiveness of various optimization algorithms for training autoregressive LLMs across different model sizes, hyperparameters, and architectural variations. The primary objective is to identify key factors contributing to an optimizer's performance and stability and to evaluate whether widely-used algorithms like Adam retain their superiority in different contexts.
Introduction
The study undertakes a large-scale comparison involving several optimization algorithms, namely SGD, Adam, Adafactor, Lion, and Signum, by measuring their performance in training LLMs with varied sizes. Adam has been historically favored due to its perceived superior optimization efficiency and scalability. However, the authors challenge this dominance by arguing that newer algorithms might offer comparable performance when evaluated across varying hyperparameter configurations.
Comparing Optimizers Across Hyperparameters
Methodology and Setup
A thorough methodological approach was adopted, including hyperparameter sweeps for learning rates, momentum (β1), and other critical parameters. LLMs were trained on the C4 dataset using T5 tokenization to ensure performance evaluations were consistent across different experimental setups.
The findings expose that, aside from the underperformance of SGD, the remaining optimizers achieved similar validation losses and showed congruent behavior across varying hyperparameter landscapes.
Exploration of Optimizer Dynamics
Signum, a derivative of the Lion optimizer, was investigated to understand its close resemblance to Adam. The study revealed that Signum performs similarly to Adam when β1 is tied to β2. The implication is that the separability of these momentum parameters in Adam likely provides marginal gains in adaptability and performance.
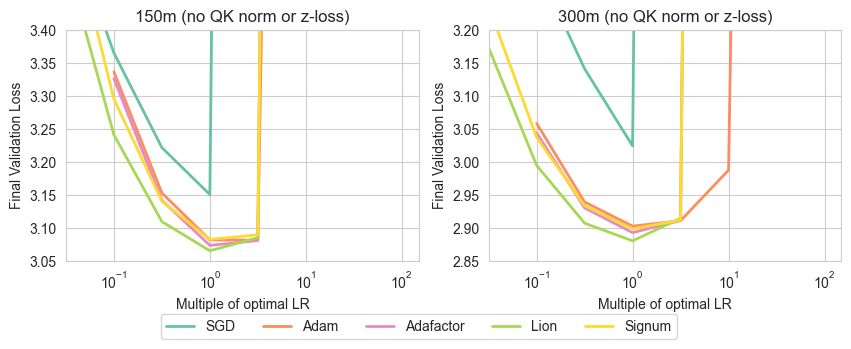
Figure 2: Sweeping learning rate without QK norm or z-loss showcasing stability across algorithms barring SGD.
Layerwise Adaptive Dynamics with Adalayer
The introduction of Adalayer, a layer-wise version of Adam, illuminated the significance of the last layer and LayerNorm parameters in driving model performance. It posits that most of the network can be efficiently trained with SGD, except for the adaptation necessary in the final layers.
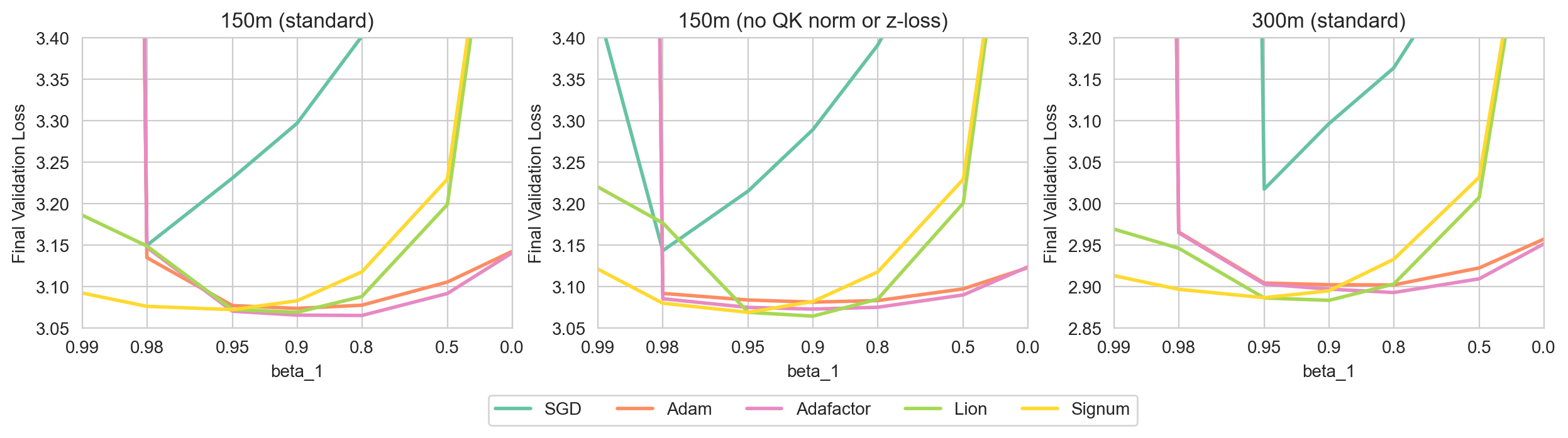
Figure 3: Sweeping momentum across optimizers showing sensitivity disparities and the robustness of Lion and Signum compared to SGD.
Hybrid Optimizers and Insights
Experimentations with hybrid approaches—combining SGD with per-layer adaptations using Adalayer* or Adafactor for the last layer and LayerNorm parameters—demonstrated that robust performance can be achieved without full adaptivity. This hybrid approach effectively meets stability and performance benchmarks typically dominated by Adam.
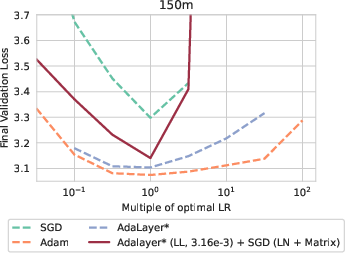
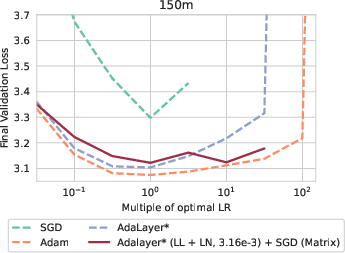
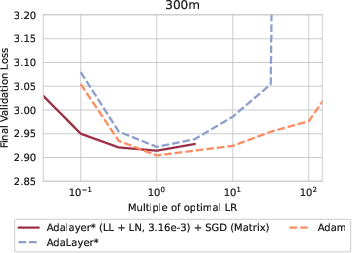
Figure 4: Adaptive dynamics comparing Adalayer and SGD hybrids, substantiating performance recovery with last-layer adaptivity.
Conclusion
This paper provides critical insights into the factors underlying optimizer effectiveness by systematically deconstructing and experimenting with various methods. By challenging the preeminence of Adam and highlighting the potential of hybrid adaptive techniques, it broadens the scope for optimizer selection based on practical considerations such as memory use and ease of implementation rather than presumed performance superiority.
Overall, this research advances the understanding of optimization strategies in LLM training, suggesting future investigations could explore further architectural configurations and hyperparameter interactions beyond one-dimensional sweeps. The empirical findings and methodologies lay groundwork for more nuanced guidelines in optimizer selection and implementation in large-scale language modeling tasks.