- The paper introduces a unified interleaved data format that allows models to handle multi-image, video, and 3D scenarios collectively.
- It leverages the comprehensive M4-Instruct dataset with 1,177.6k samples and continued training strategies to enhance performance.
- Experimental results demonstrate state-of-the-art efficiency on multi-image benchmarks along with emerging cross-domain transfer capabilities.
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Introduction
The paper "LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models" proposes a novel approach to unify various visual modalities within Large Multimodal Models (LMMs) using an interleaved data format. The existing LMMs have primarily been focused on single-image tasks, with less exploration into multi-image and other complex visual scenarios. This work introduces LLaVA-NeXT-Interleave, a model designed to process Multi-image, Multi-frame (video), Multi-view (3D), and Multi-patch (single-image) scenarios collectively in LMMs.
A significant contribution of this work is the adoption of an interleaved data format as a universal template. By considering images, video frames, and 3D views as part of an interleaved sequence, this approach creates a cohesive framework for training. This facilitates the model's ability to handle diverse data types seamlessly. It further simplifies the training process across various domains by allowing the emergence of new capabilities through cross-domain task composition.

Figure 1: Tasks in the M4-Instruct dataset including multiple images, video frames, and 3D views, organized in an interleaved format for unified processing.
M4-Instruct Dataset
To harness the potential of the unified format, the authors compiled the M4-Instruct dataset comprising 1,177.6k samples across four primary domains and 14 tasks derived from 41 datasets. This comprehensive dataset supports multi-image, video, 3D, and single-image scenarios, enabling the LMMs to evolve with diverse tasks and requirements.
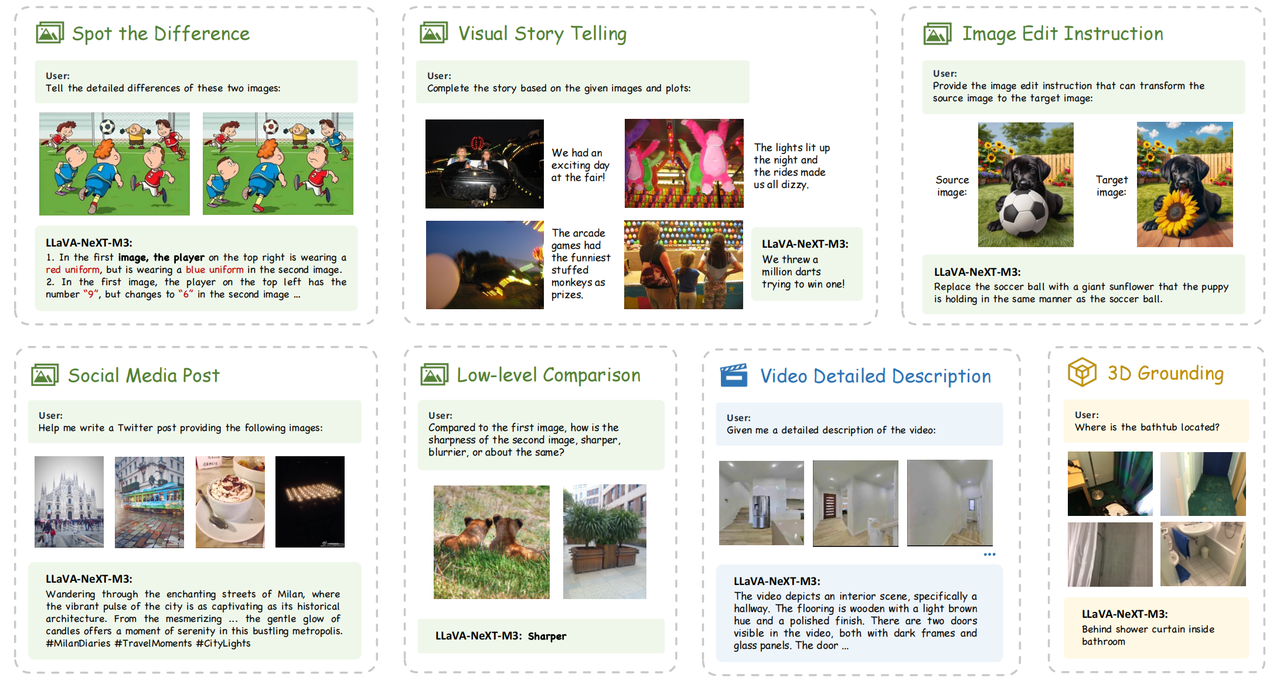
Figure 2: Task examples in M4-Instruct showcasing scenarios from multi-image, multi-frame, and multi-view domains.
LLaVA-Interleave Bench
To evaluate the performance of LLaVA-NeXT-Interleave, the LLaVA-Interleave Bench was established. It is a benchmark designed to assess the model's capabilities in addressing multiple image scenarios. The benchmark includes a wide range of tasks both within and outside the training domain, providing a rigorous platform for performance validation.
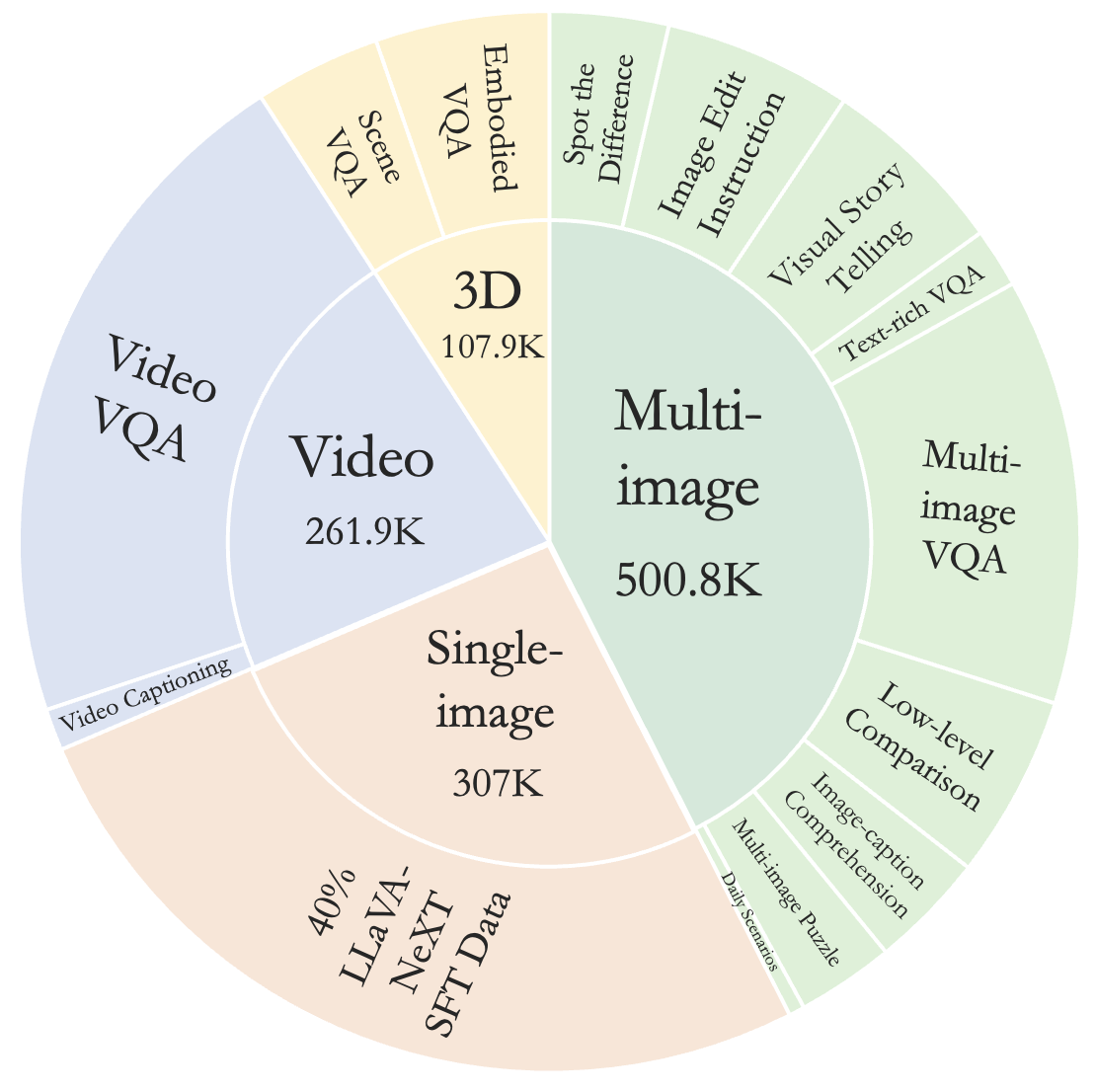
Figure 3: M4-Instruct training data statistics illustrating the distribution of samples across various scenarios.
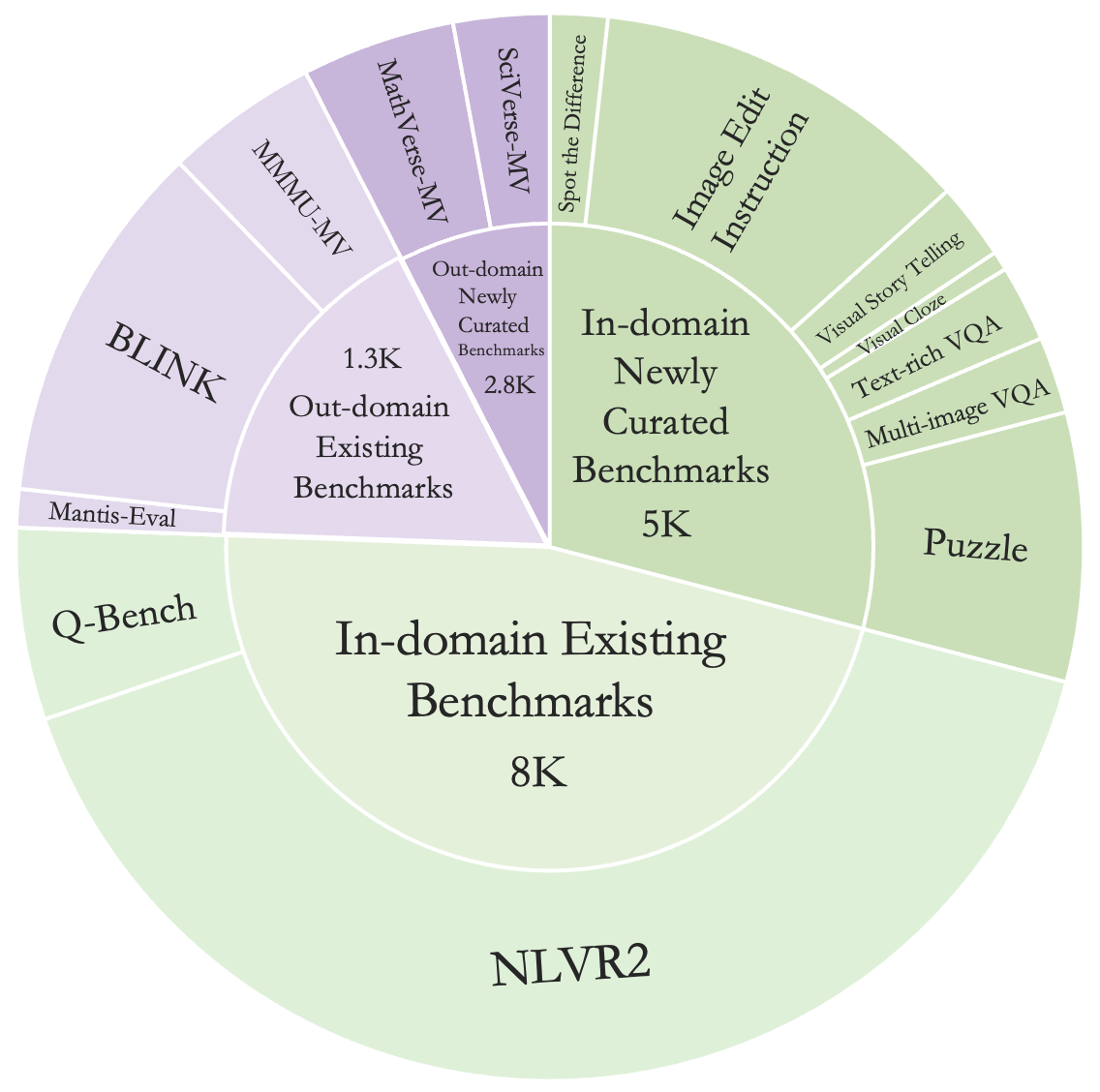
Figure 4: LLaVA-Interleave Bench statistics highlighting the evaluation metrics and tasks incorporated.
Training and Implementation Strategies
The implementation of LLaVA-NeXT-Interleave involves several techniques to enhance performance across various visual domains:
- Continued Training from Single-image Models: By building upon pre-trained single-image models, the approach leverages existing capabilities, transitioning smoothly into more complex multi-image tasks.
- Mixed Interleaved Data Formats: During training, using various interleaved and non-interleaved data formats adds flexibility and robustness to the model during inference.
- Combining Data Scenarios: Training on a mix of single-image, multi-image, and video tasks provides complementary insights, boosting individual task performance.
Experimental Results
The experimental results demonstrate the efficacy of the LLaVA-NeXT-Interleave model. It achieves state-of-the-art performance in several multi-image benchmarks and maintains high efficiency in single-image tasks. Additionally, the model exhibits emerging capabilities, such as task transfer across different modalities and scenarios.
Conclusion
LLaVA-NeXT-Interleave marks a significant step towards unifying heterogeneous visual data within large multimodal models, expanding their versatility and applicability in real-world scenarios. The methodologies and datasets introduced could pave the way for more integrated and capable AI systems that accommodate diverse visual information seamlessly. Future developments may explore deeper integration of these concepts, unlocking further potentials in AI-driven visual understanding and interaction.

