- The paper demonstrates a novel technique that employs attention maps and lookback ratios to detect contextual hallucinations in LLMs.
- It applies a linear classifier on concatenated attention features to predict factual inaccuracies and guide decoding during tasks like summarization and QA.
- Results show a significant reduction in hallucinations and robust cross-model transferability, enhancing factual integrity in generated outputs.
Lookback Lens: Detecting and Mitigating Contextual Hallucinations in LLMs Using Only Attention Maps
Introduction
The paper "Lookback Lens: Detecting and Mitigating Contextual Hallucinations in LLMs Using Only Attention Maps" addresses the significant challenge of contextual hallucinations in LLMs. Such hallucinations occur when models meet factual information within the input but fail to generate contextually accurate outputs. The proposed Lookback Lens technique leverages attention maps to detect and mitigate these hallucinations.
LLMs often produce unsubstantiated details that deviate from the input context, leading to errors in tasks like summarization and document-based question answering. The Lookback Lens approach hypothesizes that contextual hallucinations are related to the attention patterns focusing between contextual tokens and generated tokens. This methodology involves calculating lookback ratios from attention weights and applying a linear classifier to predict the truthfulness of generated text.
Detecting Contextual Hallucinations
Lookback Lens Overview
The Lookback Lens computes features called lookback ratios, which quantify the attention distribution between context tokens and newly generated tokens. These ratios facilitate the detection of hallucinations without relying on complex hidden states or entailment models. The critical detail is leveraging attention maps, a meaningful and parsimonious signal to detect inconsistencies effectively.
For each attention head, the lookback ratio is calculated as the ratio of context-focused attention weights to the total attention weights (context-focused plus generation-focused). These ratios are concatenated into a feature vector used by a linear classifier to detect hallucinations.
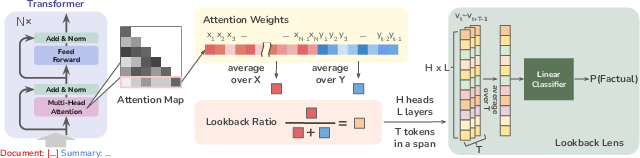
Figure 1: An illustration of the Lookback Lens. We extract attention weights and calculate the lookback ratios for all layers and all heads. We train a linear classifier on the concatenated features to predict truthfulness of the generation.
Experimental Setup
The paper utilized datasets like CNN/DM and Natural Questions (NQ) to evaluate the Lookback Lens's performance. The attention map features from the LLaMA-2-7B-Chat model served as inputs for training the classifier, which was tested across tasks and models.
Two settings were explored: predefined spans (using human and GPT-4o annotations) and sliding windows to handle unseen distribution shifts during evaluation. The results demonstrated that the Lookback Lens rivaled hidden states-based classifiers and significantly outperformed NLI models.
Mitigating Contextual Hallucinations
Guided Decoding Strategy
The Lookback Lens was employed in a novel decoding strategy. The classifier guides text generation to enhance the factual integrity of outputs without compromising overall quality. The method influenced text generation by evaluating multiple token sequences at each step, powered by attention map-anchored insights.

Figure 2: Lookback Lens Guided Decoding: sample multiple chunk candidates, compute lookback ratios from attention maps to be scored by Lookback Lens, and select the best candidate that is less likely to be hallucinations.
Application Across Tasks
The Lookback Lens Guided Decoding framework was evaluated on summarization (XSum), QA (NQ), and multi-turn conversation tasks (MT-bench). Across all tasks, the technique demonstrated substantial improvements in reducing hallucinations, notably achieving a 9.6% reduction in XSum and significant improvements in NQ and MT-bench evaluations.
Cross-Model Transferability
The Lookback Lens's reliance on attention maps obviates model-specific tuning, enabling cross-model application. Transfer experiments showed promising results when transitioning from LLaMA-2-7B-Chat to LLaMA-2-13B-Chat without fitting a new classifier, emphasizing the robustness and versatility of the approach.
Discussions and Ablations
The paper conducted various ablations to study the sensitivity of the Lookback Lens to chunk sizes and revealed that the predictive power was distributed across attention heads. Utilizing top-k heads showed that predictive power was not concentrated but rather consistently spread across several heads, highlighting the balanced impact of positive and negative correlations.

Figure 3: Qualitative example on XSum using the LLaMA-2-7B-Chat model with greedy decoding and Lookback Lens Guided Decoding. The numbers in the parenthesis show the predicted scores from the Lookback Lens.

Figure 4: Screenshot of human annotation interface.
Conclusion
The Lookback Lens represents an effective methodology for detecting and mitigating contextual hallucinations in LLMs by leveraging the inherent interpretability of attention maps. The approach demonstrates substantial improvements in factuality across different tasks and models. Its success could herald new directions in integrating human interpretable model mechanisms into large-scale deployable systems.
Figure 5: Top-10 positive/negative heads ranked from top to the bottom by the magnitude of their coefficients in the Lookback Lens classifier.