- The paper presents a comprehensive survey categorizing MoE advancements in algorithmic design, system architecture, and applications in large language models.
- The paper details innovative gating functions, including sparse and soft methods, that optimize expert activation for improved computational efficiency and training stability.
- The paper discusses system-level challenges such as load balancing and memory efficiency, offering insights into scalable distributed MoE model designs.
A Survey on Mixture of Experts in LLMs
The paper "A Survey on Mixture of Experts in LLMs" (2407.06204) provides a comprehensive examination of Mixture of Experts (MoE) within the field of LLMs. MoE, a paradigm for increasing model capacity while maintaining computational efficiency, has become integral to both academia and industry. The survey categorizes MoE advancements into algorithmic design, system design, and applications, serving as a valuable resource for researchers.
Mixture of Experts Architecture
Mixture of Experts utilizes a gating mechanism to control the activation of specific expert modules for each input. The experts are typically specialized sub-networks within a larger architecture. This approach allows for conditional computation, wherein only the relevant experts are engaged, thereby conserving computational power.
State of Art MoE Models
Several MoE models have been developed over recent years. These vary in design, size, and domain of application, including Natural Language Processing, Computer Vision, and multimodality. Notable models such as Mixtral-8x7B and DeepSeekMoE emphasize the efficiency and scalability of MoE architectures (Figure 1).
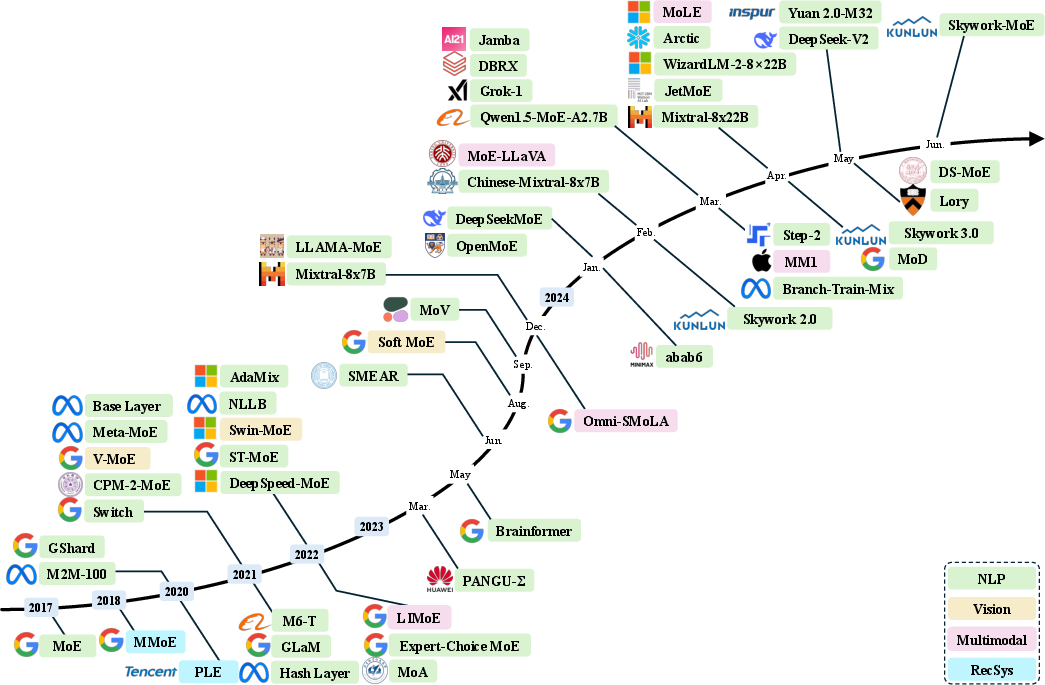
Figure 1: A chronological overview of several representative mixture-of-experts (MoE) models in recent years.
Gating Functions in MoE
MoE models incorporate gating functions to facilitate the expert selection process. These functions determine which experts should be activated for a given input based on learned criteria. Sparse gating strategies typically activate a subset of experts, whereas dense strategies engage all experts. Recent advancements have introduced soft gating functions, which smooth the transition between expert activations and improve training stability (Figure 2).
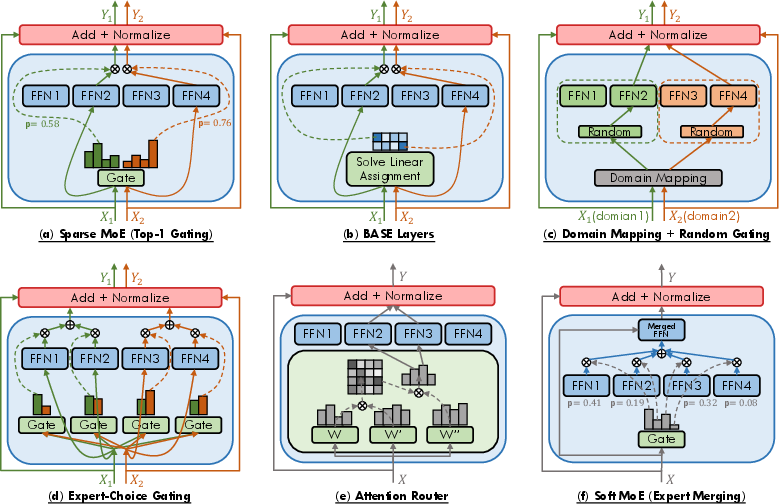
Figure 2: The illustration of various gating functions employed in MoE models, including (a) sparse MoE with top-1 gating.
System Design of MoE Models
The report explores system design challenges intrinsic to MoE models, such as load balancing, communication overhead, and memory efficiency in distributed systems. A variety of strategies, including expert parallelism, are employed to optimize these aspects, improving scalability and overall system performance (Figure 3).
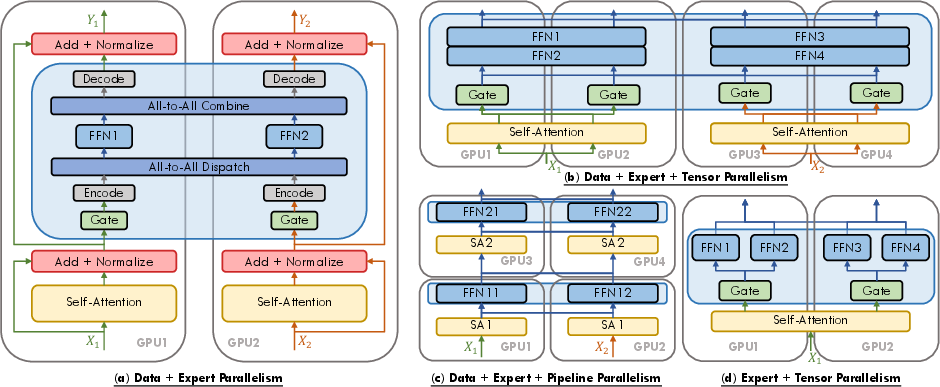
Figure 3: Schematic depiction of diverse parallel strategies for MoE.
Training and Inference Schemes
Emergent training techniques leverage a transition from dense to sparse models and vice versa, or merge multiple expert models into a unified MoE framework. These approaches aim to balance computational efficiency with model capability, offering flexibility in adapting to evolving demands (Figure 4).
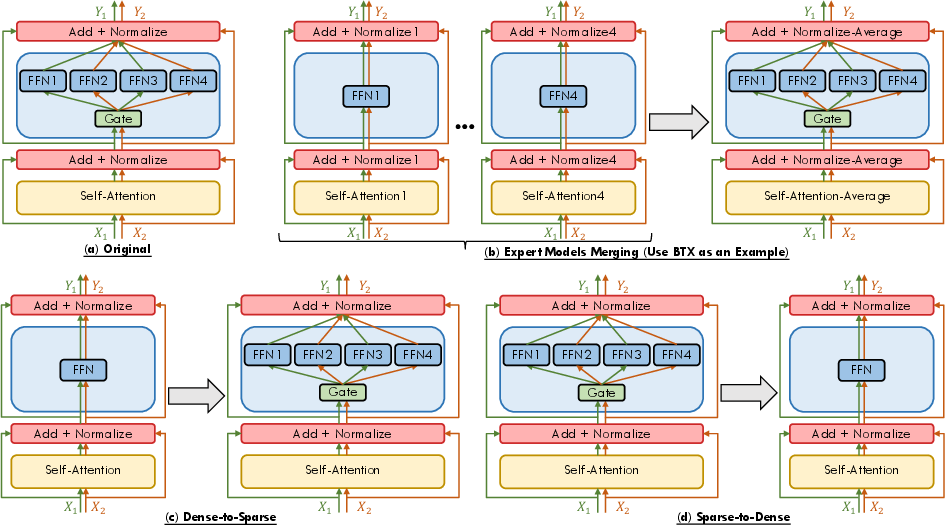
Figure 4: Schematic representation of training and inference schemes related to MoE.
Applications in LLMs
MoE models are exponents of computational efficiency and specialization, enhancing performance across domains such as NLP, vision, and multimodal models. Specific applications include machine translation, multimodal learning, and recommender systems, showcasing MoE’s versatility and potential in AI.
Challenges {content} Opportunities
The paper identifies several ongoing challenges in MoE research, including training stability, efficient expert specialization, communication overhead, and transparency in decision-making. Addressing these challenges will be pivotal in advancing MoE technologies, particularly in enhancing the adaptability and robustness of MoE models across diverse applications.
Conclusion
The Mixture of Experts framework offers a promising approach for scaling LLMs efficiently. This survey serves as an essential reference for researchers in the field, providing insights into the theoretical foundations and practical implementations of MoE models. Future work should focus on overcoming current challenges to fully leverage their potential within AI systems.

