- The paper presents PEER, a novel MOE architecture featuring over a million tiny experts to optimize transformer efficiency.
- The model utilizes product key routing and query networks to achieve sparse retrieval and reduce computational cost.
- Extensive experiments demonstrate that PEER improves language model performance while lowering resource demands.
Mixture of A Million Experts
The paper "Mixture of A Million Experts" addresses the computational challenges associated with scaling transformer models efficiently. It introduces PEER (Parameter Efficient Expert Retrieval), an MOE (Mixture-of-Experts) architecture designed to manage a vast pool of tiny experts, surpassing one million in number. This innovative approach promises to optimize the balance between computational cost and model performance effectively.
Introduction
Transformers are crucial in AI research due to their ability to capture complex patterns and dependencies in data. The scale, in terms of parameters, data, or computational budget, often correlates with performance improvements. However, feedforward (FFW) layers, comprising a significant parameter count, inherently tie computational cost to the model size, leading to inefficiencies.
Sparse MOE frameworks provide a mechanism to decouple computational demands from parameter counts through sparsely activated modules instead of dense FFWs. While MOE methods enhance performance and efficiency, they traditionally plateau beyond certain sizes. This limitation prompted the exploration of PEER, leveraging product key retrieval to efficiently select from over a million experts, maintaining a competitive edge on computational efficiency and model output.
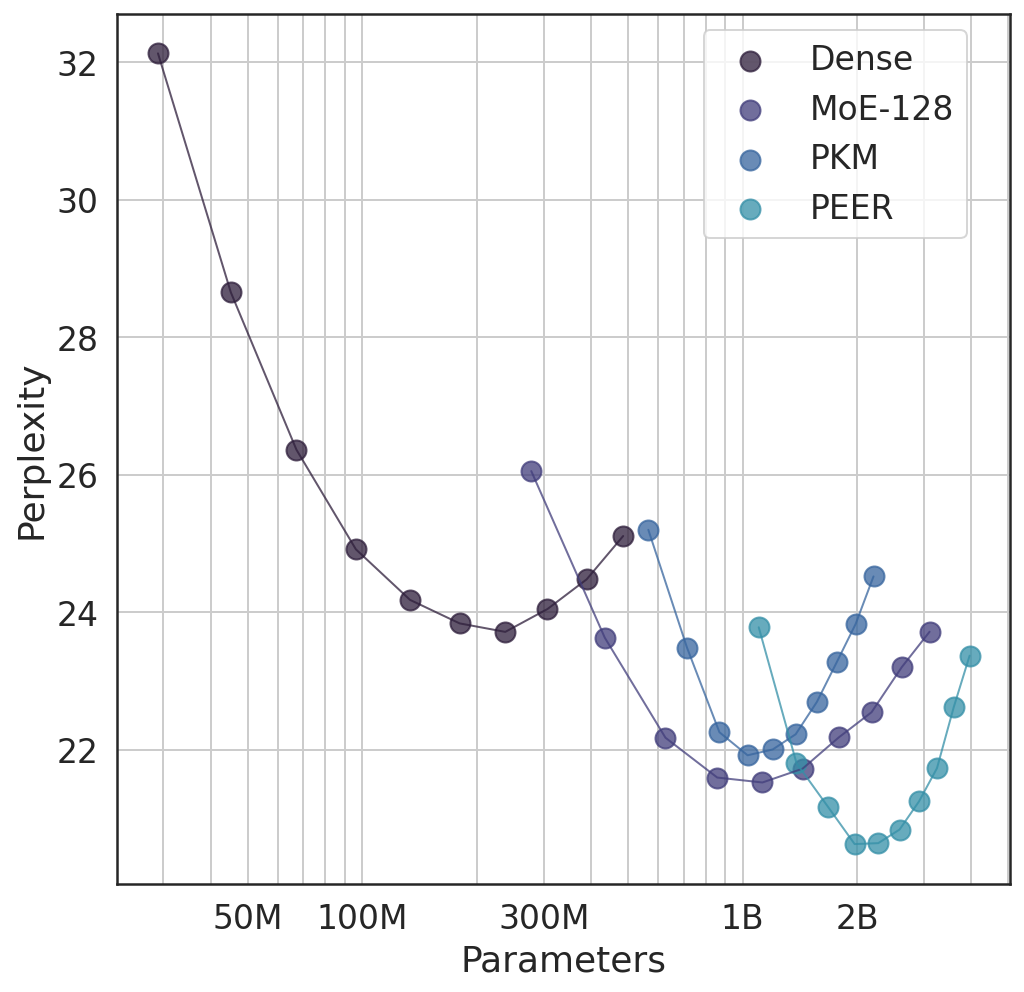
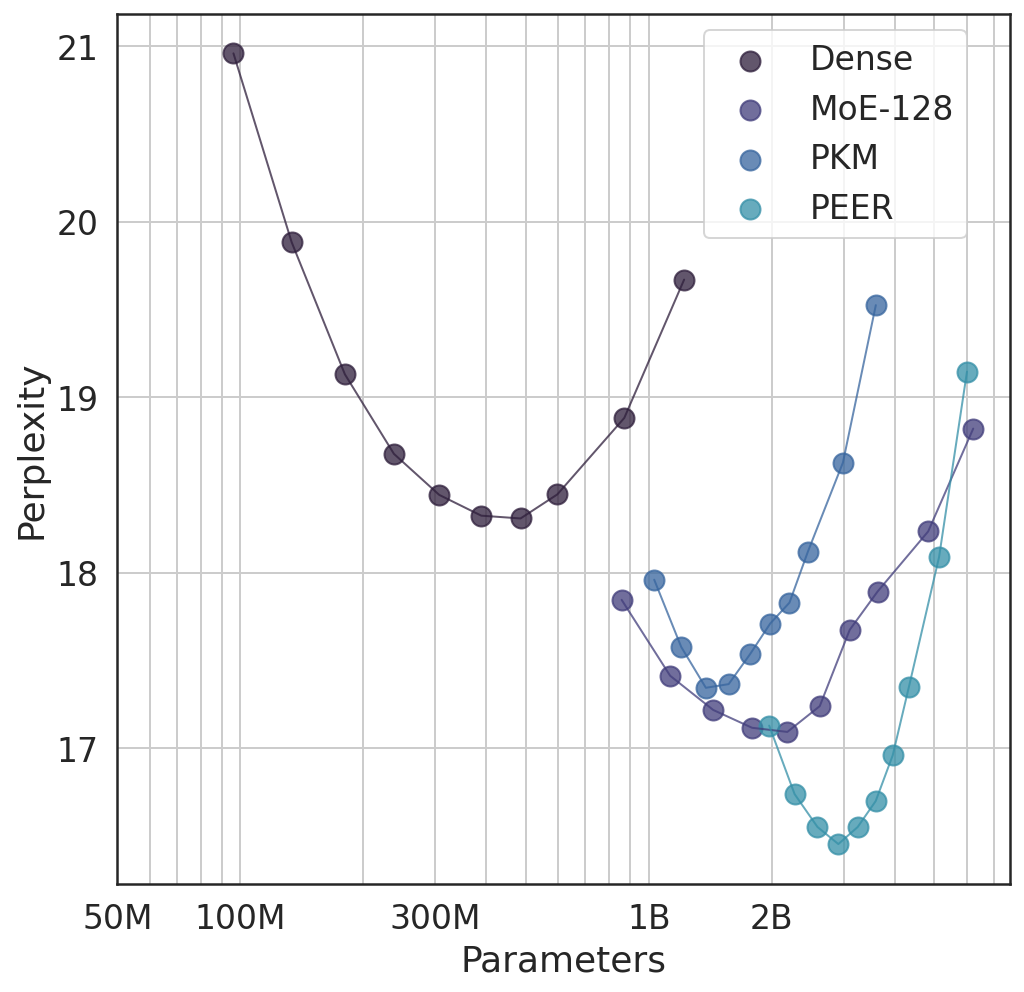
Figure 1: Isoflop comparison on the C4 dataset between PEER and other baselines with two different FLOP budgets (6e18 and 2e19 FLOPs). The x axis is in log scale.
Methodology
PEER operates by inserting a novel layer into the transformer structure or substituting FFW layers completely with the PEER layer. It comprises three core components:
- Expert Pool: A collection of N single-neuron MLPs serving as experts.
- Product Keys: The routing uses product keys for sparse retrieval, structured to ensure efficient expert selection from a large pool.
- Router Logic: A query network formulates input-based queries, determining top-k keys, guiding expert selection.
The model reduces retrieval complexity via product keys, splitting query vectors and employing sub-linear retrieval operations for expert activation (Figure 2).
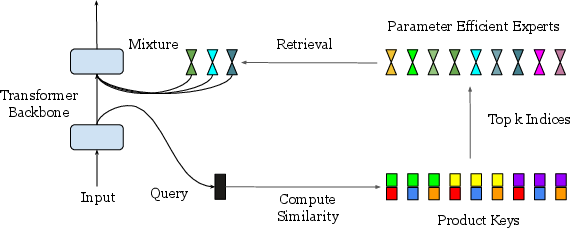
Figure 2: Illustration of the PEER layer. A PEER layer can be inserted in the middle of a transformer backbone or can be used to replace FFW layers. Given the state vector x from the previous layer, a query network q maps it to a query vector q(x), which is then compared with the product keys to compute the router scores and to retrieve the top k experts e1,…,ek. After the retrieved experts make their predictions ei(x), their outputs are linearly combined using the softmax-normalized router scores as weights.
Experiments and Results
Through isoFLOP analysis, the PEER model's efficiency was compared against dense and traditional sparse alternatives, highlighting lower perplexity scores across varied compute budgets. PEER's compute-optimal characteristics emerged across diverse language modeling tasks, outperforming baseline models significantly.
Evaluation details revealed PEER's superiority in optimizing both model size and validation perplexity under set FLOP limits (Figure 3).
Ablation Studies
Various ablation studies explored parameters like the total and active experts, affirming the performance benefits of increasing the total expert count while optimizing active expert quantity. Results indicated the nuanced trade-offs in memory use and computational requirements.
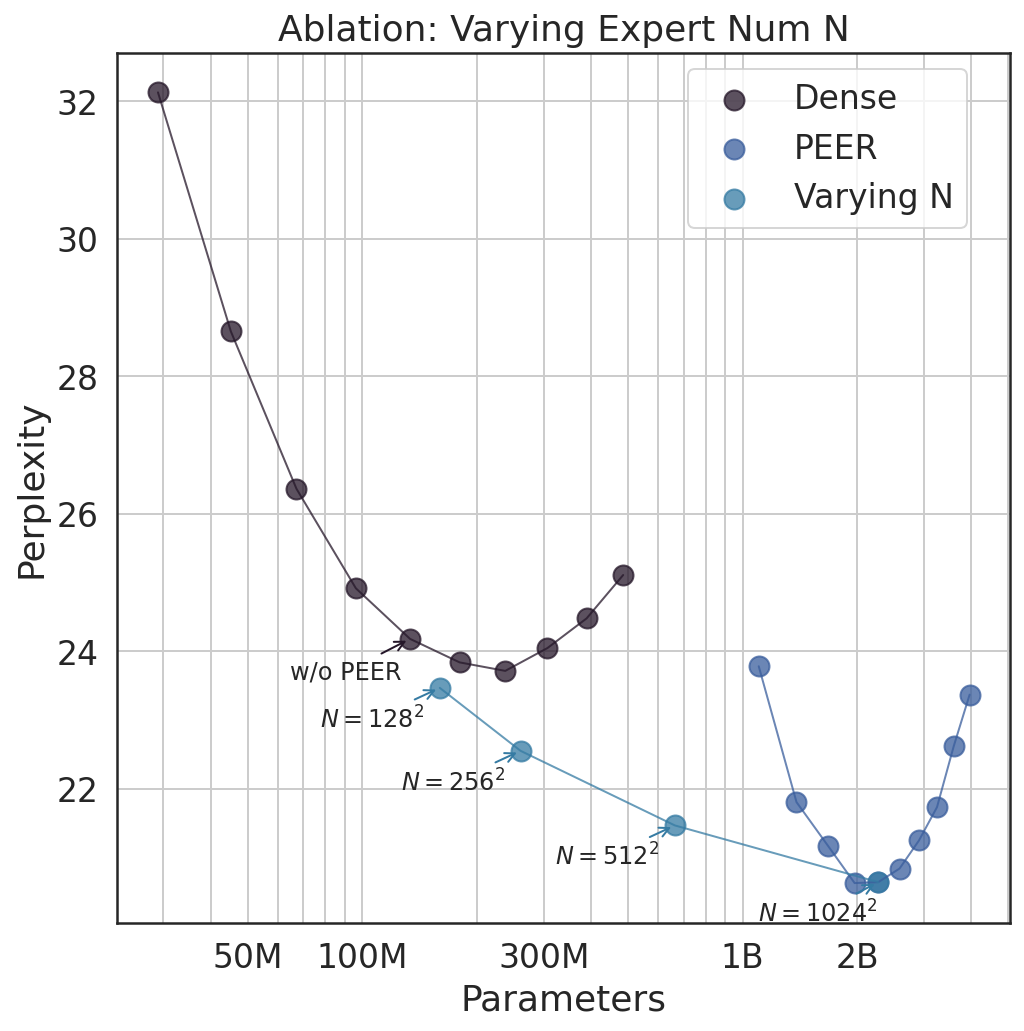
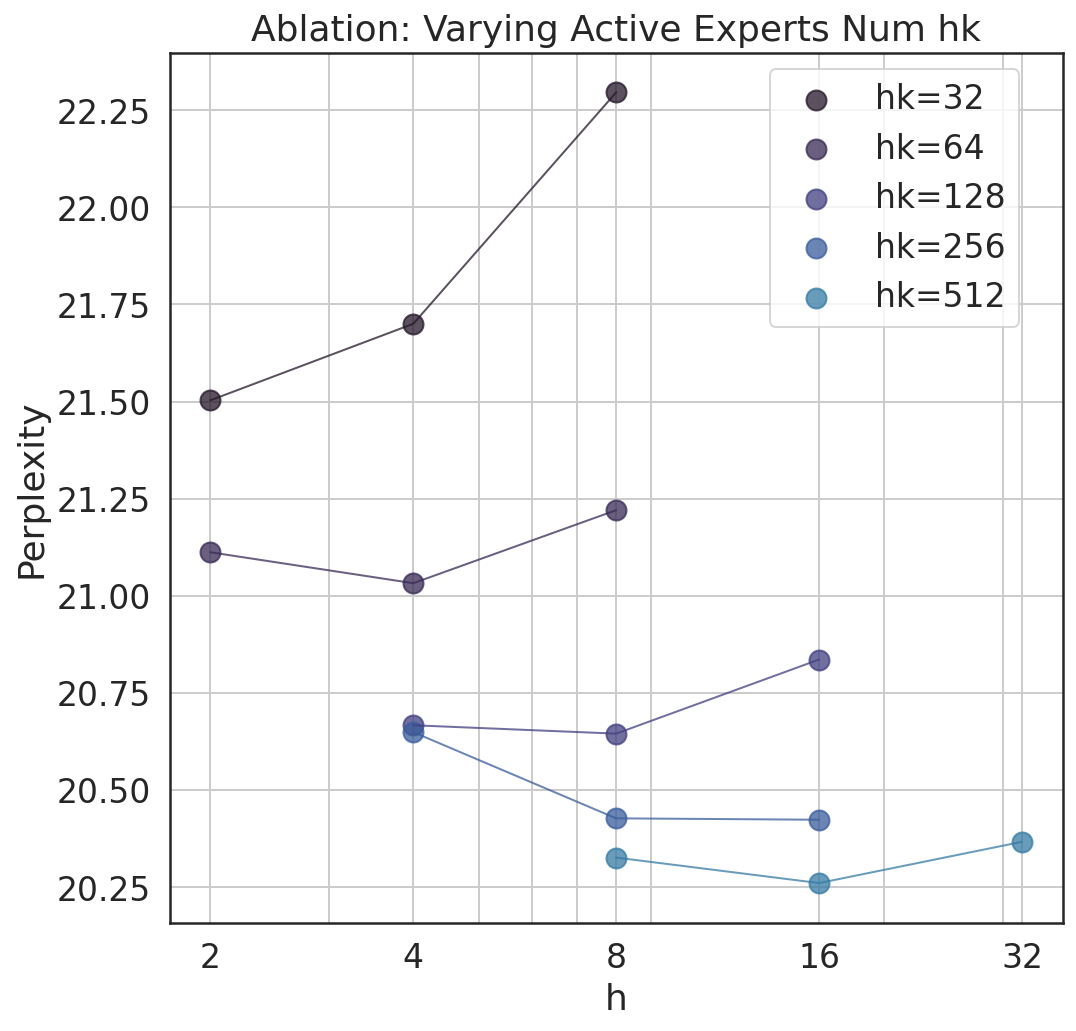
Figure 3: We conduct two ablation studies using the same PEER model configuration. In (a), we vary the total number of experts N while keeping the same number of active experts hk=128. In (b), we vary the number of active experts G=hk by jointly changing h and k while keeping the total number of experts at N=10242.
Query Batch Normalization Impact
BN application in routing improved expert usage distribution and reduced validation loss, as evidenced by balanced expert utilization statistics and improved performance metrics (Figure 4).
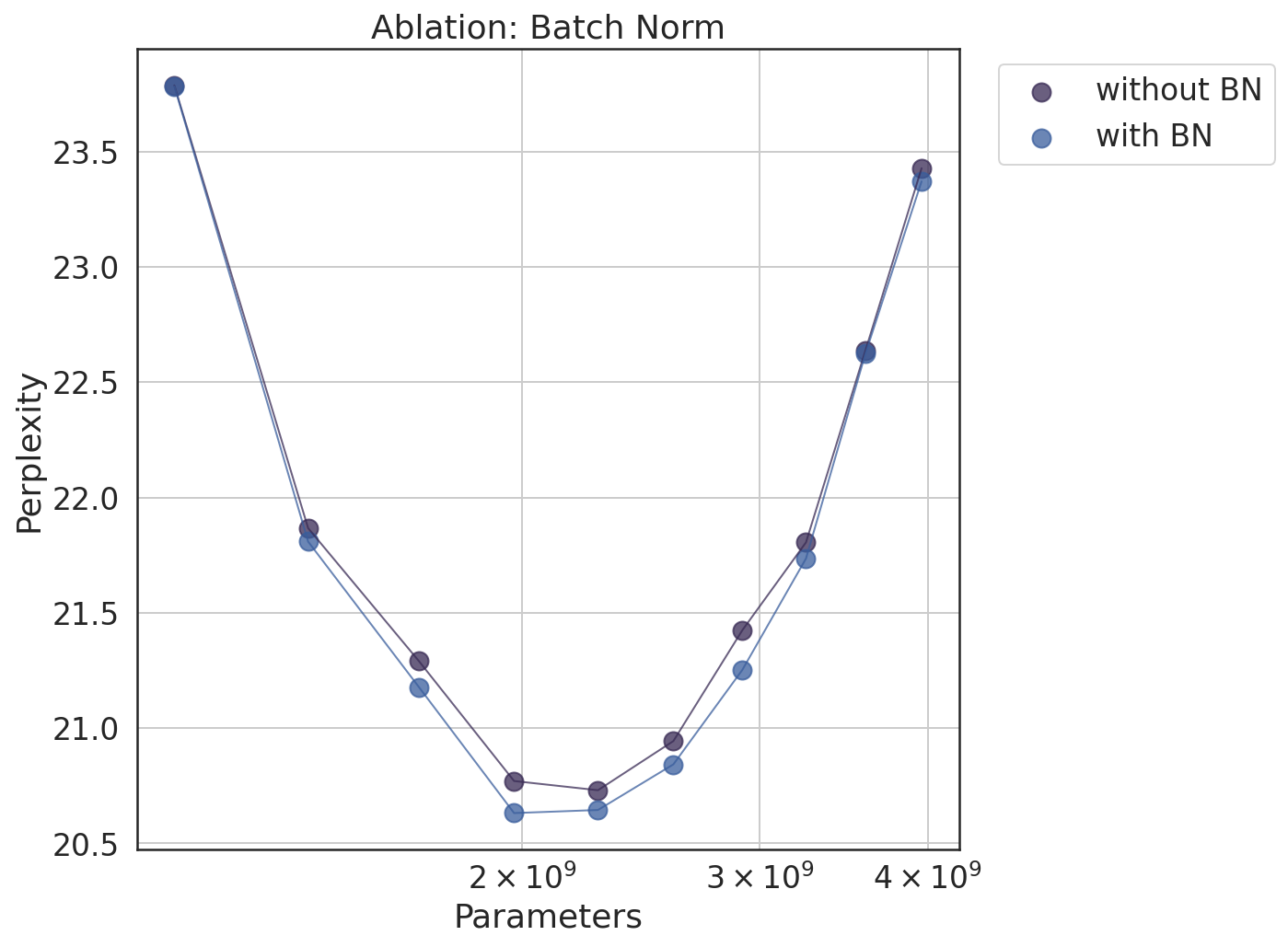
Figure 4: Query BatchNorm Ablation. IsoFLOP curves of a PEER model with 1M experts on the C4 dataset, with and without query BatchNorm.
Implications and Future Directions
The PEER architecture represents a shift towards massively scalable transformer models. Its potential extends beyond traditional efficiency gains, supporting the expansion of lifelong learning systems. Future work may explore integration into varied domains beyond language modeling and adapt the retrieval mechanism for more generalized context-specific applications.
PEER's methodology offers a promising alternative path for advancing AI scalability, setting the groundwork for further enhancements in expert retrieval efficiency and performance metrics in AI model architectures.
Conclusion
The research offered a foundational overview of achieving parameter efficiency in large-scale AI models through the PEER architecture. ME architecture approaches such as PEER pave pathways to future explorations in efficient model scaling, perpetual learning scenarios, and neural network optimizations that can redefine model capabilities and constraints.