A Practical Review of Mechanistic Interpretability for Transformer-Based Language Models
Abstract: Mechanistic interpretability (MI) is an emerging sub-field of interpretability that seeks to understand a neural network model by reverse-engineering its internal computations. Recently, MI has garnered significant attention for interpreting transformer-based LMs, resulting in many novel insights yet introducing new challenges. However, there has not been work that comprehensively reviews these insights and challenges, particularly as a guide for newcomers to this field. To fill this gap, we present a comprehensive survey outlining fundamental objects of study in MI, techniques that have been used for its investigation, approaches for evaluating MI results, and significant findings and applications stemming from the use of MI to understand LMs. In particular, we present a roadmap for beginners to navigate the field and leverage MI for their benefit. Finally, we also identify current gaps in the field and discuss potential future directions.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is a friendly, practical guide to a research area called mechanistic interpretability (MI) for transformer-based LLMs (the kind of AI that powers tools like chatbots). MI tries to “open the black box” and figure out how these models work inside, step by step, like reverse-engineering a complicated machine. The authors collect what’s known so far, explain the common tools, show how to evaluate results, give a roadmap for beginners, and point out open problems and future directions.
Key Questions
The paper focuses on three big, easy-to-grasp questions:
- What “features” do LLMs learn inside? A feature is a recognizable pattern, like “French text” or “positive sentiment,” that the model encodes.
- How do those features connect into “circuits”? A circuit is a pathway of computations inside the model that together perform a specific behavior (for example, copying repeated text or solving a small math task).
- Are these features and circuits universal? In other words, do similar pieces appear in different models and tasks, or is each model totally unique?
Methods and Approach (explained simply)
Think of a transformer LLM like a huge team of tiny workers (neurons and attention heads) passing messages along a network of roads (layers and the residual stream). MI uses a set of tools to figure out who’s doing what and how the roads connect. Here are the main tools, explained with everyday language:
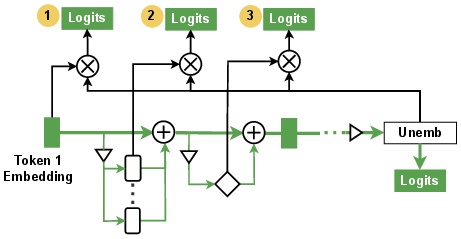
- Logit Lens: Like peeking into the model’s “half-finished thoughts” mid-sentence to guess which word it is leaning toward. It projects internal signals back into words to see what information is stored at each layer.
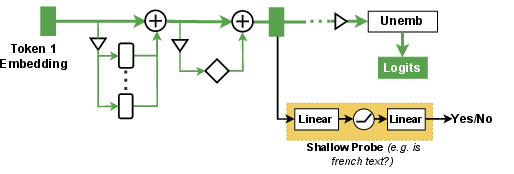
- Probing: A mini-quiz for the model’s internal signals. You train a simple classifier to check if some property (e.g., “is this French?”) is present in the activations. It shows correlation, not necessarily cause.
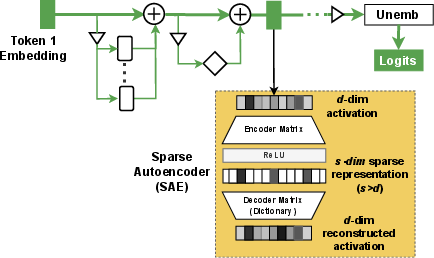
- Sparse Autoencoders (SAEs): Imagine reorganizing messy notes into a super-organized, very sparse notebook where each page is about one clear topic. SAEs spread the model’s activations into a bigger space but keep most entries zero, making it easier to find clean, human-understandable features.
- Visualization: Making pictures of attention patterns or neuron activity to spot behaviors (like which word an attention head “looks at” and why). Helpful for forming hypotheses, but you still need tests to avoid being fooled.
- Automated Feature Explanation: Using an AI (like GPT-4) to label what a neuron or feature is doing, based on its activation patterns, to save human time.
- Knockout/Ablation: Turning off a part (set it to zero, use an average, or swap it with a random sample) to see if the model’s behavior changes. If the behavior breaks, that part was important.
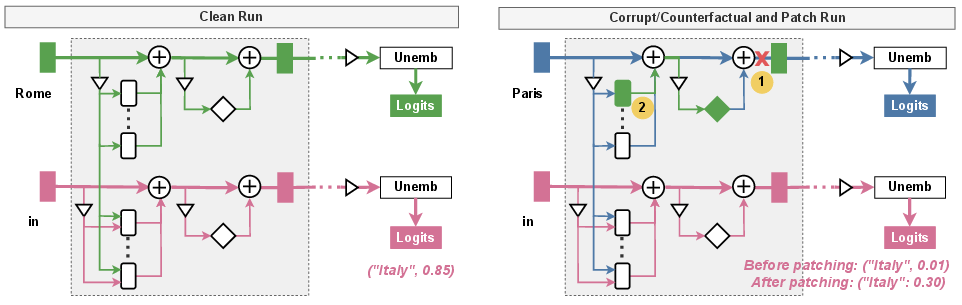
- Causal Mediation Analysis (CMA) and Patching: Running the model twice—once on a clean input, once on a corrupted input—and then “patching” internal signals from the clean run into the corrupted run. If the behavior comes back, you found a critical pathway. Path patching focuses on specific connections between parts.
The paper also presents a beginner’s roadmap: start with a clear question, observe and form hypotheses (using logit lens and visualization), validate (with ablation and patching), and then evaluate how good your explanation is.
Main Findings and Why They Matter
- Features are often polysemantic: Many neurons don’t represent just one thing; they “fire” for several unrelated features. This makes simple “this neuron equals X” explanations hard.
- Superposition: Models can cram more features into their signals than there are neurons, by mixing features together. It’s efficient but messy—features interfere with each other. SAEs help untangle this, producing clearer, more “one-thing-only” features.
- Circuits for specific behaviors: Researchers have mapped circuits for tasks like:
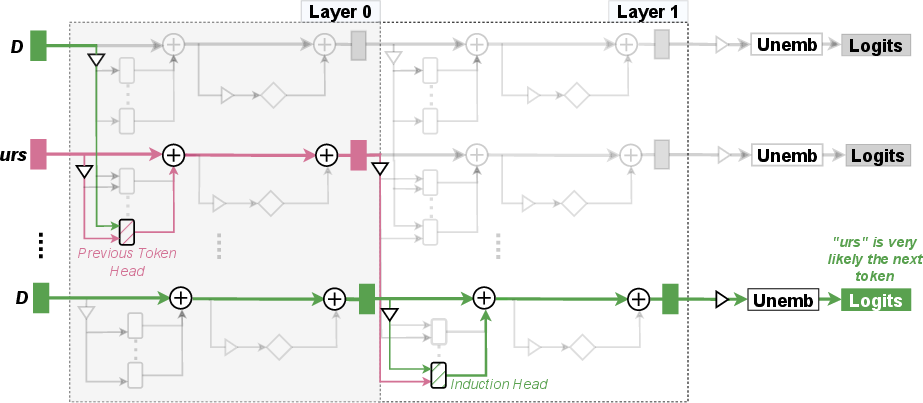
- Copying repeated patterns (an “induction” circuit)
- Identifying which name is the indirect object (IOI)
- Simple math (like greater-than or modular addition)
- Formatting code docstrings
These circuits can reuse the same components (for example, similar attention heads appear in multiple circuits), which hints at shared building blocks inside models.
- Understanding transformer parts:
- Residual Stream (RS): A running “notebook” that carries information forward through layers, letting each layer refine the current best guess.
- Attention Heads: Little spotlights that move information between tokens (words). Many heads have specialized roles (e.g., copying, suppressing certain tokens, tracking positions).
- Universality (early signs): Some features and circuits seem to show up across different models and tasks. If this holds widely, it means discoveries in small or toy models could transfer to bigger ones, saving time.
- Evaluation matters:
- Faithfulness: Does your explanation reflect the model’s actual decision process?
- Completeness: Did you find all the important pieces?
- Minimality: Did you avoid including extra, unnecessary pieces?
- Plausibility: Is the explanation understandable and convincing to humans?
These findings are important because they move us from vague guesses about “what the model might be doing” to concrete, testable explanations that can be checked and used.
Implications and Potential Impact
- Safer, more reliable AI: If we know the exact circuits behind risky or unwanted behaviors, we can monitor or modify them. This helps with AI safety and alignment.
- Better model control: Understanding features and circuits enables steering generation (nudge the model to write in a certain style) and knowledge editing (change what it “remembers” about facts).
- Practical improvements: Engineers can use MI to debug models, fix errors, or boost performance on specific tasks.
- A clearer path for newcomers: The roadmap helps beginners get started systematically, making the field more accessible.
- Open challenges: Scaling MI to huge models is hard; proving universality broadly is ongoing; and making explanations both rigorous and easy to understand remains a goal. Still, the progress so far shows that “opening the black box” is possible—and useful.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
- Formalization of “feature” and “circuit”: a basis-invariant definition and mapping across layers/components is not provided; develop standardized representations that remain stable under reparameterizations and basis changes.
- Universality of features/circuits: the survey raises the question but does not offer protocols, metrics, or large-scale evidence; design cross-model, cross-task benchmarks to quantify universality across sizes, training regimes, and domains.
- Linear representation hypothesis: limited empirical support beyond small/toy settings; rigorously test when and where activations are well-approximated by linear, decomposable feature spaces in modern LLMs (including instruction-tuned/RLHF models).
- Superposition characterization: conditions under which superposition emerges, its scaling with dimensionality/sparsity, and its impact on interference remain unclear; develop theory and diagnostics that predict and measure superposition in real models.
- SAE validity and robustness: it is unknown whether SAE features reflect ground-truth causal variables vs artifacts of sparsity objectives; assess hyperparameter sensitivity, cross-run reproducibility, feature splitting/merging, and stability across contexts and model families.
- SAE scalability: evidence for extracting interpretable features in very large LLMs (tens to hundreds of billions of parameters) is sparse; establish training recipes, compute budgets, and failure modes for SAEs at scale.
- Automated feature explanation reliability: LLM-generated labels and “automatic explanation scores” may be biased or circular; build human-annotated gold standards, measure agreement, and audit the dependence on closed-source evaluators (e.g., GPT-4).
- Probing’s causal limitations: probes report correlation rather than causation; integrate causal controls (e.g., counterfactuals, patching-based calibration) and quantify probe confounds (e.g., memorization, dataset bias).
- Logit lens alignment issues: projection via the final unembedding often misaligns intermediate representations (e.g., BLOOM case); compare and standardize alignment/transformation methods, formalize when projection is faithful, and document failure modes.
- Knockout/ablation semantics: zero, mean, and resampling ablations induce distribution shift and can misattribute importance; develop principled interventions (e.g., do-operations, causal counterfactuals) and guidelines for selecting ablation strategies per component.
- Causal mediation analysis (CMA) foundations: mediation assumptions and identifiability in deep nets are not formalized; provide theoretical conditions, sensitivity analyses, and error bounds for activation/path patching.
- Circuit discovery efficiency: patching-based localization is computationally expensive; benchmark ACDC, attribution patching, and EAP head-to-head on recall/precision/time across known circuits, and propose scalable approximations for 70B+ models.
- Evaluation metrics standardization: faithfulness, completeness, minimality, and plausibility are conceptually defined but lack shared quantitative protocols; build public benchmarks and statistical tests for these properties, including gold circuits and synthetic ground truth.
- Residual stream subspace hypotheses: the claim that different components “write” to distinct RS subspaces is not rigorously tested; directly measure subspace orthogonality/interference and its evolution across layers and training.
- Attention head independence: the assumption that heads operate independently needs systematic validation; quantify head interactions, subspace sharing, and the effect of head ablations across tasks and models.
- Omitted transformer components: positional encodings and layer normalization are excluded for brevity, yet these may materially affect MI analyses; study how these components alter feature encoding and circuit structure.
- Cross-circuit reuse and modularity: evidence of component reuse (e.g., induction heads) is anecdotal; develop metrics for circuit overlap, modularity, and resource sharing, and test how reused components trade off performance across tasks.
- Robustness of circuits to distribution shift: discovered circuits are rarely stress-tested; evaluate circuit stability under adversarial prompts, multilingual inputs, code vs natural language, and domain shifts.
- Large LLM coverage: circuit and feature discoveries are dominated by small/toy models with limited large-scale demonstrations; expand systematic MI to instruction-tuned, RLHF, mixture-of-experts, and multimodal transformers.
- Benchmarks and datasets for MI: IOI and a few toy tasks dominate; curate diversified, realistic MI benchmarks (reasoning, safety-relevant behaviors, multilingual) with standardized prompts and evaluation data.
- Extrinsic applications evidence: promised applications (AI safety, enhancement, steering, editing) are outlined without rigorous comparative evaluations; design controlled studies quantifying practical gains from MI-derived interventions.
- Reproducibility and openness: many analyses rely on proprietary models/tools (e.g., GPT-4 for labeling); ensure open-source baselines, shared code/data, and detailed reporting (seeds, hyperparameters) for MI experiments.
- Visualization subjectivity: current workflows depend heavily on human inspection; create quantitative visualization diagnostics, annotation protocols, and user studies to reduce cherry-picking and overgeneralization.
- Learning dynamics: listed as a fundamental object but not empirically detailed; trace how features and circuits emerge, transform, and consolidate throughout training (including curriculum effects and fine-tuning).
- Theoretical links between weights and functions: projections of parameter matrices (e.g., QK, VO via logit lens) suggest roles but lack formal backing; develop theory connecting parameter geometry to functional mechanisms and test across architectures.
- Safety impacts of MI: the extent to which MI mitigates concrete safety risks remains unclear; prioritize experiments where MI-guided interventions reduce jailbreaks, hidden behaviors, or deceptive strategies, with measurable safety outcomes.
Glossary
- ACDC (Automatic Circuit DisCovery): An automated method to identify circuits by iteratively localizing important components and connections. "To address it, \citet{conmy2024towards} proposed ACDC (Automatic Circuit DisCovery) to automate the iterative localization process."
- Ablation: An intervention technique that removes or replaces component outputs to assess their causal importance. "Knockout or ablation (Figure~\ref{fig:ablation}) is primarily used to identify components in a circuit that are important to a certain LM behavior."
- Activation patching: A causal technique that restores specific activations from a clean run into a corrupted run to test component importance. "Activation patching localizes important components in a circuit \cite{vig2020investigating, meng2022locating}"
- Attention head: A single attention mechanism within a multi-head attention sublayer that processes and routes information independently. "two attention heads (previous token head and induction head)"
- Attribution patching: An efficient approximation to activation patching using gradients to attribute importance to components. "\citet{nandaattribution, kramar2024atp} proposed attribution patching to approximate activation patching, which requires only two forward passes and one backward pass for measuring all model components."
- Causal Mediation Analysis (CMA): A framework for discovering circuits by systematically testing causal relationships via patching. "Causal mediation analysis (CMA) is popular for circuit discovery, including two main patching approaches (Figure~\ref{fig:patching})."
- Causal scrubbing: A hypothesis-testing method that uses resampling ablations aligned with an interpretation graph to validate circuit explanations. "\citet{chan2022causal} introduced causal scrubbing which employs resampling ablation for hypothesis verification."
- Completeness: An evaluation criterion indicating whether an explanation accounts for all causally relevant parts of a model’s behavior. "Besides faithfulness, completeness and minimality are also desirable \cite{wang2022interpretability}."
- Copy suppression head: An attention head hypothesized to reduce the likelihood of copying certain tokens by suppressing their logits. "(2.1) Generate Hypothesis \ (e.g., Attention head is a copy suppression head?)"
- Edge Attribution Patching (EAP): A gradient-based method that attributes importance to specific edges (connections) for circuit discovery. "\citet{syed2023attribution} further extended it to edge attribution patching (EAP), which outperforms ACDC in circuit discovery."
- Feed-Forward (FF) sublayer: The transformer component that applies non-linear transformations to refine token representations. "The FF sublayer then performs two linear transformations over with an element-wise non-linear function between them"
- In-context learning: A capability where models learn and apply patterns or tasks from the prompt without parameter updates. "Specific circuits have been identified for various LM behaviors such as in-context learning \cite{olsson2022context}"
- Indirect Object Identification (IOI): A benchmark/task used to study model circuits that resolve coreference to identify indirect objects. "indirect object identification (IOI) \cite{wang2022interpretability}"
- Induction circuit: A circuit that detects and continues repeated subsequences by linking attention heads across layers. "An example of an induction circuit discovered by \citet{elhage2021mathematical} in a toy LM is shown in Figure~\ref{fig:circuit}."
- Induction head: An attention head that reads and propagates sequence continuation signals to predict the next token. "previous token head and induction head"
- Knockout: A specific form of ablation where a component’s output is zeroed or replaced to test its causal role. "Does the copy suppression disappear when attention head is knocked out?"
- Logit lens: A technique that projects intermediate activations to the vocabulary space to inspect evolving token logits. "The logit lens (Figure~\ref{fig:logit-lens}) was first introduced by \citet{nostalgebraist2020blog}"
- Minimality: An evaluation criterion assessing whether an explanation contains only necessary parts; removing any part degrades performance. "On the other hand, minimality measures whether all parts of the explanation (e.g., or ) are necessary"
- Monosemantic: Refers to neurons/features that respond to only a single interpretable concept. "they are not monosemantic, i.e. they do not activate only for a single feature."
- Multi-head attention (MHA): A transformer sublayer consisting of multiple attention heads that process information in parallel. "multi-head attention (MHA) and feed-forward (FF) sublayers in each layer"
- Path patching: A causal technique that patches activations only along specific computational paths to test the importance of connections. "Path patching localizes important connections between components \cite{wang2022interpretability, goldowsky2023localizing}."
- Plausibility: An evaluation notion capturing how convincing or understandable an interpretation is to humans. "\citet{jacovi-goldberg-2020-towards} defined plausibility as “how convincing the interpretation is to humans”."
- Polysemanticity: The property of neurons/features responding to multiple unrelated concepts, complicating interpretation. "they are polysemantic, i.e. they activate in response to multiple unrelated features"
- Probing: Training a simple classifier on activations to test whether specific information is encoded. "The probing technique (Figure~\ref{fig:probing}) is used extensively in (and also before) MI to investigate whether specific information ... is encoded in given intermediate activations"
- Residual stream (RS): The sequence of token representations across layers that aggregates outputs via residual connections. "The sequence of across the layers is also referred to as the residual stream (RS) of transformer in literature~\cite{elhage2021mathematical}."
- Sparse Autoencoder (SAE): An unsupervised model that produces sparse, higher-dimensional codes to disentangle interpretable features. "SAEs (Figure~\ref{fig:sae}) serve as an unsupervised technique for discovering features from activations, especially those that demonstrate superposition"
- Superposition: A representation phenomenon where more features are encoded than available dimensions, with features linearly overlapping. "superposition, a phenomenon in LMs where their -dimensional representation encodes more than features"
- Unembedding matrix: The learned matrix that maps final-layer representations to vocabulary logits for next-token prediction. "an unembedding matrix and a softmax operation."
- Universality: The degree to which similar features/circuits recur across different models and tasks. "the notion of universality, i.e., {the extent to which} similar features and circuits are formed across different LMs and tasks"
Collections
Sign up for free to add this paper to one or more collections.

