- The paper presents the first open-source FPGA implementation of the MX standard, enabling efficient low-precision neural network computations.
- It details custom dot product operations using error-free accumulation techniques and adjustable block sizes for precision and resource trade-offs.
- Integration with the Pytorch framework and Brevitas demonstrates improved accuracy and lower FPGA resource usage in tests like ResNet-18.
Exploring FPGA Designs for MX and Beyond
The paper discusses the first open-source implementation of the Open Compute Project MX standard for Field-Programmable Gate Arrays (FPGAs). This new standard aims at supporting low-precision computation for neural networks, a crucial step toward enhancing efficiency in training and inference tasks, especially in edge device scenarios where computational resources are constrained.
Introduction to the MX Standard
The MX standard is developed to address the growing need for executing neural network operations in a more compact format compared to traditional IEEE FP32. The standard incorporates novel quantization techniques, introducing scale sharing mechanisms that allow for flexibility and efficiency in representing model parameters with fewer bits, like INT5 or FP6. This flexibility provides a notable advantage for FPGAs, which can be configured to optimize custom data paths and capitalize on smaller area footprints.
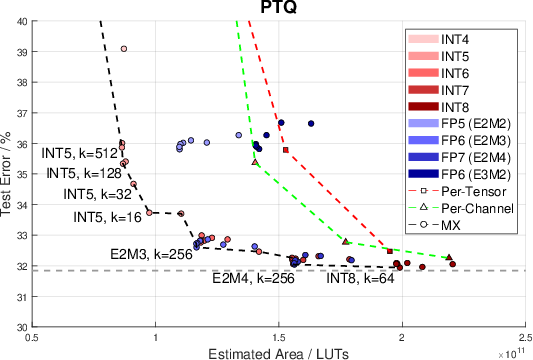
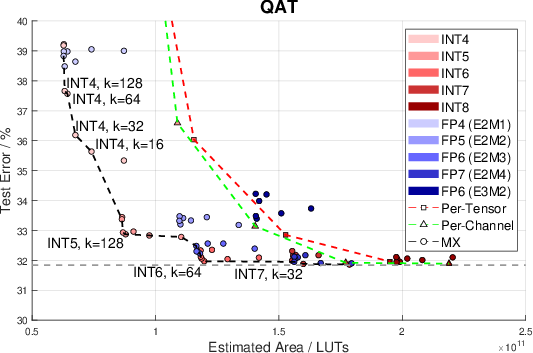
Figure 1: Error vs. estimated area of quantization schemes. Marker shape shows scale sharing regime. The grey dotted line is the FP32 baseline, other dotted lines show Pareto fronts. Pareto-optimal points are labelled with format and block size. Only schemes that offered more than 60% accuracy are shown.
Hardware Implementation on FPGAs
The implementation details encapsulate the creation of a library of optimized hardware components that fully support arithmetic operations defined in the MX standard. The hardware comes with various choices left by the standard as implementation-defined, which allow further customization, specific to FPGAs. Special attention is given to the handling of special values such as NaNs and Infs, particularly in configurations where special encoding may or may not be supported by the element format.
Dot Product Implementation
The paper lays out the precise structure of the dot product operations prescribed by MX, facilitated by error-free accumulation techniques adapted to FPGA architecture. Specifically, it employs Kulisch accumulation and pairwise summation prevalent in hardware implementations to maintain precision despite narrowed dynamic range. The components also show adaptability by allowing parameters such as block size k to be varied, permitting exploration of trade-offs between computational precision and resource consumption.
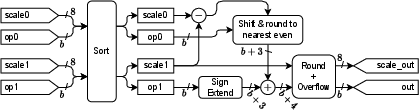
Figure 2: An adder that normalises operands, similar to a floating-point adder.
Integration into Neural Network Frameworks
The research extends the implementation by incorporating these new quantization methods into the existing Pytorch framework, leveraging Brevitas for ease of use in quantization-aware training (QAT). This setup enables mixed-precision training, blurring the boundaries between training robustness and low-power inference concessions.
Accuracy and Resource Trade-offs
A significant focus of the evaluation places accuracy against resource usage, demonstrating how different configurations and granularities in scale sharing and quantization formats affect neural network performance. When using networks like ResNet-18, various tested formats such as MXINT4 and MXFP6 achieve an advantageous balance, showing reduced errors while considerably bringing down the FPGA area required.
Conclusion and Future Work
The paper concludes with possible extensions into mixed-precision neural network models and alternative scaling methods. It identifies exciting avenues for future exploration, potentially broadening the application scope of MX beyond contemporary low-precision needs, but it underscores the importance of ongoing optimization for seamless integration across diverse neural network applications and FPGA platforms. Such exploration may yield further advancements in the tailored design of neural network accelerators, both in the open-source hardware space and in extended AI model and edge applications.

