- The paper presents a scalable APS approach that segments text into atomic propositions using supervised LLMs and knowledge distillation.
- It introduces novel evaluation metrics and grouping methods to accurately assess proposition quality and support downstream NLP tasks.
- Results show that domain-general models distilled from teacher LLMs outperform few-shot baselines across diverse datasets.
Scalable and Domain-General Abstractive Proposition Segmentation
Introduction
The paper addresses the critical task of abstractive proposition segmentation (APS), which focuses on segmenting text into simpler, self-contained, well-formed sentences. This task is essential for numerous NLP applications where traditional sentence segmentation falls short due to the complexity and multi-unit nature of sentences. APS is framed as a supervised task using LLMs, enhancing its scalability and accuracy over few-shot models. The researchers propose new evaluation metrics, leverage existing annotated datasets, and introduce scalable models trained via knowledge distillation from LLMs.
Methodology
The approach is centered on transforming extensive text documents into concise propositions that abide by atomicity and self-contained criteria. The research distinguishes between ungrouped and grouped propositions for model training.
Ungrouped Propositions: In this approach, the input text comprises an instruction and a complete passage, while the output is a sequential list of propositions (Figure 1).
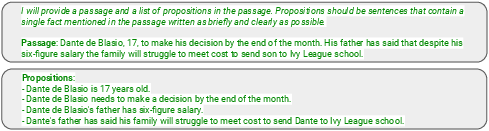
Figure 1: The input (top) and output (bottom) for training an APS model with ungrouped propositions.
Grouped Propositions: Here, the text is split into sentences marked by special start and end tokens. The model outputs grouped propositions per sentence, separated similarly (Figure 2). This method facilitates the direct attribution of propositions to sentences, particularly beneficial in downstream applications such as grounding or fact verification tasks.

Figure 2: The input (top) and output (bottom) for training an APS model with grouped propositions.
Evaluation and Results
The paper introduces a suite of automatic evaluation metrics examining proposition quality across various dimensions. These include reference-free metrics for assessing support and recall and reference-based metrics correlating propositions with a gold standard. The integration of NLI models provides backbone support for these metrics, enhancing precision and recall calculations.
Empirically, the trained models, particularly those leveraging grouped propositions, outperform existing few-shot prompting baselines in both in-domain (news articles) and out-of-domain (Reddit and Amazon reviews) contexts. The domain-general student models distilled from teacher LLMs (e.g., Gemini Ultra and Pro) further demonstrate robustness, delivering performance similar to or exceeding the original larger models.
Implications and Future Work
The research presents significant implications for scalable NLP model deployment across diverse domains. The successful demonstration of domain generalization paves the way for wider adoption of APS in NLP tasks, potentially enhancing performance in retrieval, summarization, and fact-checking applications. The release of an APS API marks a practical contribution, facilitating broader access and application of these segmentation techniques.
Future work could focus on refining the atomicity and context independence of propositions, potentially adapting models to user-specific demands. Additionally, exploring multilingual capabilities and expanding the framework to non-English datasets could broaden applicability and enhance the universality of APS techniques.
Conclusion
This paper provides a comprehensive methodology for scalable and accurate abstractive proposition segmentation. Through a combination of supervised learning, novel evaluation metrics, and knowledge distillation, the researchers effectively address the limitations of existing few-shot models, demonstrating improved scalability and domain generalization. The findings underscore the potential for APS to enhance NLP applications where intricate textual deconstruction is necessary.

