Efficient World Models with Context-Aware Tokenization
Abstract: Scaling up deep Reinforcement Learning (RL) methods presents a significant challenge. Following developments in generative modelling, model-based RL positions itself as a strong contender. Recent advances in sequence modelling have led to effective transformer-based world models, albeit at the price of heavy computations due to the long sequences of tokens required to accurately simulate environments. In this work, we propose $\Delta$-IRIS, a new agent with a world model architecture composed of a discrete autoencoder that encodes stochastic deltas between time steps and an autoregressive transformer that predicts future deltas by summarizing the current state of the world with continuous tokens. In the Crafter benchmark, $\Delta$-IRIS sets a new state of the art at multiple frame budgets, while being an order of magnitude faster to train than previous attention-based approaches. We release our code and models at https://github.com/vmicheli/delta-iris.

























Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to train game-playing AI agents faster and more efficiently by building a better “world model.” A world model is like the agent’s imagination: it learns how the game works so the agent can practice in its head instead of always playing the real game. The new agent, called DIRIS, makes this “imagination” cheaper and more accurate by encoding only what changes from one game frame to the next and by helping its prediction model keep track of the current situation with simple summaries.
Key Objectives
The researchers set out to answer a few practical questions:
- How can we make AI agents learn in complex, visual games without needing huge computers and very long training times?
- Can a world model focus on the unpredictable parts of a game (like random enemies appearing) and let simpler parts (like the player moving right when pressing right) be handled more directly?
- Will this approach make training faster while still getting strong results?
How the Method Works
To make this accessible, think of a video game as a long flipbook of pictures (frames). Traditional methods try to encode each picture separately into small tokens (like compressing them into Lego bricks) and then predict the next picture token by token. That gets slow when the images are detailed and sequences are long.
DIRIS changes two things: it encodes only what changed and it gives the predictor a simple summary of the current frame to keep it grounded.
World Models and “Learning in Imagination”
- Instead of always playing the real game, the agent first learns a simulator of the game (the world model).
- Then it practices in that simulator by imagining future steps, earning rewards, and improving its strategy.
- This saves time because imagined steps are faster and cheaper than real ones.
Encoding Changes Instead of Whole Pictures (Autoencoder)
- A standard autoencoder compresses each frame independently into discrete tokens. That means it must capture everything in the image every time, which is costly.
- DIRIS uses a context-aware autoencoder: it looks at the previous frames and the player’s actions when encoding the current frame.
- It only encodes the “delta”—the parts that changed and that are unpredictable. For example:
- Deterministic change: If you press “right,” your character moves right. This is predictable and doesn’t need special tokens each time.
- Stochastic (random) change: A cow appears suddenly. That’s unpredictable and needs encoding.
- The result: far fewer tokens per frame are needed, because predictable stuff doesn’t have to be re-described every time.
Analogy: Imagine you’re writing a diary about a walk. You don’t rewrite a full map at every step. You note only what changed (“turned left at the tree,” “a dog appeared”). DIRIS does the same for frames.
Predicting What Happens Next (Transformer with I-tokens)
- The predictor is a GPT-style transformer. It tries to guess the next changes (the “delta tokens”), as well as the reward and whether the episode ends.
- Predicting changes alone can be hard, because you might need to remember many past steps to know where things currently are.
- To make this easier, DIRIS adds “I-tokens” (think “image summary tokens”) into the sequence. These are simple continuous embeddings that summarize the current frame.
- With I-tokens, the transformer doesn’t need to piece together tons of past changes to know the state; it has a snapshot-like summary at each step.
- So the sequence contains:
- Actions (what the player did),
- Delta tokens (the unpredictable changes),
- I-tokens (a quick, continuous summary of the current state).
Analogy: If you’re solving a mystery, it’s much easier if you have a quick summary on each page (“where everyone is now”) rather than reading through all past notes to reconstruct the situation every time.
Training the Agent (Policy Improvement)
- The agent practices in its learned world model (its imagination).
- It sees reconstructed frames, takes actions, and the model predicts rewards and whether the episode ends.
- A standard actor-critic method is used: a value estimator predicts future rewards, and the policy (the agent’s decision-making) learns to choose better actions during imagined rollouts.
Main Findings
The team tested DIRIS on the Crafter benchmark (a Minecraft-like game) and also reported sample-efficient results on Atari.
Key results in Crafter:
- After collecting 10 million frames, DIRIS solves on average 17 out of 22 tasks.
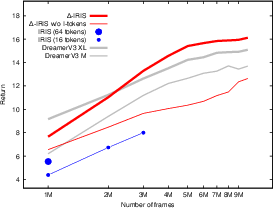
- Beyond 3 million frames, DIRIS achieves higher scores than DreamerV3 (a strong world-model baseline).
- DIRIS trains about 10 times faster than a previous transformer-based approach called IRIS.
- If you remove the I-tokens, performance drops noticeably. This shows the importance of the summary tokens.
- Even with very few tokens (e.g., 4 tokens per frame), the DIRIS autoencoder reconstructs tough frames surprisingly well, because it relies on context and encodes only the unpredictable parts.
Why this is important:
- Faster training means you can use less compute or train on bigger, more complex environments.
- Stronger world models help the agent learn smarter strategies in its imagination, reducing the need for expensive real-world interactions.
Implications and Potential Impact
This work suggests a practical path to scaling reinforcement learning in visually rich, complex worlds:
- By encoding only changes and using summary tokens, future agents can train faster and still learn high-quality behaviors.
- In real-world settings (like robotics, autonomous driving, or complex simulations), safer training becomes more possible because agents spend more time learning in accurate simulations and less time making risky moves in the real world.
- Next steps could include:
- Dynamically choosing how many delta tokens to use depending on how unpredictable the moment is.
- Reusing the world model’s internal features directly in the policy to make learning even more efficient.
In short, DIRIS shows that making the world model smarter about context and state can cut training costs and boost performance, which is a big deal for building capable agents in complex environments.
Collections
Sign up for free to add this paper to one or more collections.