Manipulate-Anything: Automating Real-World Robots using Vision-Language Models
(2406.18915)Abstract
Large-scale endeavors like RT-1 and widespread community efforts such as Open-X-Embodiment have contributed to growing the scale of robot demonstration data. However, there is still an opportunity to improve the quality, quantity, and diversity of robot demonstration data. Although vision-language models have been shown to automatically generate demonstration data, their utility has been limited to environments with privileged state information, they require hand-designed skills, and are limited to interactions with few object instances. We propose Manipulate-Anything, a scalable automated generation method for real-world robotic manipulation. Unlike prior work, our method can operate in real-world environments without any privileged state information, hand-designed skills, and can manipulate any static object. We evaluate our method using two setups. First, Manipulate-Anything successfully generates trajectories for all 5 real-world and 12 simulation tasks, significantly outperforming existing methods like VoxPoser. Second, Manipulate-Anything's demonstrations can train more robust behavior cloning policies than training with human demonstrations, or from data generated by VoxPoser and Code-As-Policies. We believe Manipulate-Anything can be the scalable method for both generating data for robotics and solving novel tasks in a zero-shot setting.
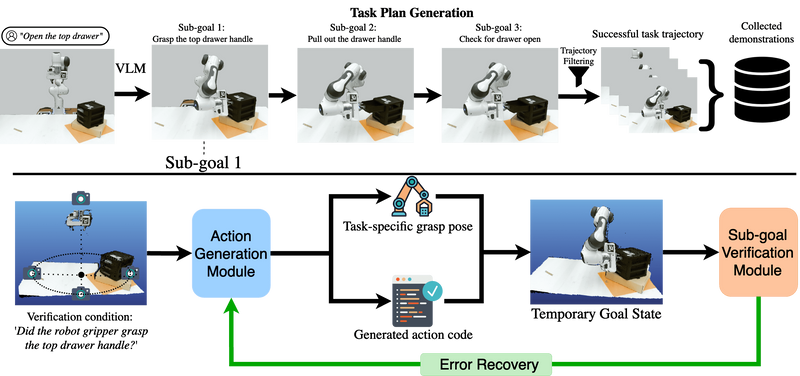
Overview
-
The paper introduces a scalable framework for generating automated robotic manipulation demonstrations using Vision-Language Models (VLMs) to operate in diverse, unstructured environments without privileged state information or hand-designed skills.
-
The methodology comprises task plan generation, action generation, and sub-goal verification, utilizing VLMs to decompose tasks, predict actions, and verify the completion of sub-goals through multi-view reasoning.
-
Experimental results demonstrate the framework's effectiveness, significantly outperforming state-of-the-art baselines in simulations and achieving notable success rates in real-world deployments, highlighting its potential for scalable and autonomous robotic learning.
Automating Real-World Robots using Vision-Language Models
The paper "Manipulate Anything: Automating Real-World Robots using Vision-Language Models" introduces an innovative method for generating automated demonstrations for real-world robotic manipulation. This technique leverages Vision-Language Models (VLMs), bypassing the need for privileged state information, hand-designed skills, or pre-defined object instances. The method is positioned as a scalable solution for both data generation in robotic training and for solving novel tasks in a zero-shot setting.
Motivation and Background
The impetus behind this research lies in the constraints posed by existing robot demonstration data collection methods. Large-scale human demonstrations are time-consuming and expensive, limiting the quantity and diversity of collected data. Although large-scale projects such as RT-1 and Open-X-Embodiment have made significant strides, their reach is restricted by human involvement and lack of variety in demonstrated tasks. The utilization of VLMs in this context presents an opportunity to automate and scale up the data collection process, rendering it more efficient and versatile.
Methodology
The proposed framework is designed to generate high-quality data for robotic manipulation, operating autonomously in varied and unstructured real-world environments. The approach involves several key steps:
Task Plan Generation:
- The system takes a free-form language instruction and a scene image as inputs.
- A VLM identifies relevant objects and decomposes the main task into discrete sub-goals.
- Each sub-goal is associated with specific verification conditions, enhancing the system's ability to adapt and re-plan if a sub-goal fails.
Action Generation Module:
- The module predicts low-level actions (6 DoF end-effector poses) based on the sub-goals.
- It distinguishes between agent-centric actions (modifying the robot's state) and object-centric actions (manipulating specific objects).
- For object-centric actions, it filters grasping poses using VLMs, selecting the ideal grasp based on the task's context.
Sub-goal Verification:
- A VLM-based verifier checks if the robot's actions meet the predefined conditions for each sub-goal.
- This component uses multi-view reasoning to ensure accurate verification, mitigating errors due to occlusions or inadequate single-view information.
Experiments and Results
The paper presents an extensive evaluation through both simulated and real-world experiments:
Simulation:
- The framework was tested on 12 diverse tasks within the RLBench environment, showcasing a broad range of manipulative actions.
- The method outperformed state-of-the-art baselines (VoxPoser and Code-As-Policies) in 9 out of 12 tasks.
- Notably, the paper reports that even without privileged state information, the system demonstrated significant robustness and adaptability.
- Data generated by the proposed method was used to train behavior cloning models.
- Models trained on this data performed comparably or superior to those trained on human-generated demonstrations, highlighting the utility and quality of the autonomous data.
Real-World Deployment:
- The system was also tested in real-world settings across five tasks, confirming its effectiveness beyond simulated environments.
- The trained policies achieved success in translating learned behaviors to physical robots, achieving task success rates up to 60%.
Implications and Future Work
The implementation of VLMs for autonomous robotic task demonstration embodies a significant evolution in scalable data collection and manipulation task automation. This method holds promise for expanding the capabilities of robotic systems to perform complex and varied tasks without human intervention, facilitating advancements in fields such as manufacturing and service robotics.
Looking forward, several areas merit further investigation:
- Enhancing zero-shot generation capabilities for more complex, multi-step tasks.
- Integrating more advanced VLMs as they evolve, leveraging their improved planning and scene understanding abilities.
- Exploring the incorporation of reinforcement learning to further refine the action generation and sub-goal verification processes.
In conclusion, this paper introduces a robust framework that substantially enhances the autonomy and scalability of robot demonstration generation, marking a meaningful contribution to the realm of robotic manipulation. This approach, by leveraging state-of-the-art VLMs, stands poised to redefine the landscape of robotic learning and deployment.
Create an account to read this summary for free: