- The paper demonstrates that leveraging LLMs with zero-shot and few-shot techniques significantly improves dialogue evaluation over traditional metrics.
- The methodology employs logits and chain-of-thought generation methods to yield evaluation scores that closely align with human judgments.
- Experiments show that fine-tuning with approaches like LoRA and strategic in-context learning boosts performance and scalability in quality measurement.
Leveraging LLMs for Dialogue Quality Measurement
The paper "Leveraging LLMs for Dialogue Quality Measurement" explores using LLMs to enhance the evaluation of task-oriented dialogue systems. It focuses on implementing zero-shot and few-shot capabilities and demonstrates improvements over traditional metrics like BLEU and ROUGE.
Introduction
Evaluating conversational AI remains challenging due to the complex dynamics involved in dialogues, such as one-to-many mappings and contextual dependencies. Traditional evaluation metrics often fail to capture these complexities, necessitating the exploration of more advanced techniques. Recent advances in LLMs have shown potential in several NLP tasks by offering robust zero- and few-shot capabilities that enable flexible application without intensive training on specific datasets.
Methodology
The paper explores two primary methods for integrating LLMs into dialogue evaluation: the logits method and the generation method. The logits method involves using LLMs to provide a probabilistic rating based on token probabilities, offering a weighted average score as a dialogue quality metric.
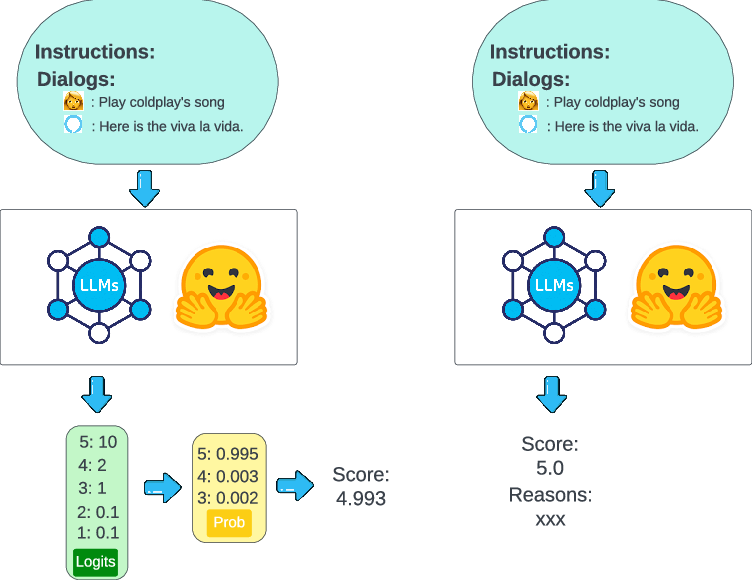
Figure 1: Schematic overview of LLM dialogue evaluation methods. Left: Pipeline using logits method for generating scores from LLMs. Right: Pipeline employing generation method to produce ratings from LLMs.
The generation method involves prompting LLMs directly to generate evaluations and accompanying explanations, leveraging the model's reasoning capabilities in a 'chain-of-thought' (CoT) fashion.
Experiment Setup
The models utilized include the Llama and Falcon series, with instruction-tuned variants to enhance directional comprehension. Both open-source and proprietary datasets are used to train and evaluate the models, examining factors such as model size, training data volume, and selection of in-context examples.
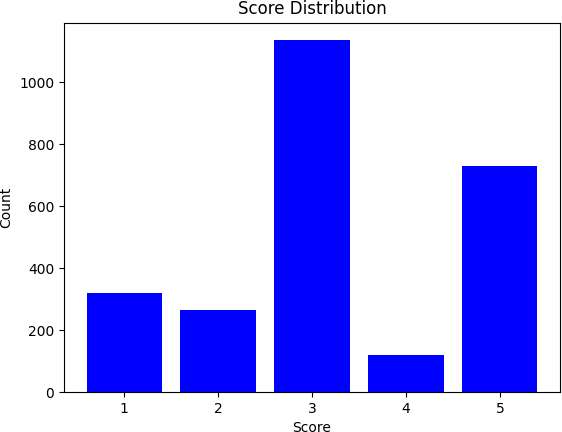
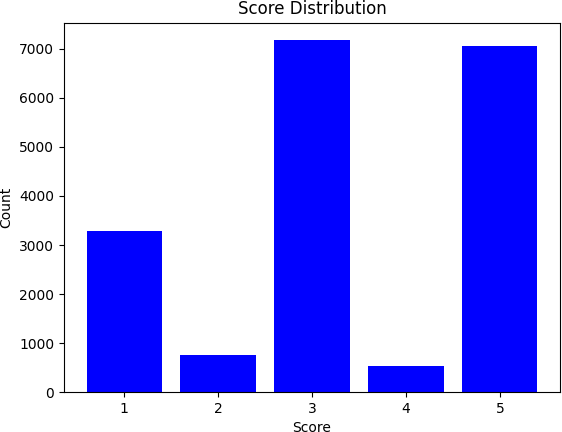
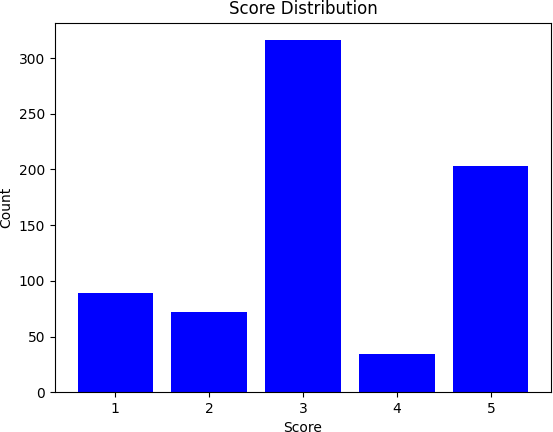
Figure 2: Score distribution in train and test splits from the Amazon-internal dataset.
Key Findings
- Model Size and Instruction-Tuning: Larger models generally exhibit better accuracy in zero-shot settings, with instruction-tuned models demonstrating superior alignment with human judgments. Alpaca- and Falcon-models outperform Llama models due to enhanced prompt comprehension and reasoning capabilities. This suggests that both scaling up models and leveraging instruction-tuning play pivotal roles in optimizing model performance.
- In-Context Learning: Incorporating in-context examples significantly enhances performance, especially when selected algorithmically (e.g., via BM25 or BERT-based semantic matching). The effectiveness of in-context examples underscores the models' ability to adapt to new tasks with minimal examples, although excess can impact performance due to input length constraints.
- Fine-Tuning: Supervised fine-tuning (SFT) using parameter-efficient methods like LoRA not only refines model alignment with human evaluations but also scales effectively across datasets of varying sizes. The improvements are evident in both correlation metrics (Spearman, Pearson) and F1-scores, demonstrating SFT's ability to enhance nuanced evaluation.
- Chain-of-Thought Reasoning: Analysis-first approaches in CoT paradigms yield better alignment of scores and reasons, outperforming the conventional rating-first frameworks. This order of operations allows models to present more consistent justifications, essential for coherent evaluation.
Practical Implications and Future Prospects
The findings indicate that LLMs, particularly when fine-tuned and coupled with CoT reasoning, have the potential to transform dialogue evaluation. By streamlining labor-intensive human evaluations and providing scalable solutions adaptable to new domains and datasets, LLMs could redefine the evaluation landscape. Continuous investigation into model architectures, scaling, and fine-tuning strategies will be crucial for future advancements, paving the way for increasingly intelligent and autonomous evaluation systems in dialogue-based AI.
Conclusion
This paper demonstrates the viability of leveraging LLMs for dialogue quality evaluation, highlighting the roles of model size, prompt engineering through instruction tuning, and CoT reasoning. The proposed methods show promise in achieving human-level evaluation standards, signifying a crucial advancement in the field of conversational AI evaluation. Future research should focus on expanding model capabilities, minimizing biases, and addressing ethical concerns to ensure these systems' broader applicability and fairness.

