- The paper introduces SAT, which employs noise-augmented pretraining to reduce reliance on punctuation for sentence segmentation.
- It leverages subword tokenization and a streamlined three-layer architecture to achieve threefold speed improvements over prior models.
- By using LoRA-based fine-tuning for domain adaptability, SAT excels in multilingual and noisy text environments.
Segment Any Text: A Universal Approach for Robust, Efficient and Adaptable Sentence Segmentation
The paper "Segment Any Text: A Universal Approach for Robust, Efficient and Adaptable Sentence Segmentation" introduces Segment Any Text (SAT), a model designed to optimize sentence segmentation across various domains and languages. SAT addresses three primary challenges: robustness against missing punctuation, adaptability to various domains, and efficiency. This essay explores the implementation details, performance metrics, and potential applications of the SAT model.
Model Design and Implementation
Robustness and Pretraining
To enhance robustness, SAT employs a unique pretraining scheme that lessens its dependence on punctuation marks. This involves training on web-scale text data, where the model learns to predict naturally occurring newline characters, effectively identifying sentence boundaries without relying heavily on punctuation.
The training process includes introducing noise by randomly removing punctuation and casing in a fraction of the samples, which diversifies the input data and prepares the model for poorly formatted text. This method ensures that SAT can handle transcriptions such as automatic speech recognition (ASR) outputs and social media text.
Efficiency Improvements
SAT's architecture is built on a subword tokenization approach, which processes multiple characters as a single token, significantly reducing inference time compared to character-level models like Where's the Point (WTP). This efficiency allows SAT to segment 1,000 sentences in about half a second on consumer-grade hardware.
SAT is further optimized by shedding the upper layers of the base model, using a three-layer configuration that maintains performance while boosting processing speed. This architectural choice results in a threefold gain in speed over previous models.
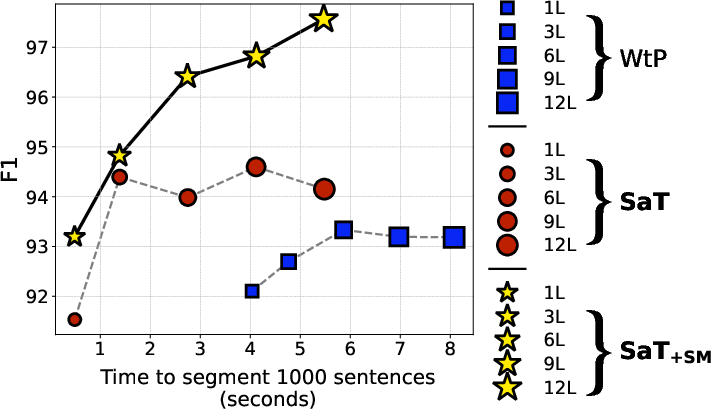
Figure 1: F1 scores and inference time for the prior SoTA (WTP) and our models (SAT and SAT+SM), evaluated on the Ersatz sentence segmentation benchmark.
Adaptability and Domain-Specific Fine-Tuning
SAT introduces a parameter-efficient fine-tuning stage using Low-Rank Adaptation (LoRA) to improve adaptability to specific domains, such as legal texts and poetry. By training on a small set of sentence-segmented examples (as few as 16), SAT can surpass previous adaptation methods like WTP's threshold tuning and punctuation prediction.
The model also incorporates a novel limited lookahead mechanism, which restricts attention to a predefined number of future tokens, enhancing performance on shorter text sequences.
SAT consistently achieves state-of-the-art performance across a range of benchmarks, including the Ersatz sentence segmentation dataset, demonstrating superior efficiency and accuracy compared to existing models. It excels particularly in multilingual scenarios, supporting 85 languages without the need for language-specific adaptations.
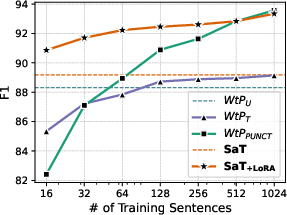
Figure 2: Macro avg. F1 vs. number of sentences used for adaptation, averaged over languages in the OPUS100, UD, and Ersatz datasets.
The model's robustness is highlighted by its ability to outperform LLMs when prompted for sentence segmentation tasks. SAT's architecture, lacking any requirement for language codes, makes it universally applicable, even in code-switched texts that combine multiple languages.
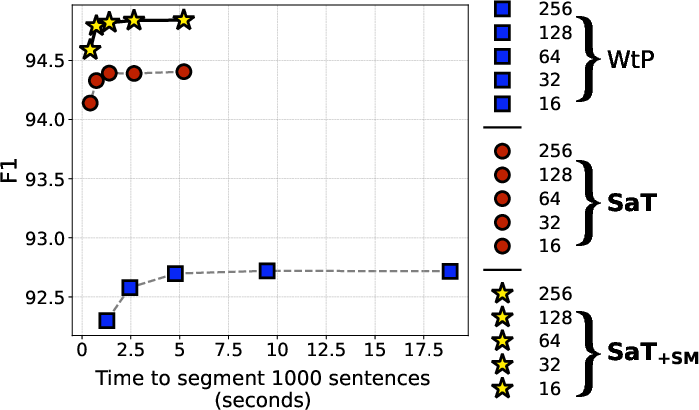
Figure 3: Sentence segmentation F1 scores vs. execution time across different strides, evaluated on Ersatz, showing substantial efficiency gains with higher stride values.
Implications and Future Work
The SAT model's efficiency and adaptability open up new avenues for applications in NLP, particularly in environments where input text is diverse and possibly noisy. Its architecture provides a foundation for further exploration into domain adaptation through techniques like LoRA, potentially expanding its use to more specialized domains not yet covered.
Future research could explore integrating SAT with emerging models, like those based on Transformer architectures, to push the boundaries of sentence segmentation even further. Additionally, variations in stride settings for different domain-specific tasks could be fine-tuned to enhance performance.
Conclusion
The Segment Any Text model represents a significant advancement in sentence segmentation, offering a robust, efficient, and adaptable solution that meets the needs of diverse NLP environments. Its innovative design and superior performance metrics position SAT as a valuable tool for researchers and practitioners looking to process vast amounts of text efficiently across multiple languages and domains.

