- The paper introduces three novel benchmarks—Spatial-Map, Maze-Nav, and Spatial-Grid—to assess spatial reasoning in vision-language models.
- It demonstrates that many VLMs perform at or below random guessing levels when relying solely on visual inputs.
- Findings imply that more effective integration of multimodal inputs is essential to advance human-like spatial reasoning in AI.
Delving into Spatial Reasoning for Vision LLMs
Introduction
The paper "Is A Picture Worth A Thousand Words? Delving Into Spatial Reasoning for Vision LLMs" (2406.14852) investigates the spatial reasoning capabilities of LLMs and Vision-LLMs (VLMs). Despite their remarkable performance on various tasks, these models confront significant challenges in spatial reasoning—a fundamental aspect of human cognition. The authors introduce three novel benchmarks, namely Spatial-Map, Maze-Nav, and Spatial-Grid, designed to evaluate models on spatial reasoning, including relationship understanding, navigation, and counting. Their comprehensive evaluation reveals several counterintuitive insights about the reliance on multimodal inputs for spatial understanding.
Benchmarks and Tasks
The research introduces three distinct benchmarks to evaluate spatial reasoning:
- Spatial-Map: This benchmark simulates a map environment with configurable objects, focusing on spatial relationship comprehension among items.
- Maze-Nav: A navigation task emulating a maze, testing the ability to trace paths from a start to an end point, incorporating obstacles and distinct paths.
- Spatial-Grid: This task evaluates spatial reasoning within a rigid grid structure, assessing positional understanding and object counting.
For all these tasks, three input modalities are considered: Text-only, Vision-only, and Vision-text.
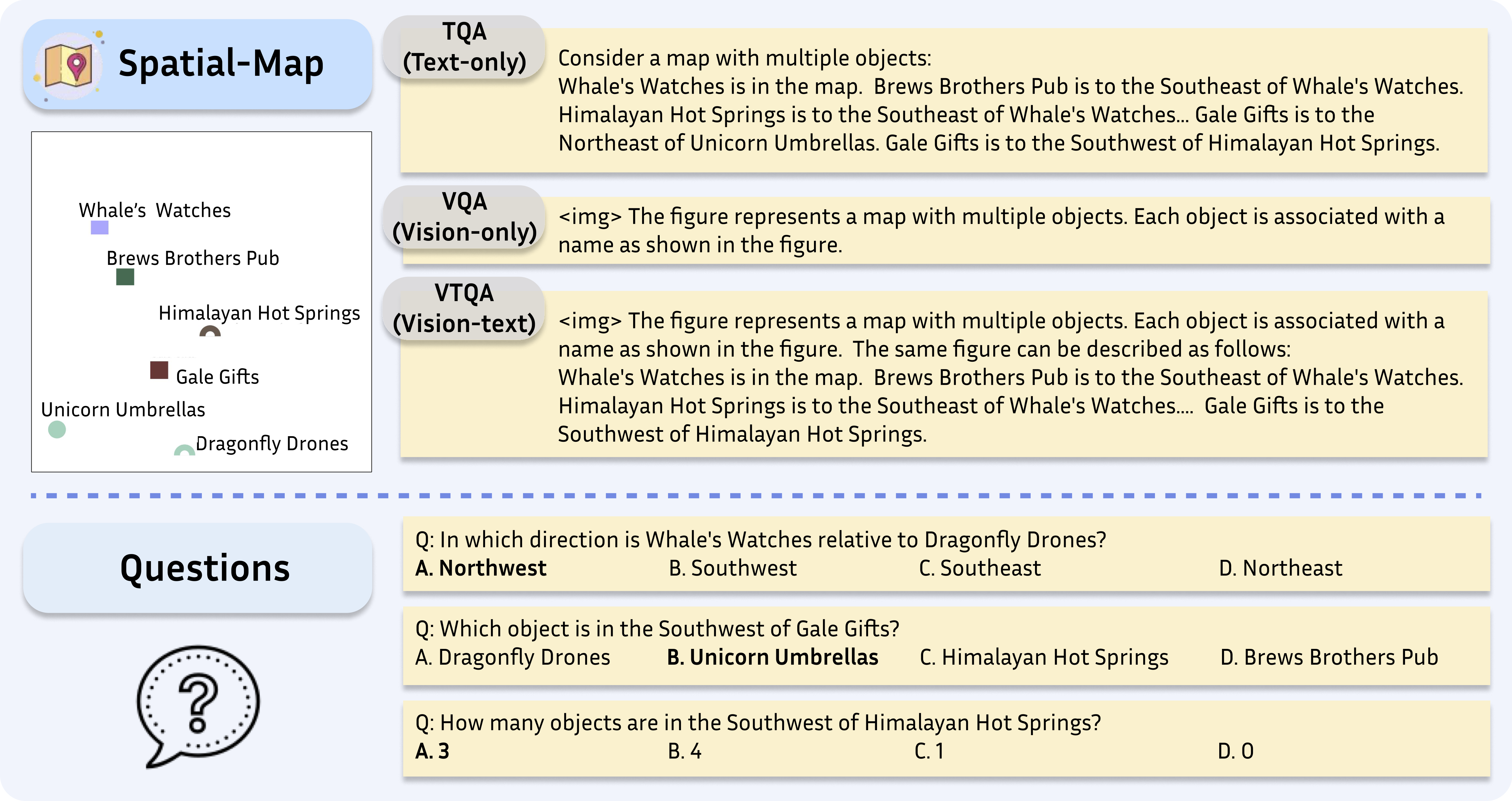
Figure 1: Illustration of the Spatial-Map task, showcasing different input formats to evaluate both language and multimodal models.

Figure 2: Illustration of the Maze-Nav task, demonstrating the model's navigation abilities using various input modes.
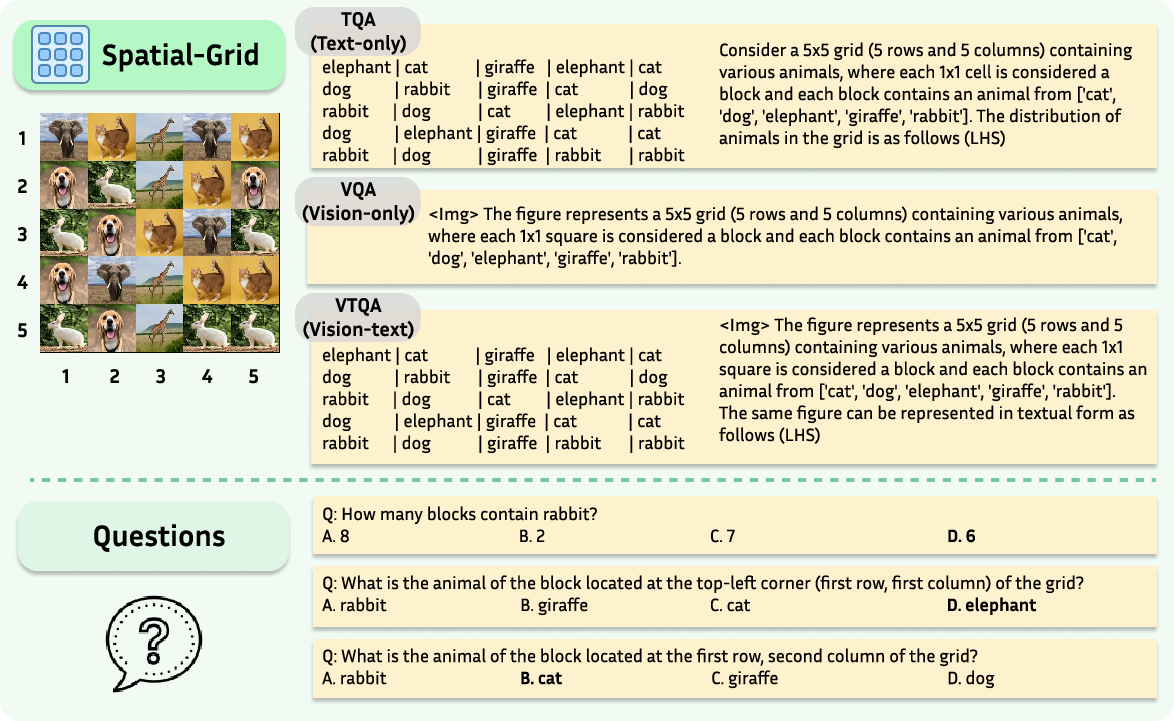
Figure 3: Illustration of the Spatial-Grid task, used for assessing structured spatial reasoning capabilities.
Main Findings
The results demonstrate that spatial reasoning persists as a substantial challenge for existing models:
- Performance Below Random Guessing: Many VLMs perform at or below random guessing levels on tasks like Maze-Nav and Spatial-Map when given vision-only inputs (Figure 4).
- Insufficient Advantage from Visual Inputs: Across diverse tasks, adding visual information did not always enhance performance beyond that of text-only inputs. VLMs frequently underperformed compared to their LLM counterparts when solely visual data was relied upon.
- Effective Leveraging of Textual Clues: When both textual and visual inputs are provided, models tend to rely more on textual clues. Removing or replacing visual input with noise or random images did not significantly degrade performance, indicating limited model reliance on visual data (Figures 6, 7, and 8).
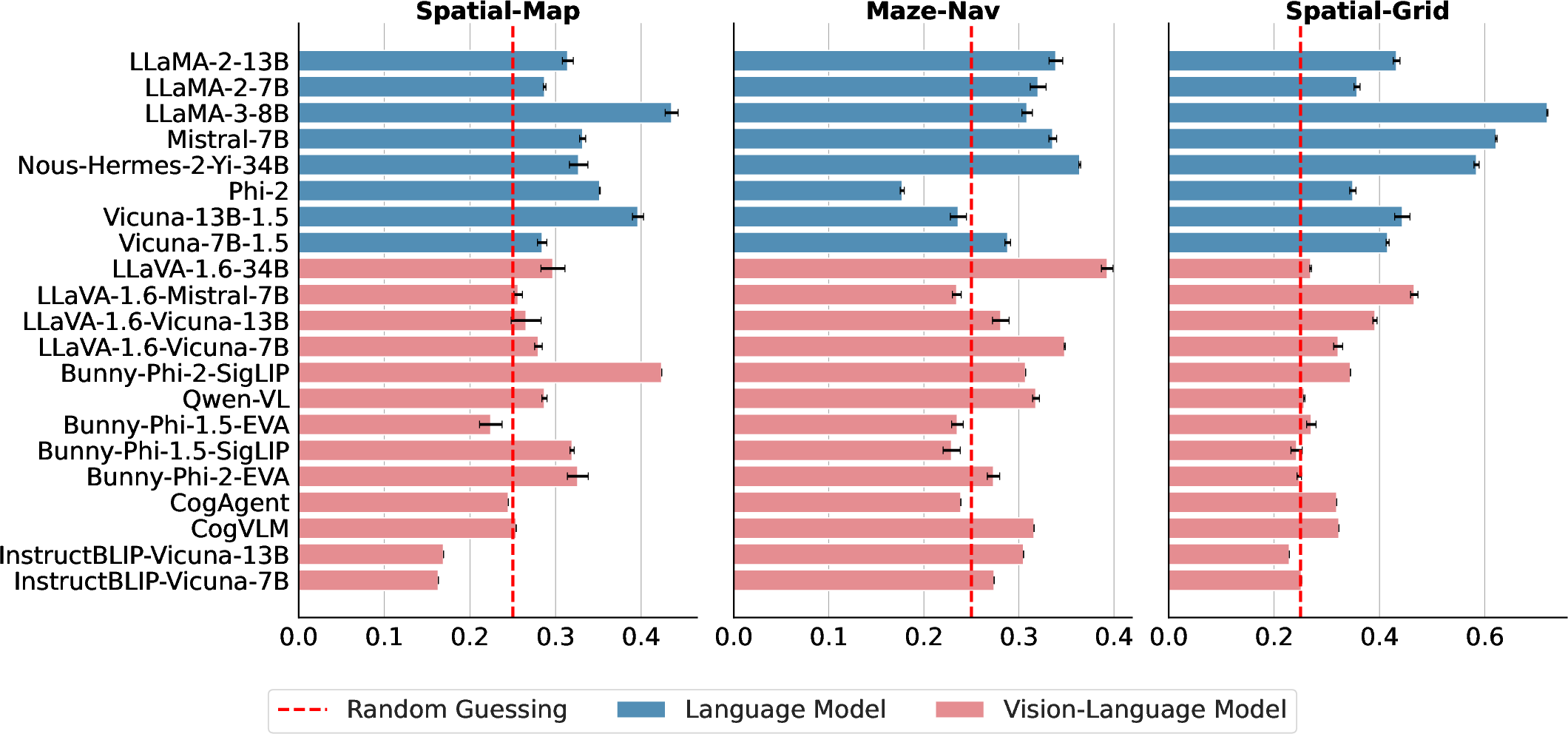
Figure 4: Performance overview on spatial reasoning tasks, illustrating the limited success of models when only visual inputs are employed.
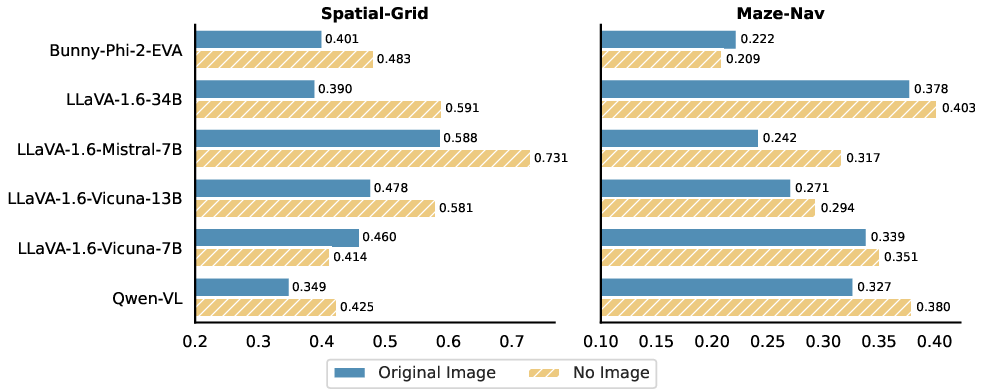
Figure 5: Comparison of original image with no image input in VTQA, showing improved model performance when visual inputs are absent.
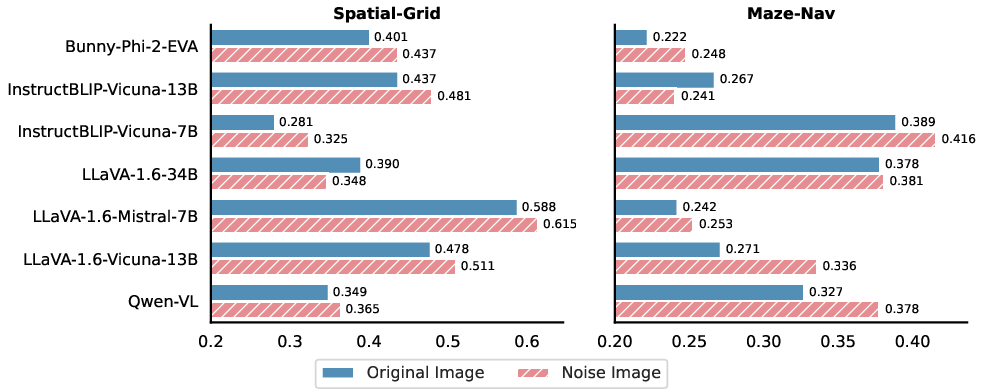
Figure 6: Using noise image instead of original image, highlighting enhanced performance across VLM architectures.
Implications and Future Directions
The findings question the efficacy of the current VLM architectures that prioritize textual inputs over visual data, suggesting a need for models that more effectively integrate multimodal information. This could inform future architectural innovations that better emulate human-like spatial reasoning capabilities, potentially advancing AI applications in navigation, environmental interaction, and tasks requiring comprehensive spatial understanding.
Conclusion
This paper highlights critical limitations in the spatial reasoning abilities of contemporary vision-LLMs, uncovering a surprising preference for textual information even in ostensibly visual tasks. It urges the development of new methodologies and model structures that honor the integral role of visual data, aspiring to bridge the performance gap between AI and human cognitive skills in spatial intelligence.
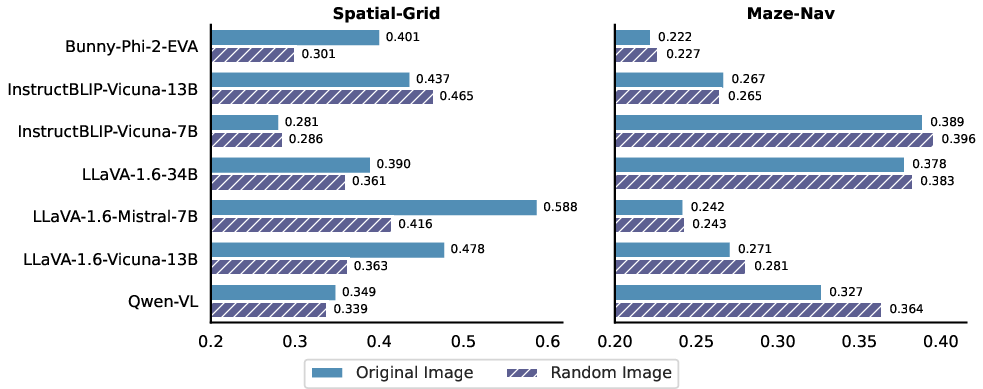
Figure 7: Results indicating performance improvements when replacing original images with random ones, demonstrating VLM's limited dependence on specific visual inputs.

