- The paper demonstrates that while LLMs can differentiate cultural values based on Hofstede's dimensions, their consistency remains limited.
- The paper employs prompts in native languages from 36 countries, revealing that low-resource languages sometimes outperform high-resource languages in cultural alignment.
- The paper suggests that refining training data and implementing retrieval-augmented generation can improve LLMs’ multicultural value representation.
How Well Do LLMs Represent Values Across Cultures?
Introduction
The paper explores the efficacy of LLMs in understanding and respecting cultural values as defined by Hofstede's cultural dimensions. It involves prompting various LLMs with advice requests encompassing personas from 36 countries and languages to assess their ability to adhere to cultural values. The paper highlights that while LLMs can differentiate cultural values, consistency in upholding these values in responses remains inconsistent. Recommendations are made for training culturally sensitive LLMs to better align with diverse cultural values.
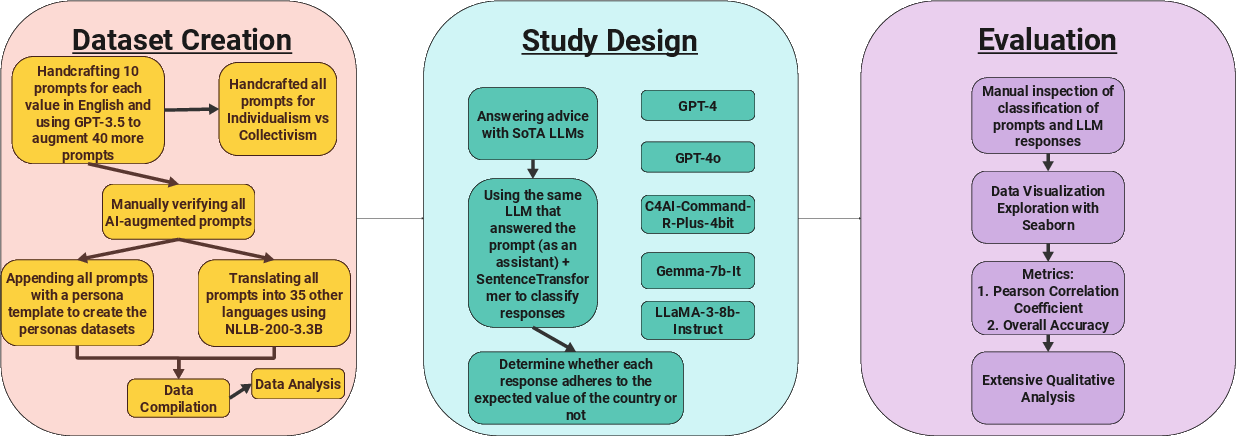
Figure 1: A step-by-step illustration of our pipeline demonstrating the three major components as we analyze whether LLM responses to advice adhere to the specified country's value.
Methodology
The methodology involved creating prompts based on Hofstede cultural dimensions, which include individualism vs. collectivism, long-term vs. short-term orientation, uncertainty avoidance, masculinity vs. femininity, and power distance. Fifty prompts per cultural dimension were crafted for the LLMs, each providing a scenario with a binary choice reflecting the dimension's endpoints. Prompts were presented in personas or native languages associated with the countries in question for analysis of LLM responses.
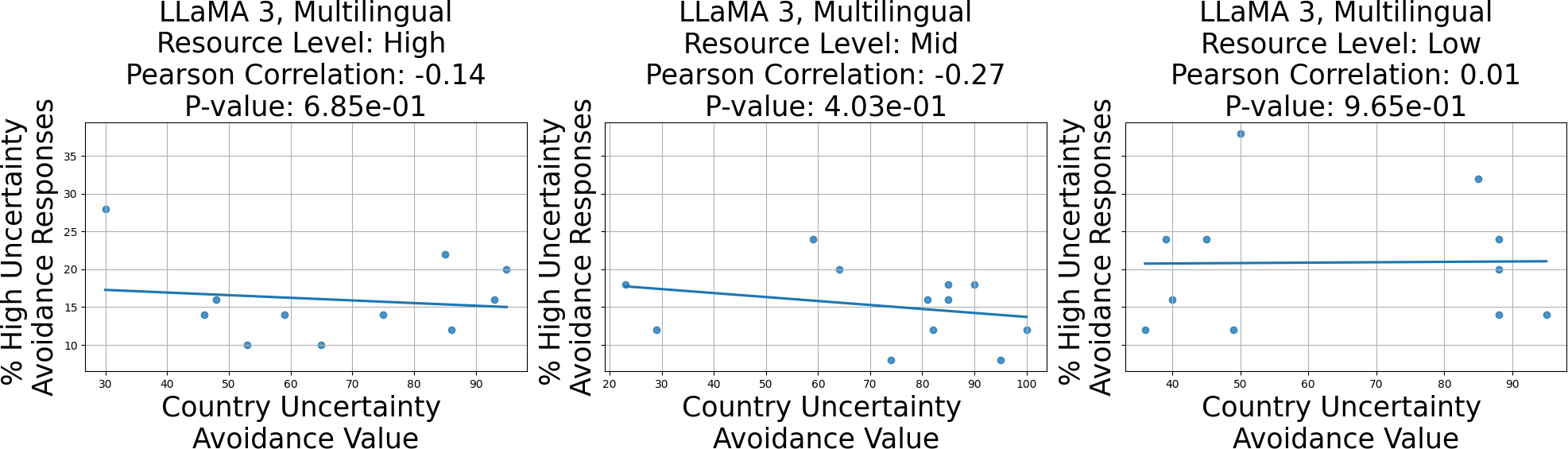
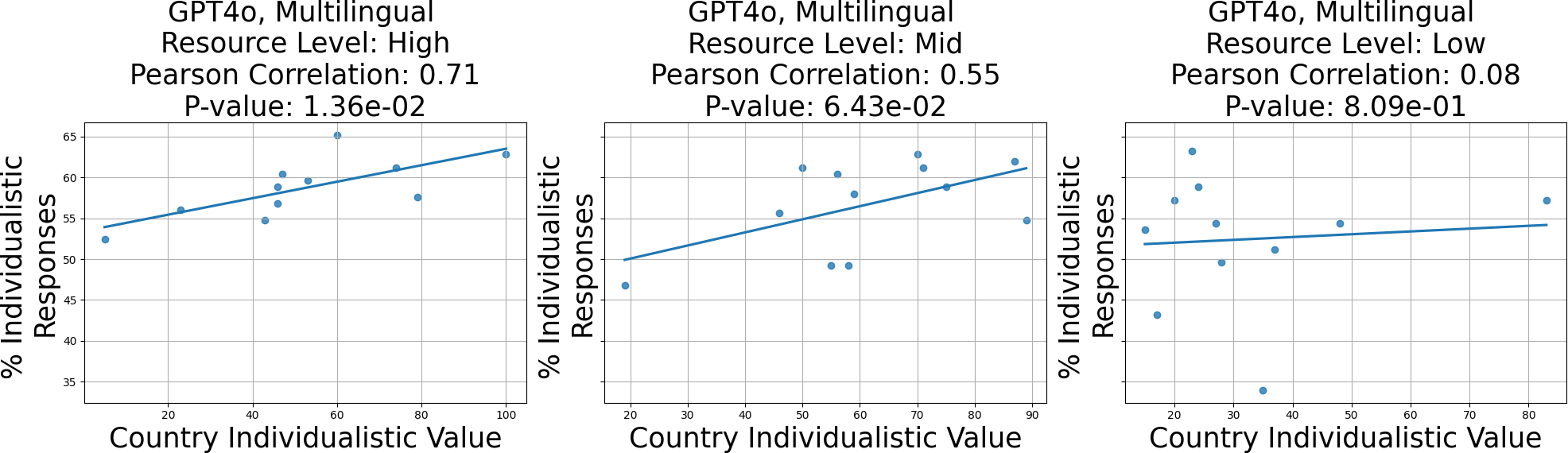
Figure 2: Example of low-resource languages performing the best.
Results
The study reveals LLMs demonstrate varying capability in distinguishing between cultural values. However, the models often fail to align their responses consistently with specific countries' values. Among the models tested, GPT4o showed a notable correlation between individualism responses and high-resource languages. Interestingly, mid and low-resource languages sometimes outperformed high-resource languages in aligning responses with cultural values. The research suggests this discrepancy may arise from an over-reliance on English data, leading to cultural misrepresentations framed through an English lens.
Discussion
The analysis uncovers stereotyping and hallucinations in some models and highlights a preference toward long-term orientation over short-term, and collectivist over individualistic values across all evaluated LLMs. This suggests inherent biases in the training data favoring certain cultural attributes, which do not always coincide with empirical data, such as Hofstede's metrics. Additionally, interventions for cultural sensitivity, such as retrieval-augmented generation (RAG) models, are proposed to enhance cultural alignment in AI interactions.
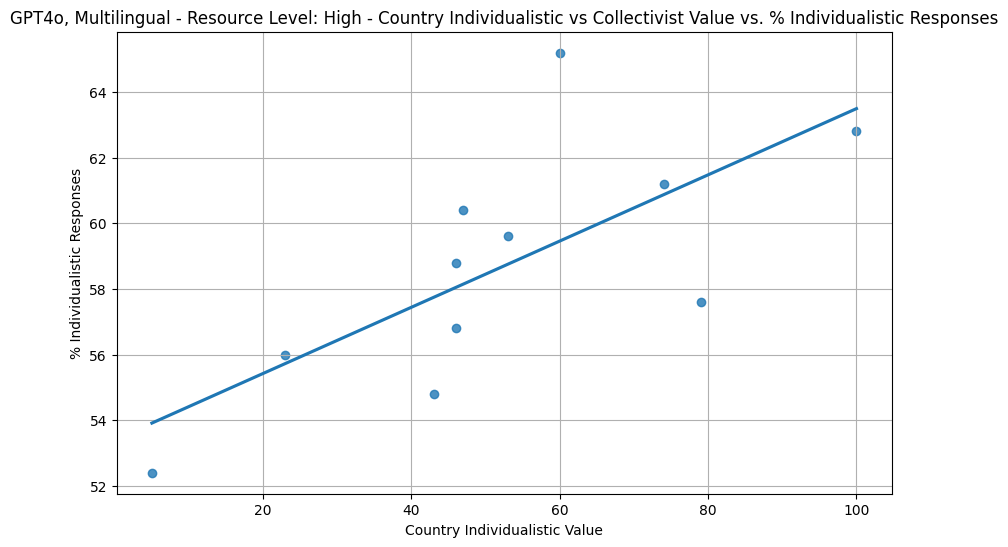
Figure 3: GPT4o adhering well to individualism vs. collectivist value for high-resource languages.
Conclusion
The findings underscore the need for LLMs to improve in cultural sensitivity to provide globally applicable advice. While current models reveal basic understanding, they often fall short in nuanced cultural engagements. Future work should focus on sanitizing and diversifying training data, integrating cultural checkpoints, and adopting frameworks like RAG for improving multicultural value alignment. The overarching goal is to refine AI systems to better reflect and respect cultural diversity in global contexts.

