- The paper introduces an NVMe-based checkpointing system that accelerates deep learning model state saving with up to 116x speed improvements.
- It utilizes parallel write strategies across data parallel ranks to optimize I/O performance and minimize training interruptions.
- The overlapping checkpoint mechanism hides I/O latency by pipelining writes with subsequent model computations, reducing overall training delays.
FastPersist: Accelerating Model Checkpointing in Deep Learning
FastPersist addresses the critical issue of model checkpointing in Deep Learning (DL), optimizing it for fault tolerance and enhanced performance by utilizing innovative techniques that leverage Non-Volatile Memory Express (NVMe) SSDs. This paper introduces three primary strategies that significantly accelerate the checkpointing process, ensuring minimal impact on training efficiency.
Introduction
Deep Learning models have grown exponentially in size, requiring extensive computational resources and increased fault tolerance mechanics such as checkpointing to ensure resilience during training on large-scale systems. Checkpoints are essential for preserving model states during training but incur significant overheads that can hamper performance. In large-scale data parallelism, this overhead escalates, leading to bottlenecks. Previous efforts lack focus on I/O optimization during checkpointing, posing challenges as models keep scaling.
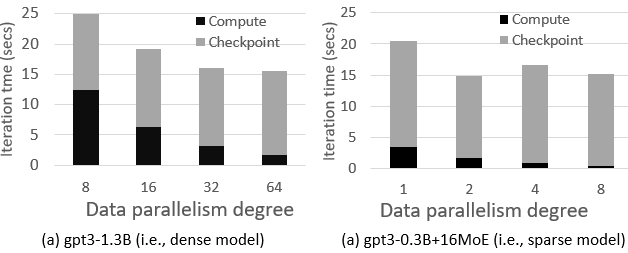
Figure 1: Impact of data parallelism on training time of (a) dense and (b) sparse models, on up to 128 V100-32GB GPUs.
FastPersist Design
FastPersist introduces an innovative system leveraging NVMe optimizations, efficient write parallelism, and overlap techniques to cut down checkpointing latency:
- NVMe Optimizations: FastPersist optimizes NVMe SSD capabilities to reduce the latency of disk writes from GPU memory. With advanced I/O libraries like
libaio and io_uring, this approach significantly enhances disk writing speeds by ensuring data alignment and using double-buffering techniques.
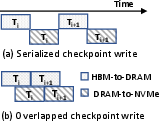
Figure 2: Writing tensors from accelerator memory to NVMe, illustrating double buffering advantage.
- Write Parallelism: FastPersist exploits data parallelism (DP) to distribute checkpoint writing tasks across multiple DP ranks, thereby utilizing the full I/O capacity of large-scale systems. This parallelization ensures higher bandwidth utilization by decentralized write operations, avoiding performance bottlenecks associated with single-node writing.
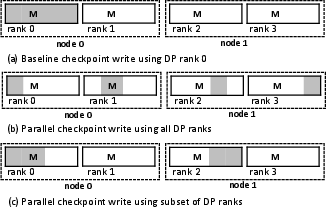
Figure 3: FastPersist's parallel write strategy across DP ranks, optimizing the use of I/O resources.
- Overlapping Checkpointing: To further decrease training stalls, FastPersist decouples checkpoint writing tasks to overlap with independent computations of subsequent iterations. By understanding model update dependencies correctly, FastPersist ensures these I/O operations are efficiently hidden within training cycles.
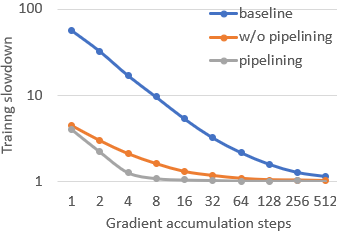
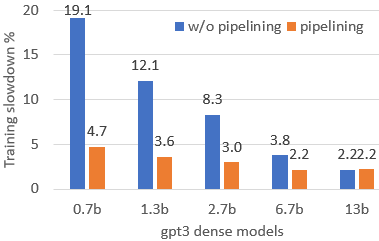
Figure 4: FastPersist's pipelining performance, showing the effectively minimized impact on iteration times.
Evaluation
Micro Benchmark
Experiments demonstrate FastPersist's superior checkpointing throughput over traditional methods, displaying bandwidth improvements of 1.8x to 6.6x on single GPU tests and near-linear scalability across multi-node environments.
For dense and Mixture of Experts (MoE) models, FastPersist achieves up to 116x faster checkpointing speed compared to PyTorch's torch.save(), with a significant reduction in training downtimes. The impact is profound in systems with higher DP degrees where bandwidth utilization is maximized.
Training Scalability
Simulations project impressive training speed gains for large models like GPT-3 scaling beyond 128 DP degrees, showcasing FastPersist's capability to handle extreme scale DL workloads with minimal iterative slowdown.
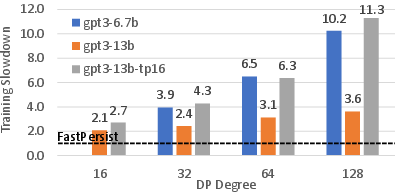
Figure 5: Projecting FastPersist's efficiency at scaled DP levels illustrating substantial performance benefits.
Conclusion
FastPersist demonstrates substantial advancements in DL model checkpointing through the adept use of NVMe optimizations and intelligent checkpoint management, facilitating near-zero overhead frequent checkpointing. These breakthroughs allow for efficient training of large-scale DL models, ensuring robustness against system failures and interruptions while maintaining high training throughput.
The study emphasizes its applicability across various AI domains, including natural language processing and recommendation systems, presenting FastPersist as a pivotal tool for upcoming extensive DL models integrated within enterprise and research arenas.

