- The paper introduces SpatialBot, a vision-language model that integrates RGB and depth images to boost spatial reasoning for embodied AI tasks.
- It presents the novel SpatialQA and SpatialQA-E datasets that structure multi-level VQA tasks to improve depth-based spatial understanding.
- Empirical results show that SpatialBot achieves superior precision in robotic manipulation and navigation compared to baseline models.
SpatialBot: Precise Spatial Understanding with Vision LLMs
Introduction
The paper "SpatialBot: Precise Spatial Understanding with Vision LLMs" introduces SpatialBot, a Vision LLM (VLM) specifically developed to enhance spatial understanding capabilities utilizing both RGB and depth images. By overcoming the limitations of popular VLMs that are predominantly trained on RGB data alone, this work leverages depth perception to address embodied AI tasks such as robotic manipulation and navigation. A novel dataset, SpatialQA, is presented to facilitate the training of VLMs by incorporating multi-level depth-related Visual Question Answering (VQA) tasks. Additionally, the SpatialQA-E dataset is introduced to enable these models to engage in complex embodiment tasks, ultimately verified through the deployment of SpatialBot on robotic systems.
Spatial Understanding Challenges
Current VLMs face significant hurdles in spatial understanding due to their confinement to 2D RGB data, which inherently lacks depth information crucial for tasks requiring spatial awareness. The paper identifies three main challenges: the absence of depth image training, the lack of depth-specific training datasets, and the scale inconsistencies between indoor and outdoor depth data. To address these, SpatialBot is trained with depth images to enhance spatial comprehension, enabling precise robotic manipulation (Figure 1).

Figure 1: SpatialBot has better spatial understanding ability than GPT-4o. SpatialBot first obtains depth information of target objects from the depth map, and then judgments are made.
SpatialQA Dataset and Training Pipeline
SpatialQA, a comprehensive RGB-D VQA dataset, is pivotal for training SpatialBot. It facilitates the model's understanding of depth images and their alignment with RGB inputs for enhanced spatial task execution (Figure 2).
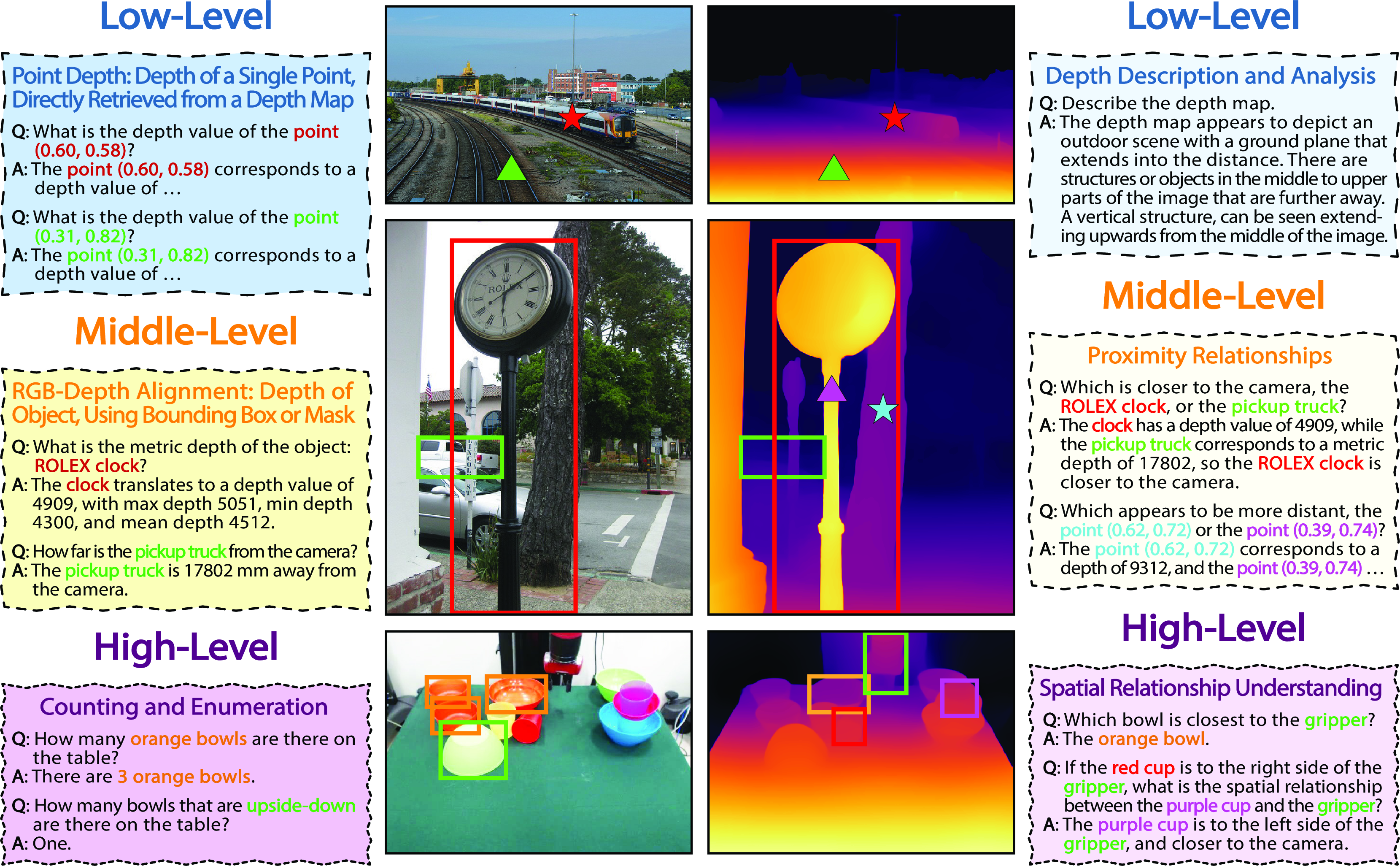
Figure 2: The proposed SpatialQA dataset consists of basic, middle, and high-level VQAs, aiming to help VLMs understand depth.
The dataset is structured into three levels of VQA tasks:
- Low-Level Tasks: These tasks involve basic depth perception, encouraging SpatialBot to query and comprehend depth values directly from depth images.
- Middle-Level Tasks: Focused on intermediate spatial reasoning, including object detection, proximity assessments, and regions' depth description.
- High-Level Tasks: These tasks require sophisticated depth-based reasoning, such as spatial relationship comprehension and manipulation strategies.
SpatialBot Architecture
SpatialBot is designed with a modular architecture that allows it to process RGB and optional depth images, with the capability to invoke a Depth API for precise information retrieval (Figure 3).
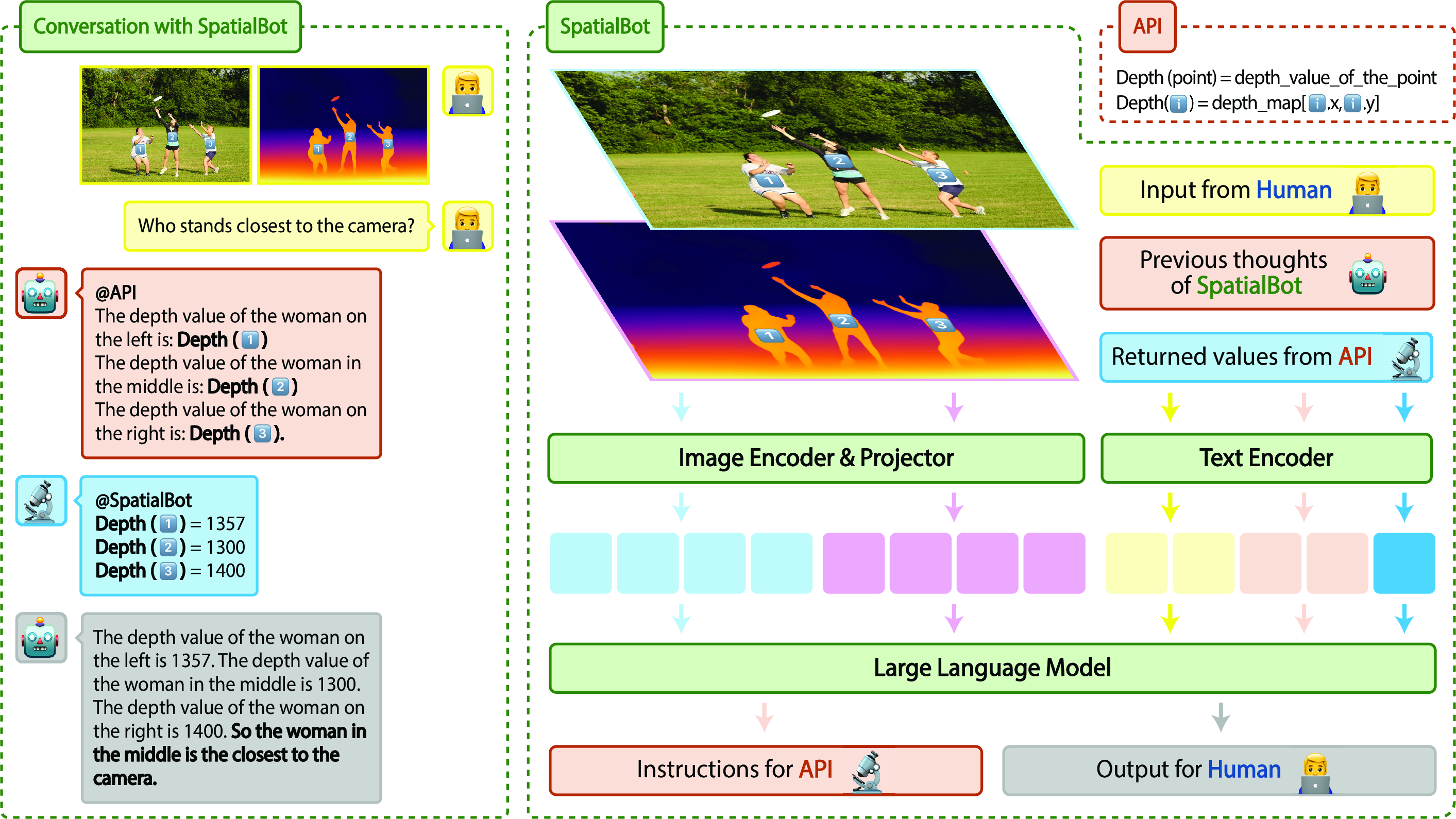
Figure 3: The architecture of SpatialBot processes RGB and depth images, with an optional Depth API for accuracy.
SpatialQA-E for Embodiment Tasks
SpatialQA-E extends SpatialBot's spatial reasoning to embodied AI domains. It comprises 2000 episodes focused on robotic manipulation tasks that integrate spatial relationships within language instructions (Figure 4).
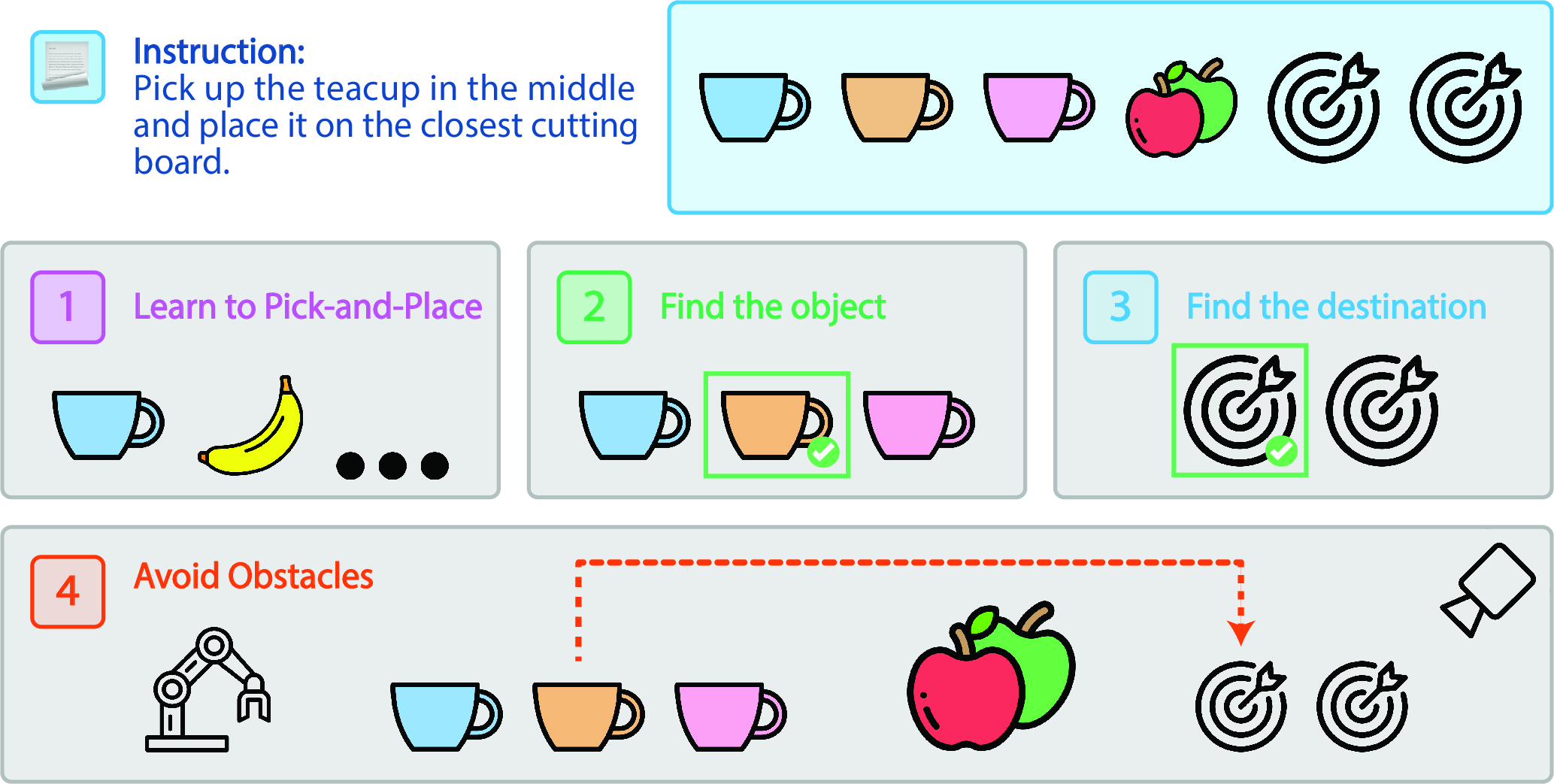
Figure 4: SpatialQA-E involves spatial relationships in robot manipulation.
The dataset encapsulates several typologies, including positional instructions and tasks necessitating discerning real from printed objects via depth clues (Figure 5).
Figure 5: SpatialQA-E demonstration with steps to identify real versus printed objects using depth maps.
Empirical Results
Experiments demonstrate SpatialBot's superiority in spatial understanding tasks compared to baseline models. The deployment of SpatialBot in embodiment tasks showcases its ability to leverage depth comprehension for effective robotic manipulation, enhancing task execution accuracy (Figure 6).
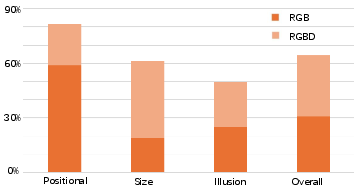
Figure 6: SpatialBot success rate in pick-and-place tasks utilizing RGB-D inputs.
SpatialBench, a comprehensive evaluation tool, further confirms SpatialBot's proficiency across various spatial reasoning tasks.
Conclusion
SpatialBot presents significant advancements in spatial understanding within VLMs by incorporating depth information into visual and linguistic model architectures. Through comprehensive datasets and tasks designed to enhance spatial reasoning, SpatialBot demonstrates state-of-the-art performance in general VLM benchmarks and practical embodiment scenarios, thus paving the way for future developments in AI-driven spatial cognition and robotics.