- The paper introduces AutoIF, a fully automated self-play framework that generates reliable instruction-following datasets, leading to improved LLM performance.
- It employs execution feedback and multiple verification steps, including back-translation and cross-verification, to ensure superior data quality for both SFT and RLHF.
- Evaluations on Qwen2 and LLaMA3 models show significant gains in instruction accuracy, demonstrating scalability, robustness, and efficient data usage.
Self-play with Execution Feedback: Improving Instruction-following Capabilities of LLMs
Introduction
The paper introduces AutoIF, a scalable and automated framework for generating high-quality instruction-following data for LLMs without manual annotation. AutoIF leverages self-play and execution feedback, transforming the validation of instruction-following data into a code verification problem. The system automatically generates instructions, corresponding verification code, and unit tests, then uses execution feedback-based rejection sampling to produce data for both supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) paradigms. The approach is evaluated on top open-source LLMs (Qwen2, LLaMA3) and demonstrates substantial improvements in instruction-following benchmarks, including IFEval and FollowBench.
AutoIF Framework
AutoIF consists of two main stages: instruction augmentation/verification and query augmentation/verification. The process is designed to be fully automated and scalable, relying on LLMs for all data generation and validation steps.
Instruction Augmentation and Verification
- Seed Instruction Construction: Begin with a small set of hand-written atomic instructions.
- Self-Instruct: Use LLMs to rewrite and augment seed instructions, expanding the instruction set.
- Automated Quality Cross Verification: For each instruction, LLMs generate verification functions and test cases. Python executors validate code compilation and correctness, filtering out low-quality samples.
- Back-translation Verification: Verification functions are back-translated into instructions using LLMs. Natural language inference (NLI) models ensure semantic consistency between original and back-translated instructions, discarding contradictory pairs.
Query Augmentation and Verification
- Query Reforming and Augmentation: For each verified instruction, authentic queries are sampled from ShareGPT and further augmented by LLMs.
- Instruction-following Verification: Verification functions assess whether generated responses adhere to instruction constraints.
- Query Quality Verification: LLMs assign matching scores between instruction, query, and response. Samples with scores below a threshold are filtered out, ensuring high-quality training data.
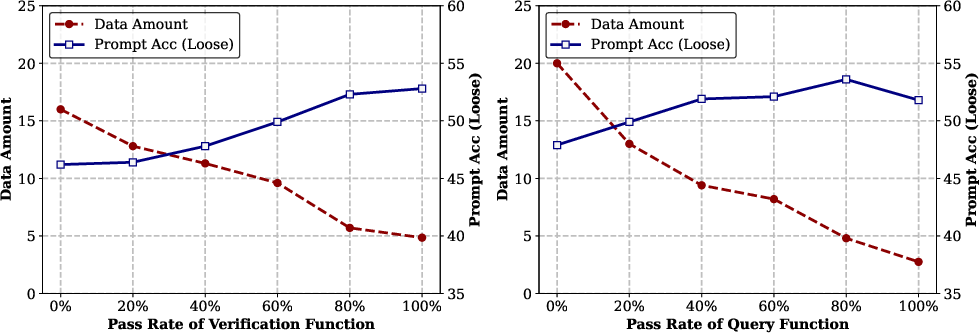
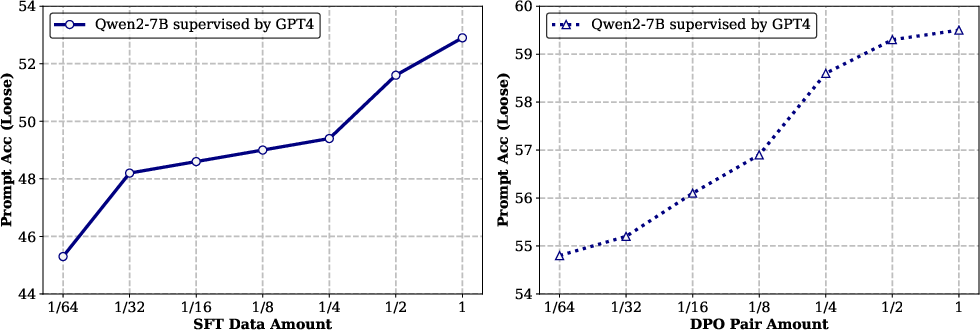
Figure 1: The left two figures illustrate the quality ablation studies on instructions and queries, whereas the right two figures present the scaling analysis of SFT data and DPO pairs.
Training Strategies
AutoIF supports multiple training paradigms:
- Supervised Fine-tuning (SFT): Standard cross-entropy loss on (instruction, query, response) triples.
- Offline DPO: Pairwise preference data is mined from verification results, enabling Direct Preference Optimization (DPO) after SFT.
- Iterative Online DPO: On-policy training with self-sampled responses and verification feedback, iteratively improving instruction-following capabilities.
Experimental Results
AutoIF is evaluated on Qwen2 and LLaMA3 models across both strong-to-weak distillation and self-alignment settings. The main findings are:
- Instruction-following Performance: AutoIF yields significant improvements in IFEval and FollowBench benchmarks. Qwen2-72B and LLaMA3-70B achieve loose instruction accuracy rates of 88.0% and 90.4%, respectively, surpassing previous open-source models and even proprietary baselines in some metrics.
- On-policy vs. Off-policy: Online DPO (on-policy) consistently outperforms offline DPO, confirming the efficacy of iterative execution feedback for targeted model improvement.
- Scaling Effects: Larger models benefit more from AutoIF, with greater absolute improvements in instruction-following metrics.
- Generalization: AutoIF preserves or slightly improves general abilities (MMLU, C-Eval), mathematical reasoning (GSM8k), and coding (HumanEval), indicating no trade-off between instruction-following and other capabilities.
Ablation and Analysis
- Supervision Model Strength: Using a stronger supervision model (e.g., GPT-4) for data synthesis further boosts alignment, with >15% gains in some metrics.
- Quality Control: Ablation studies show that removing any quality filtering step (cross-verification, back-translation, query verification) degrades performance, with cross-verification being most critical.
- Data Quality vs. Quantity: Increasing the pass rate threshold for verification functions improves model performance but reduces data quantity, revealing a trade-off.
- Scaling Analysis: Even with 1/64 of the AutoIF-generated data, models achieve strong performance, demonstrating high data efficiency.
- Contamination Analysis: AutoIF-generated datasets exhibit lower contamination rates than ShareGPT, ensuring robust evaluation.
Implementation Details
- Hardware: Training conducted on NVIDIA A100 and H800 GPUs, with Qwen2-7B/LLaMA3-8B on 8 A100s and Qwen2-72B/LLaMA3-70B on 64 H800s.
- Optimization: DeepSpeed ZeRO Stage 3 and Flash-Attention 2 are used for efficient large-scale training.
- Hyperparameters: SFT uses a learning rate of 7e-6, batch size 128 (small models) or 512 (large models), 3 epochs, bf16 precision, and context length up to 8192. DPO uses a learning rate of 5e-7, batch size 64, sigmoid loss with beta=0.3, 2 epochs, and context length 4096.
Practical Implications
AutoIF enables fully automated, scalable, and reliable construction of instruction-following datasets for LLM alignment. The framework is model-agnostic and can be applied to any LLM with sufficient code generation and reasoning capabilities. By leveraging execution feedback, AutoIF circumvents the limitations of manual annotation and behavior imitation, producing high-quality, verifiable supervision signals. The open-sourcing of AutoIF datasets facilitates reproducibility and further research in instruction-following alignment.
Limitations and Future Directions
The current focus is on atomic, verifiable instructions. Extending AutoIF to handle compositional and cross-instructions—by combining multiple atomic constraints and automating their verification—remains an open challenge. Further research should explore scaling AutoIF to more complex instruction types and integrating advanced semantic verification techniques.
Conclusion
AutoIF represents a robust, scalable approach for enhancing instruction-following capabilities in LLMs via self-play and execution feedback. The method achieves state-of-the-art results on open benchmarks, preserves general model abilities, and provides a reproducible pipeline for automated alignment. Future work should address compositional instruction synthesis and further improve the reliability and coverage of automated verification.