- The paper introduces GraphSAM, which approximates SAM's perturbation gradient to significantly reduce computational overhead.
- It maintains model generalization by constraining the perturbation within the expected loss landscape while preserving SAM's performance.
- Extensive tests show up to 155.4% training speed improvements across six benchmark datasets in molecular property prediction.
Introduction
The paper "Efficient Sharpness-Aware Minimization for Molecular Graph Transformer Models" presents GraphSAM, a novel optimization algorithm designed to address the computational inefficiency issues inherent in Sharpness-Aware Minimization (SAM) when applied to molecular graph transformer models. SAM, although effective in minimizing sharp local minima and improving generalization, suffers from increased time overhead due to its requirement for dual gradient computations per optimization step. This paper proposes GraphSAM to enhance computational efficiency while preserving the superior generalization capabilities of SAM.
Sharp Local Minima and SAM
Transformers for molecular property prediction often converge to sharp local minima due to their over-parameterization and absence of hand-crafted features. This leads to substantial generalization errors. SAM combats this by perturbing model weights to maximize sharpness within a defined neighborhood, necessitating computation of both adversarial (perturbation) and updating gradients. While effective, this approach yields a doubled computational cost, motivating the need for a more efficient strategy.
GraphSAM: Design and Functionality
GraphSAM introduces an efficient mechanism to approximate the perturbation gradient using the previously computed updating gradient. The algorithm performs the following key operations:
- Gradient Approximation: GraphSAM uses the updating gradient from the prior step to approximate the perturbation gradient, reducing computational redundancy.
- Loss Landscape Constraint: It ensures that the approximated perturbation does not deviate significantly from the SAM’s expected loss landscape, thereby maintaining model generalization.
GraphSAM effectively re-anchors perturbation gradients intermittently, rolling over the computationally expensive SAM to provide comparable performances with conventional optimizers.
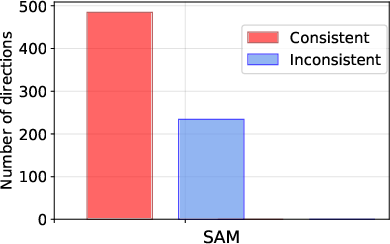
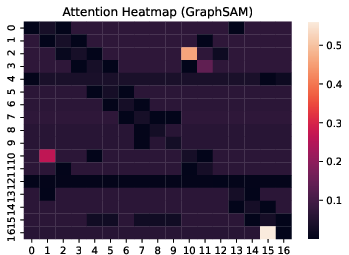
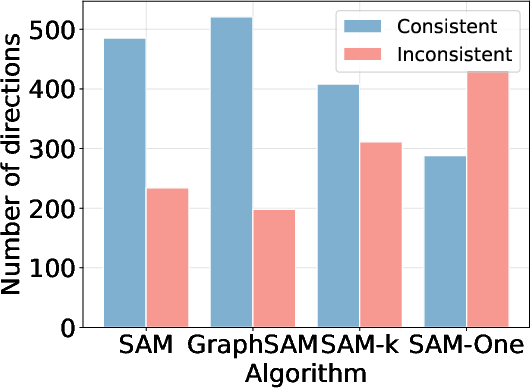
Figure 1: Illustration on the observation of gradient variation during training on GROVER with three datasets.
Extensive experiments were conducted on six benchmark datasets, including both classification and regression tasks. The evaluation demonstrated the superiority of GraphSAM over baseline models that utilize only the base optimizer, such as Adam. Notably, GraphSAM matched SAM in generalization performance while achieving significant training speed improvements—up to a 155.4% increase compared to SAM.
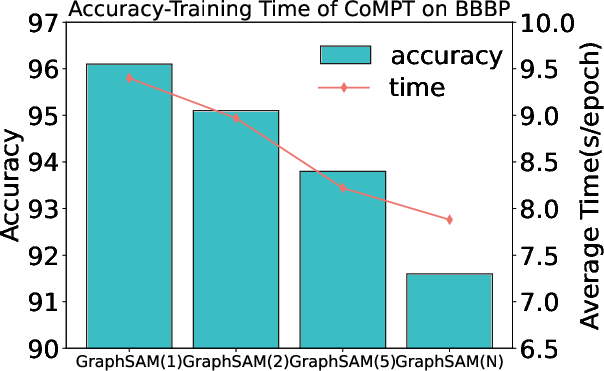
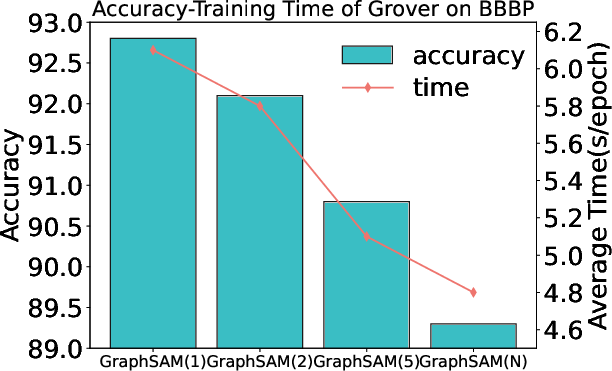
Figure 2: Accuracy-Training Time of different models for GraphSAM-K. Average Time (s/epoch) represents the average time consumed for each epoch.
Implementation Considerations
When implementing GraphSAM, researchers should consider:
- Hyperparameters: The smoothing parameter β, initial ρ, scheduler’s modification scale γ, and ρ's update rate λ need careful tuning for optimal performance.
- Computational Concerns: While GraphSAM mitigates double overhead, the requirement of re-anchoring necessitates moderately increased computation at each epoch start, balancing efficiency with accuracy.
Conclusion
GraphSAM effectively diminishes the computational inefficiency of SAM without compromising its advantages in smoothing sharp local minima. By leveraging gradient approximation, it stands as a significant advancement for deploying graph transformer models in molecular property predictions. Further investigations could explore its adaptability across different neural architectures and optimization frameworks, potentially extending its applicability to broader AI applications.