Holmes-VAD: Towards Unbiased and Explainable Video Anomaly Detection via Multi-modal LLM
Abstract: Towards open-ended Video Anomaly Detection (VAD), existing methods often exhibit biased detection when faced with challenging or unseen events and lack interpretability. To address these drawbacks, we propose Holmes-VAD, a novel framework that leverages precise temporal supervision and rich multimodal instructions to enable accurate anomaly localization and comprehensive explanations. Firstly, towards unbiased and explainable VAD system, we construct the first large-scale multimodal VAD instruction-tuning benchmark, i.e., VAD-Instruct50k. This dataset is created using a carefully designed semi-automatic labeling paradigm. Efficient single-frame annotations are applied to the collected untrimmed videos, which are then synthesized into high-quality analyses of both abnormal and normal video clips using a robust off-the-shelf video captioner and a LLM. Building upon the VAD-Instruct50k dataset, we develop a customized solution for interpretable video anomaly detection. We train a lightweight temporal sampler to select frames with high anomaly response and fine-tune a multimodal LLM to generate explanatory content. Extensive experimental results validate the generality and interpretability of the proposed Holmes-VAD, establishing it as a novel interpretable technique for real-world video anomaly analysis. To support the community, our benchmark and model will be publicly available at https://holmesvad.github.io.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Holmes‑VAD, an AI system that watches long videos (like security footage) to spot unusual events and also explains what it saw and why it’s unusual. Think of it like a digital Sherlock Holmes: it doesn’t just point to something odd—it explains its reasoning.
What questions are they trying to answer?
The authors focus on two big problems in video anomaly detection:
- How can we reduce false alarms and find the exact moments when something unusual happens?
- How can we make the AI explain its decisions in clear language, instead of just giving a score or a yes/no answer?
How did they do it?
To make the system both accurate and explainable, they built a new dataset and trained a two-part model.
1) Building a better dataset: VAD‑Instruct50k
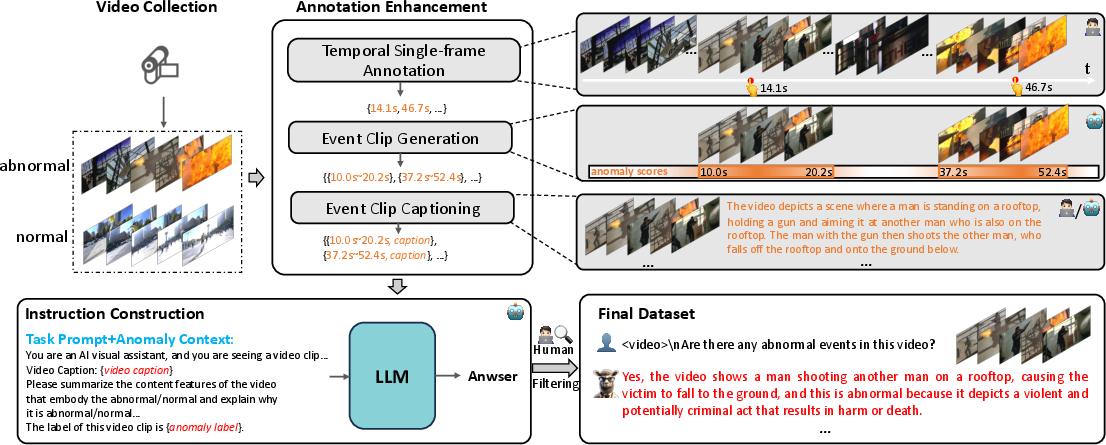
Labeling every frame in a long video is very expensive and slow. The authors created a smarter, semi‑automatic way to build training data.
- Single‑frame labels: For each unusual event, a human clicks on just one key frame (like pointing to the key moment in a highlight reel). This is much faster than labeling every frame.
- Event clips: Around each key frame, the system automatically creates short video clips that likely cover the full event (start to end).
- Captions and explanations: A video captioning model describes what’s happening in each clip, and a LLM turns those descriptions into clear questions-and-answers about what is unusual and why. Humans then review and clean the results.
The final dataset, called VAD‑Instruct50k, includes:
- Long, untrimmed videos with single‑frame markers for unusual events
- Short clips labeled as normal or abnormal
- Natural‑language explanations about what happened and why it’s unusual
2) Teaching the AI to both detect and explain
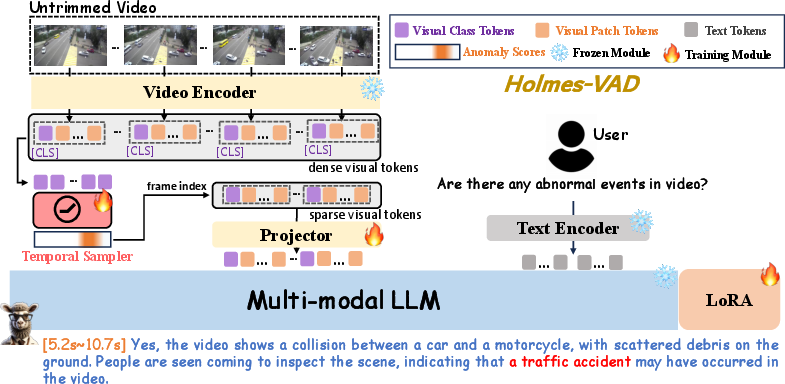
Holmes‑VAD has three main parts:
- Video Encoder: A vision model turns video frames into features the AI can understand.
- Temporal Sampler: A lightweight detector that scans all frames and scores how “suspicious” each one is. It then selects only the most important frames. Think of this as making a highlight reel of the moments that matter, so the AI doesn’t waste time on boring parts.
- Multimodal LLM: A LLM that can understand visuals and text together. It reads the selected frames plus a user’s question (like “Is there anything unusual here?”) and writes an explanation in plain language.
How it works end‑to‑end:
- The Temporal Sampler quickly flags likely unusual frames in the long video.
- Only those frames go to the LLM (this saves time and focuses attention).
- The LLM answers questions like “What happened?” and “Why is this unusual?” in clear text.
The LLM is fine‑tuned (lightly adjusted) using the VAD‑Instruct50k instructions so it learns the style and content of good explanations for anomalies in security videos.
What did they find, and why is it important?
On two large, well‑known test sets (UCF‑Crime and XD‑Violence), Holmes‑VAD:
- Detected anomalies more accurately than previous methods.
- XD‑Violence: Average Precision ≈ 90.7%
- UCF‑Crime: AUC ≈ 89.5%
- Gave understandable explanations that people preferred in a user study. When the LLM was fine‑tuned on the new dataset, volunteers rated its judgments and explanations as much better.
- Ran efficiently on long videos. The Temporal Sampler was both faster and more accurate than simply sampling frames evenly (it cut the average processing time per video by a lot while improving accuracy).
Why this matters:
- Fewer false alarms and better timing: The system is less biased and better at pinpointing exactly when the unusual thing happens.
- Trust and transparency: It doesn’t just say “abnormal”—it explains what and why, which helps humans verify and act on the results.
What could this change in the real world?
- Safer public spaces: Security teams can monitor long videos more reliably and understand alerts quickly.
- Better tools for analysts: Explanations help people decide what to do next, instead of inspecting footage frame by frame.
- A foundation for future systems: The released dataset and model can help others build even better explainable video AI.
The authors also note two next steps:
- Improve the quality of automatically generated captions and explanations.
- Help the LLM understand very long videos even better, without losing detail.
Overall, Holmes‑VAD moves video anomaly detection from “just detect” to “detect and explain,” making AI results more accurate, efficient, and trustworthy.
Collections
Sign up for free to add this paper to one or more collections.

