Meta Reasoning for Large Language Models
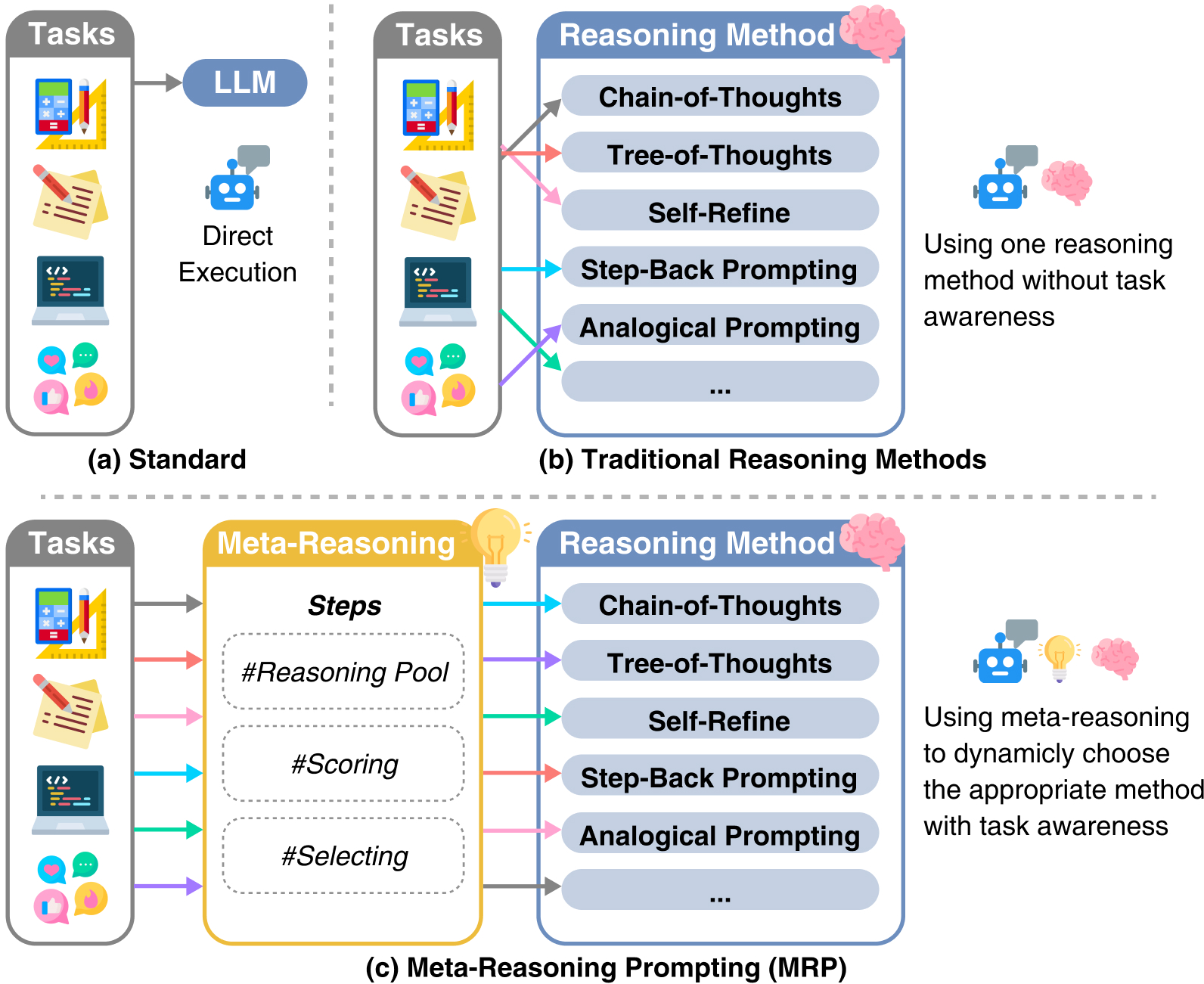
Abstract: We introduce Meta-Reasoning Prompting (MRP), a novel and efficient system prompting method for LLMs inspired by human meta-reasoning. Traditional in-context learning-based reasoning techniques, such as Tree-of-Thoughts, show promise but lack consistent state-of-the-art performance across diverse tasks due to their specialized nature. MRP addresses this limitation by guiding LLMs to dynamically select and apply different reasoning methods based on the specific requirements of each task, optimizing both performance and computational efficiency. With MRP, LLM reasoning operates in two phases. Initially, the LLM identifies the most appropriate reasoning method using task input cues and objective descriptions of available methods. Subsequently, it applies the chosen method to complete the task. This dynamic strategy mirrors human meta-reasoning, allowing the model to excel in a wide range of problem domains. We evaluate the effectiveness of MRP through comprehensive benchmarks. The results demonstrate that MRP achieves or approaches state-of-the-art performance across diverse tasks. MRP represents a significant advancement in enabling LLMs to identify cognitive challenges across problems and leverage benefits across different reasoning approaches, enhancing their ability to handle diverse and complex problem domains efficiently. Every LLM deserves a Meta-Reasoning Prompting to unlock its full potential and ensure adaptability in an ever-evolving landscape of challenges and applications.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, intended to guide future research.
- Scoring definition and calibration: The paper defines but does not specify how a numeric score is elicited from text, what scale is used, how scores are normalized/calibrated across methods, or how ties are broken.
- Sampling/control settings: Decoding parameters (e.g., temperature, top‑p, randomness) for both the scoring and execution phases are unspecified, leaving selection stability and reproducibility unclear.
- Selection reliability: There is no metric or analysis for “selection accuracy” (i.e., how often MRP picks the oracle-best method for a given instance), nor a confusion matrix of misrouted cases.
- Error taxonomy quantification: While GPT‑3.5 errors are categorized (Scoring Error, Self‑opinion, Factual Error, Reasoning Error), their frequencies, causes, and impacts are not quantified, and no mitigation strategies are evaluated.
- Cost–performance trade‑offs: Claims of efficiency are not supported with measurements of token usage, latency, or dollar cost per task; the overhead of scoring n methods plus execution is not benchmarked or compared to single‑method baselines.
- Pool composition sensitivity: No ablation on the reasoning pool (adding/removing methods, weaker/stronger variants, paraphrased descriptions) to quantify MRP’s sensitivity to pool size, redundancy, or method overlap.
- Description quality and bias: Method descriptions are “extracted from abstracts” without standardization; the effect of description length, wording style, or bias on selection and performance is untested.
- Prompt robustness: No study of robustness to paraphrasing of the meta‑reasoning prompt or the method prompts , nor to adversarially crafted inputs that could manipulate routing.
- Generalization to unseen methods/tasks: It is unclear how MRP behaves when confronted with tasks outside the coverage of the current pool, or when new methods are introduced with sparse descriptions.
- None-of-the-above option: MRP must pick one method; there is no “decline to route” or fallback option when all are low, nor a mechanism to propose a new composite strategy.
- Mid-course adaptation: The selection is one-shot; there is no mechanism to switch methods mid‑reasoning, interleave methods, or perform dynamic re‑planning when partial progress fails.
- Ensemble/ranking strategies: Although Top‑K/Top‑P ensembling is mentioned as future work, there is no empirical comparison of alternative selection schemes (pairwise tournaments, Borda count, majority voting across methods).
- Cost-aware routing: MRP does not incorporate method-specific costs (compute, latency) into selection; no objective balances accuracy against cost or time.
- Statistical rigor: Results lack confidence intervals, statistical significance testing, or power analysis, particularly important given small sampled subsets for several benchmarks.
- Evaluation metric clarity: For tasks like creative writing and code readability, the exact scoring procedures, evaluators (automatic vs human/LLM-judge), and reliability checks are not described.
- Dataset sampling bias: Several benchmarks are evaluated on small, randomly sampled subsets (100–300 items) without reporting sampling protocol, seeds, or representativeness analyses.
- Cross-model generalization: Only GPT‑4 and GPT‑3.5 are tested; performance and behaviors on open-source models (e.g., Llama, Mistral) and other closed-source models remain unknown.
- Multilingual/generalization across languages: All experiments appear to be in English; the effectiveness of MRP in multilingual settings is unexplored.
- Domain breadth: Coding evaluation is limited to readability; impacts on debugging, synthesis, code repair, and constraint satisfaction tasks are not assessed.
- Long‑horizon/interactive tasks: MRP is not evaluated in multi-turn, tool-augmented, or environment-interactive settings where planning and re-routing are critical.
- Interpretability of routing: The model’s rationale for selecting a method is not collected or evaluated; faithfulness and usefulness of selection explanations are unknown.
- Safety and bias considerations: Routing to methods like multi-persona collaborations or perspective-taking may affect safety/bias; no safety, fairness, or content moderation assessment is reported.
- Reusability and caching: No mechanism is proposed for caching/learning routing policies over time (e.g., per-task heuristics) to amortize selection cost across similar inputs.
- Theoretical grounding: There is no formal justification that as produced by an LLM corresponds to expected task success; calibration theory and uncertainty estimation are absent.
- Comparison to learned routers: MRP is not empirically compared to supervised/reinforcement-learned routing systems (e.g., Tryage, benchmark-based routers), mixture-of-agents, or meta-buffers under a common cost/accuracy framework.
- Oracle/upper-bound analysis: No oracle analysis (best-per-instance method) is provided to quantify the headroom for routing and the current gap to optimal method assignment.
- Failure mode diagnostics: There is no instance-level analysis linking input characteristics to misrouting (e.g., ambiguity, compositional depth) to guide targeted improvements.
- Resource constraints and reproducibility: Full text prompts are embedded as figures, not released as machine-readable artifacts; code, seeds, and logs are not provided for replicability.
- Context-length and interference: Potential context interference from concatenating is not analyzed; the effects of prompt length and ordering on scoring are unknown.
- Tie-handling and instability: Tie-breaking rules, run-to-run variability in selections, and stability across multiple trials are not reported.
Collections
Sign up for free to add this paper to one or more collections.